正在加载图片...
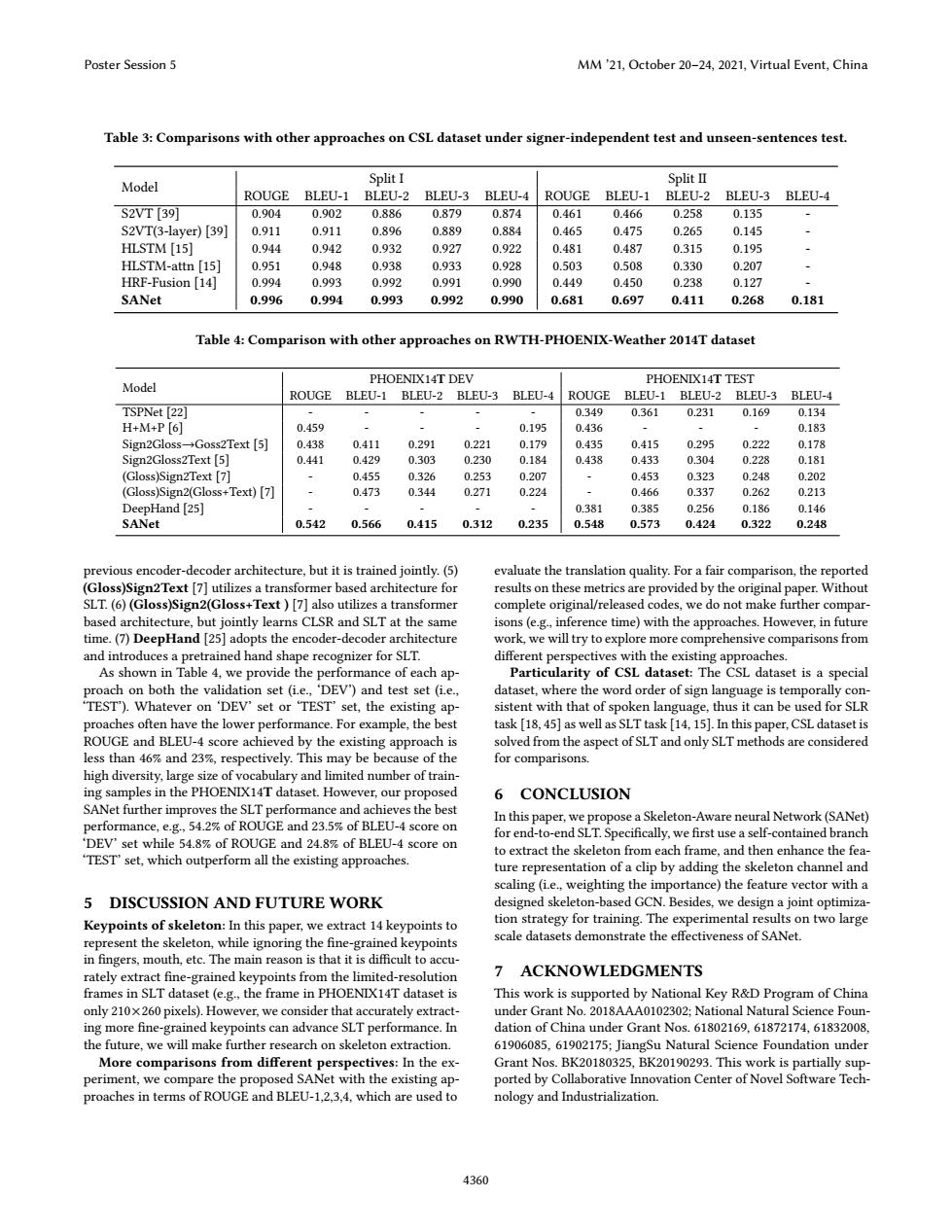
Poster Session 5 MM'21.October 20-24,2021,Virtual Event,China Table 3:Comparisons with other approaches on CSL dataset under signer-independent test and unseen-sentences test. SplitΠ Model Split I ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 S2VT[39] 0.904 0.902 0.886 0.879 0.874 0.461 0.466 0.258 0.135 S2VT(3-layer)[39] 0.911 0.911 0.896 0.889 0.884 0.465 0.475 0.265 0.145 HLSTM [15] 0.944 0.942 0.932 0.927 0.922 0.481 0.487 0.315 0.195 HLSTM-attn [15] 0.951 0.948 0.938 0.933 0.928 0.503 0.508 0.330 0.207 HRF-Fusion [14] 0.994 0.993 0.992 0.991 0.990 0.449 0.450 0.238 0.127 SANet 0.996 0.994 0.993 0.992 0.990 0.681 0.697 0.411 0.268 0.181 Table 4:Comparison with other approaches on RWTH-PHOENIX-Weather 2014T dataset PHOENIX14T DEV PHOENIX14T TEST Model ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 TSPNet [22 0.349 0.361 0.231 0.169 0.134 H+M+P[6] 0.459 0.195 0.436 0.183 Sign2Gloss-Goss2Text [5] 0.438 0.411 0.291 0.221 0.179 0.435 0.415 0.295 0.222 0.178 Sign2Gloss2Text [5] 0.441 0.429 0.303 0.230 0.184 0.438 0.433 0.304 0.228 0.181 (Gloss)Sign2Text [7] 0.455 0.326 0.253 0.207 0.453 0.323 0.248 0.202 (Gloss)Sign2(Gloss+Text)[7] 0.473 0.344 0.271 0.224 0.466 0.337 0.262 0.213 DeepHand [25] 0.381 0.385 0.256 0.186 0.146 SANet 0.542 0.566 0.415 0.312 0.235 0.548 0.573 0.424 0.322 0.248 previous encoder-decoder architecture,but it is trained jointly.(5) evaluate the translation quality.For a fair comparison,the reported (Gloss)Sign2Text [7]utilizes a transformer based architecture for results on these metrics are provided by the original paper.Without SLT.(6)(Gloss)Sign2(Gloss+Text )[7]also utilizes a transformer complete original/released codes,we do not make further compar- based architecture,but jointly learns CLSR and SLT at the same isons(e.g.,inference time)with the approaches.However,in future time.(7)DeepHand [25]adopts the encoder-decoder architecture work,we will try to explore more comprehensive comparisons from and introduces a pretrained hand shape recognizer for SLT. different perspectives with the existing approaches. As shown in Table 4,we provide the performance of each ap- Particularity of CSL dataset:The CSL dataset is a special proach on both the validation set(ie.,'DEV)and test set(ie., dataset,where the word order of sign language is temporally con TEST).Whatever on 'DEV'set or TEST'set,the existing ap- sistent with that of spoken language,thus it can be used for SLR proaches often have the lower performance.For example,the best task [18,45]as well as SLT task [14,15].In this paper,CSL dataset is ROUGE and BLEU-4 score achieved by the existing approach is solved from the aspect of SLT and only SLT methods are considered less than 46%and 23%,respectively.This may be because of the for comparisons. high diversity,large size of vocabulary and limited number of train- ing samples in the PHOENIX14T dataset.However,our proposed 6 CONCLUSION SANet further improves the SLT performance and achieves the best performance,e.g,54.2%of ROUGE and 23.5%of BLEU-4 score on In this paper,we propose a Skeleton-Aware neural Network(SANet) for end-to-end SLT.Specifically,we first use a self-contained branch 'DEV'set while 54.8%of ROUGE and 24.8%of BLEU-4 score on to extract the skeleton from each frame,and then enhance the fea- TEST set,which outperform all the existing approaches. ture representation of a clip by adding the skeleton channel and scaling (i.e.,weighting the importance)the feature vector with a DISCUSSION AND FUTURE WORK designed skeleton-based GCN.Besides,we design a joint optimiza- Keypoints of skeleton:In this paper,we extract 14 keypoints to tion strategy for training.The experimental results on two large represent the skeleton,while ignoring the fine-grained keypoints scale datasets demonstrate the effectiveness of SANet. in fingers,mouth,etc.The main reason is that it is difficult to accu- rately extract fine-grained keypoints from the limited-resolution 7 ACKNOWLEDGMENTS frames in SLT dataset(e.g.,the frame in PHOENIX14T dataset is This work is supported by National Key R&D Program of China only 210x260 pixels).However,we consider that accurately extract- under Grant No.2018AAA0102302;National Natural Science Foun- ing more fine-grained keypoints can advance SLT performance.In dation of China under Grant Nos.61802169,61872174,61832008, the future,we will make further research on skeleton extraction. 61906085,61902175;JiangSu Natural Science Foundation under More comparisons from different perspectives:In the ex- Grant Nos.BK20180325,BK20190293.This work is partially sup- periment,we compare the proposed SANet with the existing ap- ported by Collaborative Innovation Center of Novel Software Tech- proaches in terms of ROUGE and BLEU-1,2,3,4,which are used to nology and Industrialization. 4360Table 3: Comparisons with other approaches on CSL dataset under signer-independent test and unseen-sentences test. Model Split I Split II ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 S2VT [39] 0.904 0.902 0.886 0.879 0.874 0.461 0.466 0.258 0.135 - S2VT(3-layer) [39] 0.911 0.911 0.896 0.889 0.884 0.465 0.475 0.265 0.145 - HLSTM [15] 0.944 0.942 0.932 0.927 0.922 0.481 0.487 0.315 0.195 - HLSTM-attn [15] 0.951 0.948 0.938 0.933 0.928 0.503 0.508 0.330 0.207 - HRF-Fusion [14] 0.994 0.993 0.992 0.991 0.990 0.449 0.450 0.238 0.127 - SANet 0.996 0.994 0.993 0.992 0.990 0.681 0.697 0.411 0.268 0.181 Table 4: Comparison with other approaches on RWTH-PHOENIX-Weather 2014T dataset Model PHOENIX14T DEV PHOENIX14T TEST ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 ROUGE BLEU-1 BLEU-2 BLEU-3 BLEU-4 TSPNet [22] - - - - - 0.349 0.361 0.231 0.169 0.134 H+M+P [6] 0.459 - - - 0.195 0.436 - - - 0.183 Sign2Gloss→Goss2Text [5] 0.438 0.411 0.291 0.221 0.179 0.435 0.415 0.295 0.222 0.178 Sign2Gloss2Text [5] 0.441 0.429 0.303 0.230 0.184 0.438 0.433 0.304 0.228 0.181 (Gloss)Sign2Text [7] - 0.455 0.326 0.253 0.207 - 0.453 0.323 0.248 0.202 (Gloss)Sign2(Gloss+Text) [7] - 0.473 0.344 0.271 0.224 - 0.466 0.337 0.262 0.213 DeepHand [25] - - - - - 0.381 0.385 0.256 0.186 0.146 SANet 0.542 0.566 0.415 0.312 0.235 0.548 0.573 0.424 0.322 0.248 previous encoder-decoder architecture, but it is trained jointly. (5) (Gloss)Sign2Text [7] utilizes a transformer based architecture for SLT. (6) (Gloss)Sign2(Gloss+Text ) [7] also utilizes a transformer based architecture, but jointly learns CLSR and SLT at the same time. (7) DeepHand [25] adopts the encoder-decoder architecture and introduces a pretrained hand shape recognizer for SLT. As shown in Table 4, we provide the performance of each approach on both the validation set (i.e., ‘DEV’) and test set (i.e., ‘TEST’). Whatever on ‘DEV’ set or ‘TEST’ set, the existing approaches often have the lower performance. For example, the best ROUGE and BLEU-4 score achieved by the existing approach is less than 46% and 23%, respectively. This may be because of the high diversity, large size of vocabulary and limited number of training samples in the PHOENIX14T dataset. However, our proposed SANet further improves the SLT performance and achieves the best performance, e.g., 54.2% of ROUGE and 23.5% of BLEU-4 score on ‘DEV’ set while 54.8% of ROUGE and 24.8% of BLEU-4 score on ‘TEST’ set, which outperform all the existing approaches. 5 DISCUSSION AND FUTURE WORK Keypoints of skeleton: In this paper, we extract 14 keypoints to represent the skeleton, while ignoring the fine-grained keypoints in fingers, mouth, etc. The main reason is that it is difficult to accurately extract fine-grained keypoints from the limited-resolution frames in SLT dataset (e.g., the frame in PHOENIX14T dataset is only 210×260 pixels). However, we consider that accurately extracting more fine-grained keypoints can advance SLT performance. In the future, we will make further research on skeleton extraction. More comparisons from different perspectives: In the experiment, we compare the proposed SANet with the existing approaches in terms of ROUGE and BLEU-1,2,3,4, which are used to evaluate the translation quality. For a fair comparison, the reported results on these metrics are provided by the original paper. Without complete original/released codes, we do not make further comparisons (e.g., inference time) with the approaches. However, in future work, we will try to explore more comprehensive comparisons from different perspectives with the existing approaches. Particularity of CSL dataset: The CSL dataset is a special dataset, where the word order of sign language is temporally consistent with that of spoken language, thus it can be used for SLR task [18, 45] as well as SLT task [14, 15]. In this paper, CSL dataset is solved from the aspect of SLT and only SLT methods are considered for comparisons. 6 CONCLUSION In this paper, we propose a Skeleton-Aware neural Network (SANet) for end-to-end SLT. Specifically, we first use a self-contained branch to extract the skeleton from each frame, and then enhance the feature representation of a clip by adding the skeleton channel and scaling (i.e., weighting the importance) the feature vector with a designed skeleton-based GCN. Besides, we design a joint optimization strategy for training. The experimental results on two large scale datasets demonstrate the effectiveness of SANet. 7 ACKNOWLEDGMENTS This work is supported by National Key R&D Program of China under Grant No. 2018AAA0102302; National Natural Science Foundation of China under Grant Nos. 61802169, 61872174, 61832008, 61906085, 61902175; JiangSu Natural Science Foundation under Grant Nos. BK20180325, BK20190293. This work is partially supported by Collaborative Innovation Center of Novel Software Technology and Industrialization. Poster Session 5 MM ’21, October 20–24, 2021, Virtual Event, China 4360