正在加载图片...
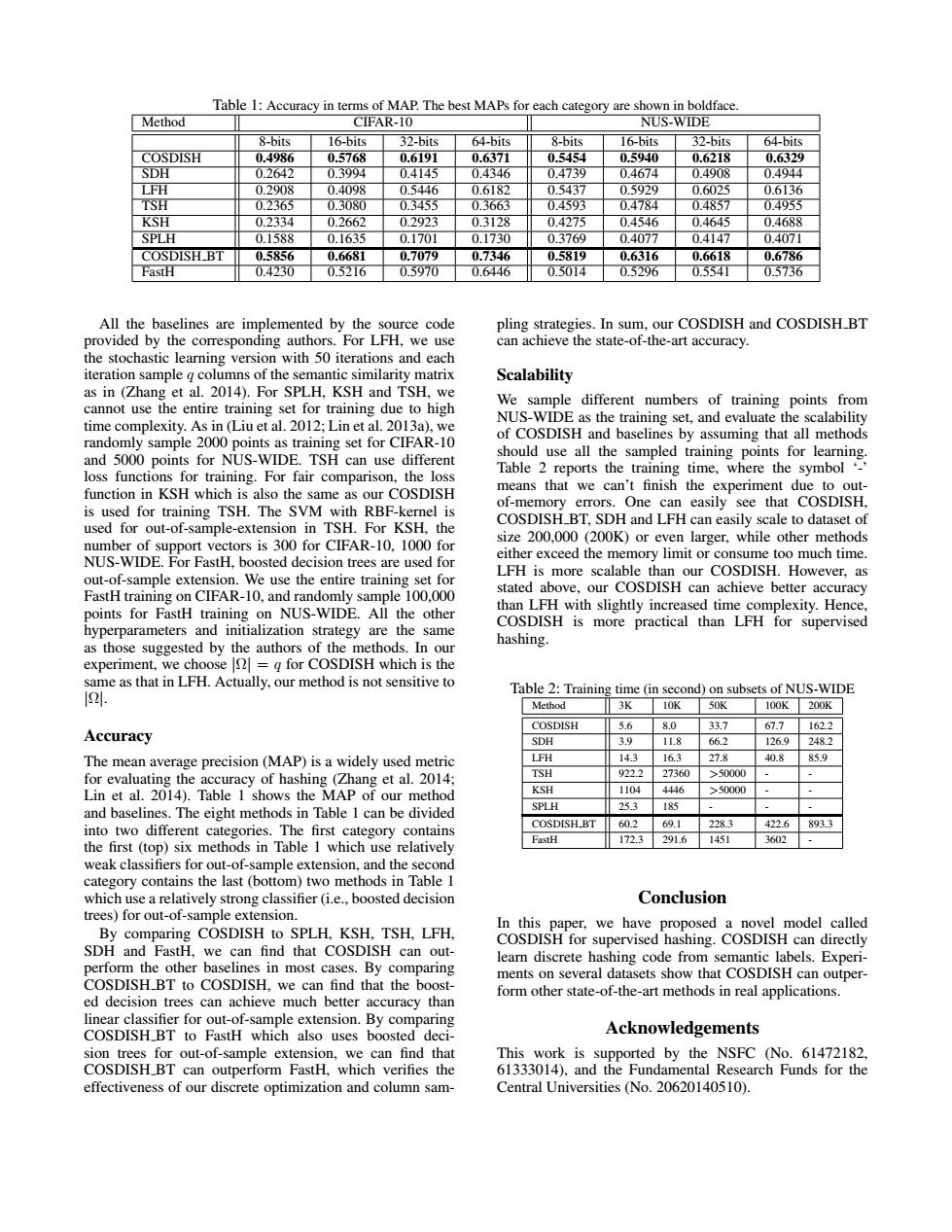
Table 1:Accuracy in terms of MAP.The best MAPs for each category are shown in boldface. Method CIFAR-10 NUS-WIDE 8-bits 16-bits 32-bits 64-bits 8-bits 16-bits 32-bits 64-bits COSDISH 0.4986 0.5768 0.6191 0.6371 0.5454 0.5940 0.6218 0.6329 SDH 0.2642 0.3994 0.4145 0.4346 0.4739 0.4674 0.4908 0.4944 LFH 0.2908 0.4098 0.5446 0.6182 0.5437 0.5929 0.6025 0.6136 TSH 0.2365 0.3080 0.3455 0.3663 0.4593 0.4784 0.4857 0.4955 KSH 0.2334 0.2662 0.2923 0.3128 0.4275 0.4546 0.4645 0.4688 SPLH 0.1588 0.1635 0.1701 0.1730 0.3769 0.4077 0.4147 0.4071 COSDISH BT 0.5856 0.6681 0.7079 0.7346 0.5819 0.6316 0.6618 0.6786 FastH 0.4230 0.5216 0.5970 0.6446 0.5014 0.5296 0.5541 0.5736 All the baselines are implemented by the source code pling strategies.In sum,our COSDISH and COSDISH_BT provided by the corresponding authors.For LFH,we use can achieve the state-of-the-art accuracy. the stochastic learning version with 50 iterations and each iteration sample g columns of the semantic similarity matrix Scalability as in (Zhang et al.2014).For SPLH,KSH and TSH,we cannot use the entire training set for training due to high We sample different numbers of training points from time complexity.As in (Liu et al.2012;Lin et al.2013a),we NUS-WIDE as the training set,and evaluate the scalability randomly sample 2000 points as training set for CIFAR-10 of COSDISH and baselines by assuming that all methods and 5000 points for NUS-WIDE.TSH can use different should use all the sampled training points for learning. loss functions for training.For fair comparison,the loss Table 2 reports the training time,where the symbol function in KSH which is also the same as our COSDISH means that we can't finish the experiment due to out- is used for training TSH.The SVM with RBF-kernel is of-memory errors.One can easily see that COSDISH, used for out-of-sample-extension in TSH.For KSH,the COSDISH_BT,SDH and LFH can easily scale to dataset of number of support vectors is 300 for CIFAR-10,1000 for size 200,000(200K)or even larger,while other methods NUS-WIDE.For FastH,boosted decision trees are used for either exceed the memory limit or consume too much time. out-of-sample extension.We use the entire training set for LFH is more scalable than our COSDISH.However,as FastH training on CIFAR-10,and randomly sample 100.000 stated above,our COSDISH can achieve better accuracy points for FastH training on NUS-WIDE.All the other than LFH with slightly increased time complexity.Hence COSDISH is more practical than LFH for supervised hyperparameters and initialization strategy are the same as those suggested by the authors of the methods.In our hashing. experiment,we choose=g for COSDISH which is the same as that in LFH.Actually,our method is not sensitive to I24 Table 2:Training time (in second)on subsets of NUS-WIDE Method 3K 10K 50K 100K 200K COSDISH 5.6 8.0 33.7 67.7 162.2 Accuracy SDH 3.9 11.8 66.2 126.9 248.2 The mean average precision(MAP)is a widely used metric LFH 14.3 16.3 27.8 40.8 85.9 for evaluating the accuracy of hashing (Zhang et al.2014; TSH 922.2 27360 >50000 Lin et al.2014).Table 1 shows the MAP of our method KSH 1104 4446 >50000 SPLH 25.3 and baselines.The eight methods in Table 1 can be divided 185 COSDISH BT 602 69.1 228.3 into two different categories.The first category contains 422.6 893.3 the first(top)six methods in Table 1 which use relatively astH 172.3 291.6 1451 3602 weak classifiers for out-of-sample extension,and the second category contains the last (bottom)two methods in Table 1 which use a relatively strong classifier (i.e..boosted decision Conclusion trees)for out-of-sample extension. In this paper,we have proposed a novel model called By comparing COSDISH to SPLH,KSH.TSH.LFH COSDISH for supervised hashing.COSDISH can directly SDH and FastH,we can find that COSDISH can out- learn discrete hashing code from semantic labels.Experi- perform the other baselines in most cases.By comparing ments on several datasets show that COSDISH can outper- COSDISH_BT to COSDISH,we can find that the boost- form other state-of-the-art methods in real applications. ed decision trees can achieve much better accuracy than linear classifier for out-of-sample extension.By comparing COSDISH_BT to FastH which also uses boosted deci- Acknowledgements sion trees for out-of-sample extension,we can find that This work is supported by the NSFC (No.61472182. COSDISH_BT can outperform FastH,which verifies the 61333014),and the Fundamental Research Funds for the effectiveness of our discrete optimization and column sam- Central Universities (No.20620140510).Table 1: Accuracy in terms of MAP. The best MAPs for each category are shown in boldface. Method CIFAR-10 NUS-WIDE 8-bits 16-bits 32-bits 64-bits 8-bits 16-bits 32-bits 64-bits COSDISH 0.4986 0.5768 0.6191 0.6371 0.5454 0.5940 0.6218 0.6329 SDH 0.2642 0.3994 0.4145 0.4346 0.4739 0.4674 0.4908 0.4944 LFH 0.2908 0.4098 0.5446 0.6182 0.5437 0.5929 0.6025 0.6136 TSH 0.2365 0.3080 0.3455 0.3663 0.4593 0.4784 0.4857 0.4955 KSH 0.2334 0.2662 0.2923 0.3128 0.4275 0.4546 0.4645 0.4688 SPLH 0.1588 0.1635 0.1701 0.1730 0.3769 0.4077 0.4147 0.4071 COSDISH BT 0.5856 0.6681 0.7079 0.7346 0.5819 0.6316 0.6618 0.6786 FastH 0.4230 0.5216 0.5970 0.6446 0.5014 0.5296 0.5541 0.5736 All the baselines are implemented by the source code provided by the corresponding authors. For LFH, we use the stochastic learning version with 50 iterations and each iteration sample q columns of the semantic similarity matrix as in (Zhang et al. 2014). For SPLH, KSH and TSH, we cannot use the entire training set for training due to high time complexity. As in (Liu et al. 2012; Lin et al. 2013a), we randomly sample 2000 points as training set for CIFAR-10 and 5000 points for NUS-WIDE. TSH can use different loss functions for training. For fair comparison, the loss function in KSH which is also the same as our COSDISH is used for training TSH. The SVM with RBF-kernel is used for out-of-sample-extension in TSH. For KSH, the number of support vectors is 300 for CIFAR-10, 1000 for NUS-WIDE. For FastH, boosted decision trees are used for out-of-sample extension. We use the entire training set for FastH training on CIFAR-10, and randomly sample 100,000 points for FastH training on NUS-WIDE. All the other hyperparameters and initialization strategy are the same as those suggested by the authors of the methods. In our experiment, we choose |Ω| = q for COSDISH which is the same as that in LFH. Actually, our method is not sensitive to |Ω|. Accuracy The mean average precision (MAP) is a widely used metric for evaluating the accuracy of hashing (Zhang et al. 2014; Lin et al. 2014). Table 1 shows the MAP of our method and baselines. The eight methods in Table 1 can be divided into two different categories. The first category contains the first (top) six methods in Table 1 which use relatively weak classifiers for out-of-sample extension, and the second category contains the last (bottom) two methods in Table 1 which use a relatively strong classifier (i.e., boosted decision trees) for out-of-sample extension. By comparing COSDISH to SPLH, KSH, TSH, LFH, SDH and FastH, we can find that COSDISH can outperform the other baselines in most cases. By comparing COSDISH BT to COSDISH, we can find that the boosted decision trees can achieve much better accuracy than linear classifier for out-of-sample extension. By comparing COSDISH BT to FastH which also uses boosted decision trees for out-of-sample extension, we can find that COSDISH BT can outperform FastH, which verifies the effectiveness of our discrete optimization and column sampling strategies. In sum, our COSDISH and COSDISH BT can achieve the state-of-the-art accuracy. Scalability We sample different numbers of training points from NUS-WIDE as the training set, and evaluate the scalability of COSDISH and baselines by assuming that all methods should use all the sampled training points for learning. Table 2 reports the training time, where the symbol ‘-’ means that we can’t finish the experiment due to outof-memory errors. One can easily see that COSDISH, COSDISH BT, SDH and LFH can easily scale to dataset of size 200,000 (200K) or even larger, while other methods either exceed the memory limit or consume too much time. LFH is more scalable than our COSDISH. However, as stated above, our COSDISH can achieve better accuracy than LFH with slightly increased time complexity. Hence, COSDISH is more practical than LFH for supervised hashing. Table 2: Training time (in second) on subsets of NUS-WIDE Method 3K 10K 50K 100K 200K COSDISH 5.6 8.0 33.7 67.7 162.2 SDH 3.9 11.8 66.2 126.9 248.2 LFH 14.3 16.3 27.8 40.8 85.9 TSH 922.2 27360 >50000 - - KSH 1104 4446 >50000 - - SPLH 25.3 185 - - - COSDISH BT 60.2 69.1 228.3 422.6 893.3 FastH 172.3 291.6 1451 3602 - Conclusion In this paper, we have proposed a novel model called COSDISH for supervised hashing. COSDISH can directly learn discrete hashing code from semantic labels. Experiments on several datasets show that COSDISH can outperform other state-of-the-art methods in real applications. Acknowledgements This work is supported by the NSFC (No. 61472182, 61333014), and the Fundamental Research Funds for the Central Universities (No. 20620140510)