正在加载图片...
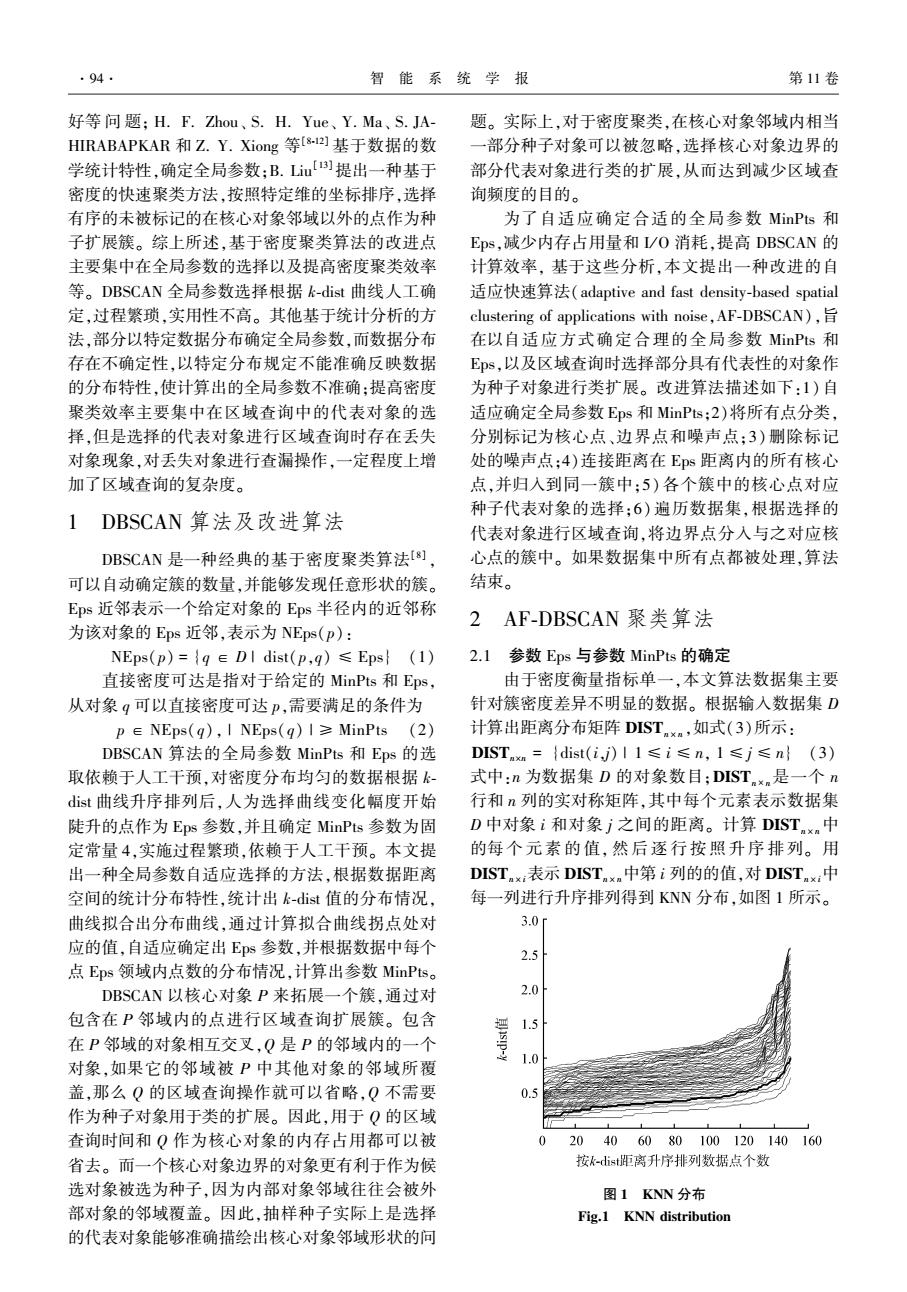
·94. 智能系统学报 第11卷 好等问题;H.F.Zhou、S.H.Yue、Y.Ma、S.JA- 题。实际上,对于密度聚类,在核心对象邻域内相当 HIRABAPKAR和Z.Y.Xiong等s-]基于数据的数 一部分种子对象可以被忽略,选择核心对象边界的 学统计特性,确定全局参数:B.Lim)提出一种基于 部分代表对象进行类的扩展,从而达到减少区域查 密度的快速聚类方法,按照特定维的坐标排序,选择 询频度的目的。 有序的未被标记的在核心对象邻域以外的点作为种 为了自适应确定合适的全局参数MinPts和 子扩展簇。综上所述,基于密度聚类算法的改进点 Eps,减少内存占用量和I/O消耗,提高DBSCAN的 主要集中在全局参数的选择以及提高密度聚类效率 计算效率,基于这些分析,本文提出一种改进的自 等。DBSCAN全局参数选择根据k-dist曲线人工确 适应快速算法(adaptive and fast density-based spatial 定,过程繁琐,实用性不高。其他基于统计分析的方 clustering of applications with noise,AF-DBSCAN), 法,部分以特定数据分布确定全局参数,而数据分布 在以自适应方式确定合理的全局参数MinPts和 存在不确定性,以特定分布规定不能准确反映数据 E即s,以及区域查询时选择部分具有代表性的对象作 的分布特性,使计算出的全局参数不准确:提高密度 为种子对象进行类扩展。改进算法描述如下:1)自 聚类效率主要集中在区域查询中的代表对象的选 适应确定全局参数Eps和MinPts;2)将所有点分类, 择,但是选择的代表对象进行区域查询时存在丢失 分别标记为核心点、边界点和噪声点;3)删除标记 对象现象,对丢失对象进行查漏操作,一定程度上增 处的噪声点:4)连接距离在Eps距离内的所有核心 加了区域查询的复杂度。 点,并归入到同一簇中:5)各个簇中的核心点对应 种子代表对象的选择:6)遍历数据集,根据选择的 DBSCAN算法及改进算法 代表对象进行区域查询,将边界点分入与之对应核 DBSCAN是一种经典的基于密度聚类算法[8]」 心点的簇中。如果数据集中所有点都被处理,算法 可以自动确定簇的数量,并能够发现任意形状的簇。 结束。 Eps近邻表示一个给定对象的Eps半径内的近邻称 2AF-DBSCAN聚类算法 为该对象的Eps近邻,表示为NEps(p): NEps(p)={q∈DI dist(p,q)≤Eps}(1) 2.1参数Eps与参数MinPts的确定 直接密度可达是指对于给定的MinPts和Eps, 由于密度衡量指标单一,本文算法数据集主要 从对象q可以直接密度可达P,需要满足的条件为 针对簇密度差异不明显的数据。根据输入数据集D p∈NEps(q),I NEps(q)I≥MinPts(2) 计算出距离分布矩阵DIST,如式(3)所示: DBSCAN算法的全局参数MinPts和Eps的选 DIST={dist(i,ji)I1≤i≤n,1≤j≤n}(3) 取依赖于人工干预,对密度分布均匀的数据根据k 式中:n为数据集D的对象数目;DIST.xm是一个n dist曲线升序排列后,人为选择曲线变化幅度开始 行和n列的实对称矩阵,其中每个元素表示数据集 陡升的点作为Eps参数,并且确定MinPts参数为固 D中对象i和对象j之间的距离。计算DIST中 定常量4,实施过程繁琐,依赖于人工干预。本文提 的每个元素的值,然后逐行按照升序排列。用 出一种全局参数自适应选择的方法,根据数据距离 DIST:表示DIST中第i列的的值,对DIST:中 空间的统计分布特性,统计出k-dst值的分布情况. 每一列进行升序排列得到KNN分布,如图1所示。 曲线拟合出分布曲线,通过计算拟合曲线拐点处对 3.0f 应的值,自适应确定出Es参数,并根据数据中每个 2.5 点Eps领域内点数的分布情况,计算出参数MinPts.。 DBSCAN以核心对象P来拓展一个簇,通过对 2.0 包含在P邻域内的点进行区域查询扩展簇。包含 1 在P邻域的对象相互交叉,Q是P的邻域内的一个 1.0 对象,如果它的邻域被P中其他对象的邻域所覆 盖,那么Q的区域查询操作就可以省略,Q不需要 0.5 作为种子对象用于类的扩展。因此,用于Q的区域 查询时间和Q作为核心对象的内存占用都可以被 0 20 406080100120140160 省去。而一个核心对象边界的对象更有利于作为候 按k-dist距离升序排列数据点个数 选对象被选为种子,因为内部对象邻域往往会被外 图1KNN分布 部对象的邻域覆盖。因此,抽样种子实际上是选择 Fig.1 KNN distribution 的代表对象能够准确描绘出核心对象邻域形状的问好等 问 题; H. F. Zhou、 S. H. Yue、 Y. Ma、 S. JA⁃ HIRABAPKAR 和 Z. Y. Xiong 等[8⁃12] 基于数据的数 学统计特性,确定全局参数;B. Liu [13]提出一种基于 密度的快速聚类方法,按照特定维的坐标排序,选择 有序的未被标记的在核心对象邻域以外的点作为种 子扩展簇。 综上所述,基于密度聚类算法的改进点 主要集中在全局参数的选择以及提高密度聚类效率 等。 DBSCAN 全局参数选择根据 k⁃dist 曲线人工确 定,过程繁琐,实用性不高。 其他基于统计分析的方 法,部分以特定数据分布确定全局参数,而数据分布 存在不确定性,以特定分布规定不能准确反映数据 的分布特性,使计算出的全局参数不准确;提高密度 聚类效率主要集中在区域查询中的代表对象的选 择,但是选择的代表对象进行区域查询时存在丢失 对象现象,对丢失对象进行查漏操作,一定程度上增 加了区域查询的复杂度。 1 DBSCAN 算法及改进算法 DBSCAN 是一种经典的基于密度聚类算法[8] , 可以自动确定簇的数量,并能够发现任意形状的簇。 Eps 近邻表示一个给定对象的 Eps 半径内的近邻称 为该对象的 Eps 近邻,表示为 NEps(p): NEps(p) = {q ∈ D | dist(p,q) ≤ Eps} (1) 直接密度可达是指对于给定的 MinPts 和 Eps, 从对象 q 可以直接密度可达 p,需要满足的条件为 p ∈ NEps(q), | NEps(q) | ≥ MinPts (2) DBSCAN 算法的全局参数 MinPts 和 Eps 的选 取依赖于人工干预,对密度分布均匀的数据根据 k⁃ dist 曲线升序排列后,人为选择曲线变化幅度开始 陡升的点作为 Eps 参数,并且确定 MinPts 参数为固 定常量 4,实施过程繁琐,依赖于人工干预。 本文提 出一种全局参数自适应选择的方法,根据数据距离 空间的统计分布特性,统计出 k⁃dist 值的分布情况, 曲线拟合出分布曲线,通过计算拟合曲线拐点处对 应的值,自适应确定出 Eps 参数,并根据数据中每个 点 Eps 领域内点数的分布情况,计算出参数 MinPts。 DBSCAN 以核心对象 P 来拓展一个簇,通过对 包含在 P 邻域内的点进行区域查询扩展簇。 包含 在 P 邻域的对象相互交叉,Q 是 P 的邻域内的一个 对象,如果它的邻域被 P 中其他对象的邻域所覆 盖,那么 Q 的区域查询操作就可以省略,Q 不需要 作为种子对象用于类的扩展。 因此,用于 Q 的区域 查询时间和 Q 作为核心对象的内存占用都可以被 省去。 而一个核心对象边界的对象更有利于作为候 选对象被选为种子,因为内部对象邻域往往会被外 部对象的邻域覆盖。 因此,抽样种子实际上是选择 的代表对象能够准确描绘出核心对象邻域形状的问 题。 实际上,对于密度聚类,在核心对象邻域内相当 一部分种子对象可以被忽略,选择核心对象边界的 部分代表对象进行类的扩展,从而达到减少区域查 询频度的目的。 为了自适应确定合适的全局参数 MinPts 和 Eps,减少内存占用量和 I/ O 消耗,提高 DBSCAN 的 计算效率, 基于这些分析,本文提出一种改进的自 适应快速算法(adaptive and fast density⁃based spatial clustering of applications with noise,AF⁃DBSCAN),旨 在以自适应方式确定合理的全局参数 MinPts 和 Eps,以及区域查询时选择部分具有代表性的对象作 为种子对象进行类扩展。 改进算法描述如下:1)自 适应确定全局参数 Eps 和 MinPts;2)将所有点分类, 分别标记为核心点、边界点和噪声点;3) 删除标记 处的噪声点;4)连接距离在 Eps 距离内的所有核心 点,并归入到同一簇中;5) 各个簇中的核心点对应 种子代表对象的选择;6) 遍历数据集,根据选择的 代表对象进行区域查询,将边界点分入与之对应核 心点的簇中。 如果数据集中所有点都被处理,算法 结束。 2 AF⁃DBSCAN 聚类算法 2.1 参数 Eps 与参数 MinPts 的确定 由于密度衡量指标单一,本文算法数据集主要 针对簇密度差异不明显的数据。 根据输入数据集 D 计算出距离分布矩阵 DISTn × n ,如式(3)所示: DISTn×n = {dist(i,j) | 1 ≤ i ≤ n, 1 ≤ j ≤ n} (3) 式中:n 为数据集 D 的对象数目;DISTn × n是一个 n 行和 n 列的实对称矩阵,其中每个元素表示数据集 D 中对象 i 和对象 j 之间的距离。 计算 DISTn × n中 的每 个 元 素 的 值, 然 后 逐 行 按 照 升 序 排 列。 用 DISTn × i表示 DISTn × n中第 i 列的的值,对 DISTn × i中 每一列进行升序排列得到 KNN 分布,如图 1 所示。 图 1 KNN 分布 Fig.1 KNN distribution ·94· 智 能 系 统 学 报 第 11 卷