正在加载图片...
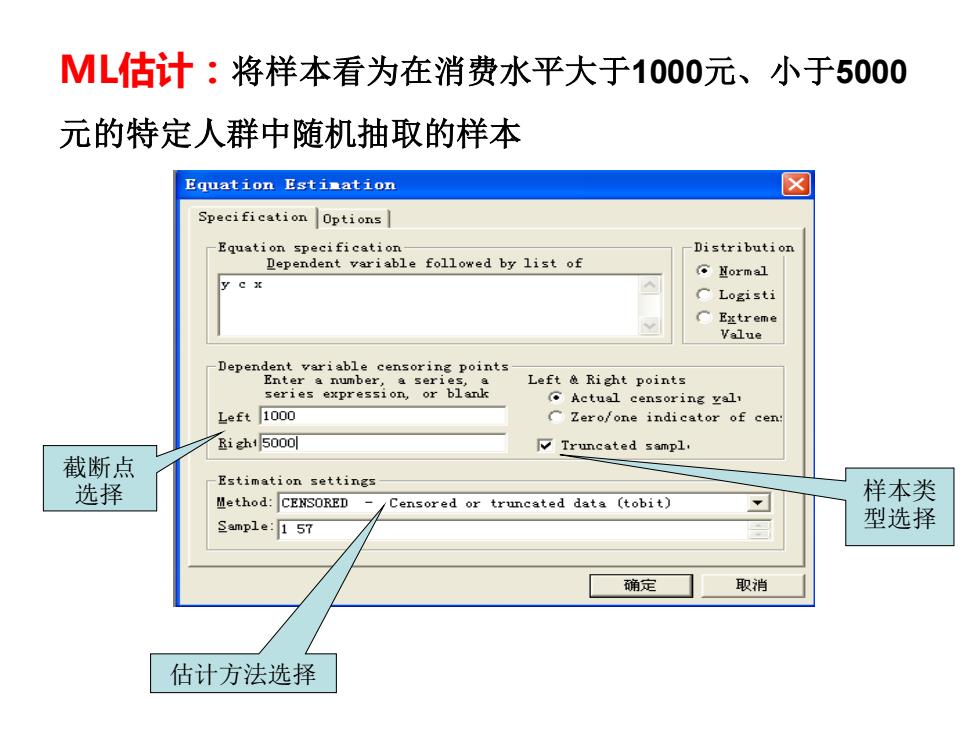
ML估计:将样本看为在消费水平大于1000元、小于5000 元的特定人群中随机抽取的样本 Equation Estimation ☒ Specification Options -Equation specification- Distribution Dependent variable followed by list of 且ormal y e x C Logisti C Extreme Value -Dependent variable censoring points- Enter a number,a series,a Left Right points series expression,or blank Actual censoring yall Left 1000 CZero/one indicator of cen: igh15000 Truncated sampl. 截断点 Estimation settings 选择 Method:CENSORED Censored or truncated data (tobit) 样本类 Sample:1 57 型选择 确定 取消 估计方法选择 ML估计:将样本看为在消费水平大于1000元、小于5000 元的特定人群中随机抽取的样本 估计方法选择 样本类 型选择 截断点 选择