正在加载图片...
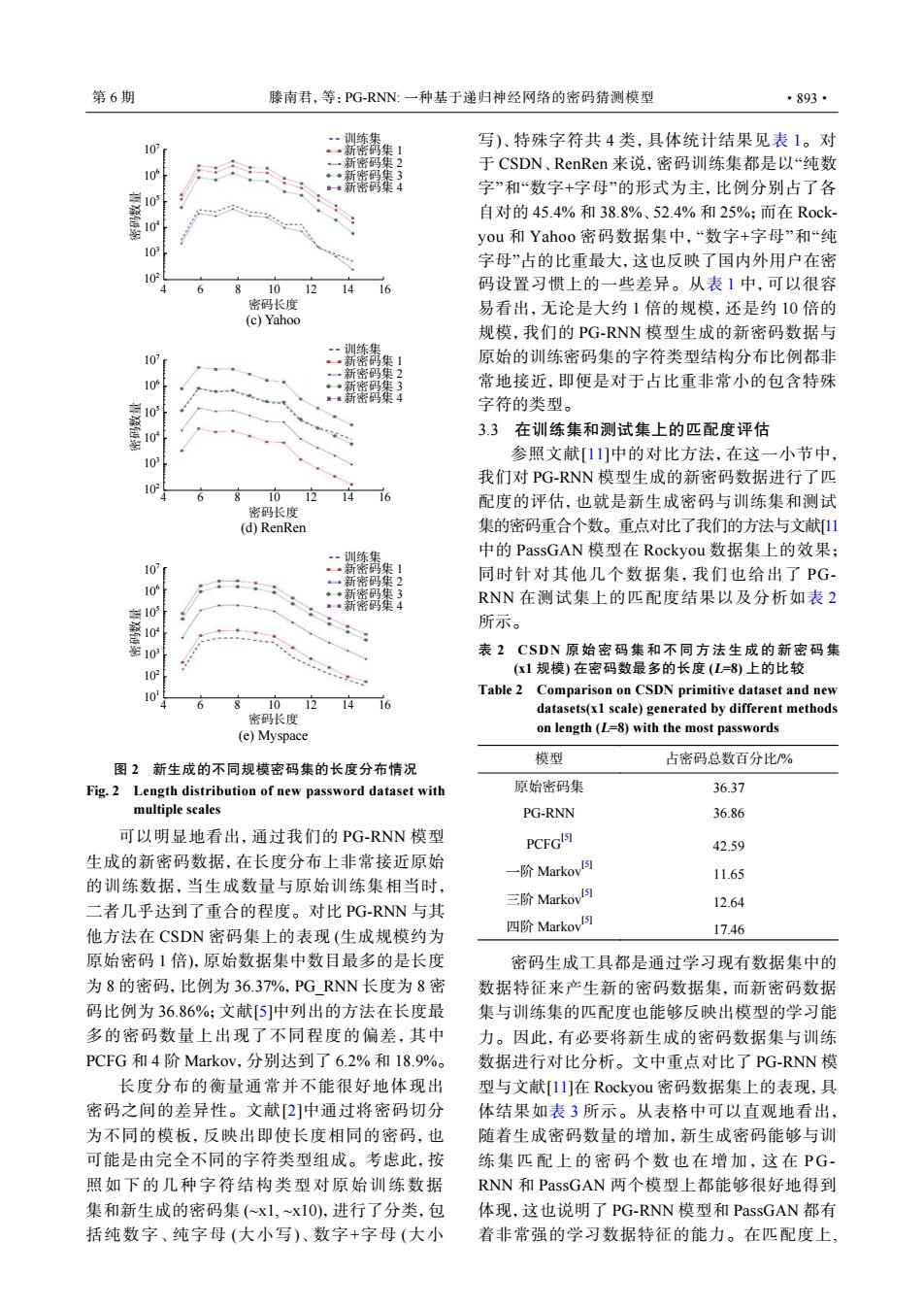
第6期 滕南君,等:PG-RNN:一种基于递归神经网络的密码猜测模型 ·893· 10 写)、特殊字符共4类,具体统计结果见表1。对 10 于CSDN、RenRen来说,密码训练集都是以“纯数 字”和“数字+字母”的形式为主,比例分别占了各 105 自对的45.4%和38.8%、52.4%和25%:而在R0ck 10 you和Yahoo密码数据集中,“数字+字母”和“纯 字母”占的比重最大,这也反映了国内外用户在密 10 8 10 12 14 16 码设置习惯上的一些差异。从表1中,可以很容 密码长度 易看出,无论是大约1倍的规模,还是约10倍的 (c)Yahoo 规模.我们的PG-RNN模型生成的新密码数据与 107 原始的训练密码集的字符类型结构分布比例都非 10 常地接近,即便是对于占比重非常小的包含特殊 10 字符的类型。 10 3.3在训练集和测试集上的匹配度评估 参照文献[11]中的对比方法,在这一小节中, 我们对PG-RNN模型生成的新密码数据进行了匹 10 1012 14 16 配度的评估,也就是新生成密码与训练集和测试 密码长度 (d)RenRen 集的密码重合个数。重点对比了我们的方法与文献[1山 中的PassGAN模型在Rockyou数据集上的效果; 10 同时针对其他几个数据集,我们也给出了PG 10 RNN在测试集上的匹配度结果以及分析如表2 所示。 表2CSDN原始密码集和不同方法生成的新密码集 10 (x1规模)在密码数最多的长度(L=8)上的比较 10 Table 2 Comparison on CSDN primitive dataset and new 81012 14 16 datasets(x1 scale)generated by different methods 密码长度 (e)Myspace on length(L=8)with the most passwords 模型 占密码总数百分比% 图2新生成的不同规模密码集的长度分布情况 Fig.2 Length distribution of new password dataset with 原始密码集 36.37 multiple scales PG-RNN 36.86 可以明显地看出,通过我们的PG-RNN模型 PCFGIS] 42.59 生成的新密码数据,在长度分布上非常接近原始 一阶MarkovI5 11.65 的训练数据,当生成数量与原始训练集相当时, 二者几乎达到了重合的程度。对比PG-RNN与其 三阶Markov 12.64 他方法在CSDN密码集上的表现(生成规模约为 四阶Markov 17.46 原始密码1倍),原始数据集中数目最多的是长度 密码生成工具都是通过学习现有数据集中的 为8的密码,比例为36.37%,PG RNN长度为8密 数据特征来产生新的密码数据集,而新密码数据 码比例为36.86%:文献[5]中列出的方法在长度最 集与训练集的匹配度也能够反映出模型的学习能 多的密码数量上出现了不同程度的偏差,其中 力。因此,有必要将新生成的密码数据集与训练 PCFG和4阶Markov,分别达到了6.2%和18.9% 数据进行对比分析。文中重点对比了PG-RNN模 长度分布的衡量通常并不能很好地体现出 型与文献[11]在Rockyou密码数据集上的表现,具 密码之间的差异性。文献[2]中通过将密码切分 体结果如表3所示。从表格中可以直观地看出, 为不同的模板,反映出即使长度相同的密码,也 随着生成密码数量的增加,新生成密码能够与训 可能是由完全不同的字符类型组成。考虑此,按 练集匹配上的密码个数也在增加,这在PG- 照如下的几种字符结构类型对原始训练数据 RNN和PassGAN两个模型上都能够很好地得到 集和新生成的密码集(~x1,~x10),进行了分类,包 体现,这也说明了PG-RNN模型和PassGAN都有 括纯数字、纯字母(大小写)、数字+字母(大小 着非常强的学习数据特征的能力。在匹配度上,可以明显地看出,通过我们的 PG-RNN 模型 生成的新密码数据,在长度分布上非常接近原始 的训练数据,当生成数量与原始训练集相当时, 二者几乎达到了重合的程度。对比 PG-RNN 与其 他方法在 CSDN 密码集上的表现 (生成规模约为 原始密码 1 倍),原始数据集中数目最多的是长度 为 8 的密码,比例为 36.37%,PG_RNN 长度为 8 密 码比例为 36.86%;文献[5]中列出的方法在长度最 多的密码数量上出现了不同程度的偏差,其中 PCFG 和 4 阶 Markov,分别达到了 6.2% 和 18.9%。 长度分布的衡量通常并不能很好地体现出 密码之间的差异性。文献[2]中通过将密码切分 为不同的模板,反映出即使长度相同的密码,也 可能是由完全不同的字符类型组成。考虑此,按 照如下的几种字符结构类型对原始训练数据 集和新生成的密码集 (~x1, ~x10),进行了分类,包 括纯数字、纯字母 (大小写)、数字+字母 (大小 写)、特殊字符共 4 类,具体统计结果见表 1。对 于 CSDN、RenRen 来说,密码训练集都是以“纯数 字”和“数字+字母”的形式为主,比例分别占了各 自对的 45.4% 和 38.8%、52.4% 和 25%;而在 Rockyou 和 Yahoo 密码数据集中,“数字+字母”和“纯 字母”占的比重最大,这也反映了国内外用户在密 码设置习惯上的一些差异。从表 1 中,可以很容 易看出,无论是大约 1 倍的规模,还是约 10 倍的 规模,我们的 PG-RNN 模型生成的新密码数据与 原始的训练密码集的字符类型结构分布比例都非 常地接近,即便是对于占比重非常小的包含特殊 字符的类型。 3.3 在训练集和测试集上的匹配度评估 参照文献[11]中的对比方法,在这一小节中, 我们对 PG-RNN 模型生成的新密码数据进行了匹 配度的评估,也就是新生成密码与训练集和测试 集的密码重合个数。重点对比了我们的方法与文献[11 中的 PassGAN 模型在 Rockyou 数据集上的效果; 同时针对其他几个数据集,我们也给出了 PGRNN 在测试集上的匹配度结果以及分析如表 2 所示。 密码生成工具都是通过学习现有数据集中的 数据特征来产生新的密码数据集,而新密码数据 集与训练集的匹配度也能够反映出模型的学习能 力。因此,有必要将新生成的密码数据集与训练 数据进行对比分析。文中重点对比了 PG-RNN 模 型与文献[11]在 Rockyou 密码数据集上的表现,具 体结果如表 3 所示。从表格中可以直观地看出, 随着生成密码数量的增加,新生成密码能够与训 练集匹配上的密码个数也在增加,这 在 PGRNN 和 PassGAN 两个模型上都能够很好地得到 体现,这也说明了 PG-RNN 模型和 PassGAN 都有 着非常强的学习数据特征的能力。在匹配度上, 表 2 CSDN 原始密码集和不同方法生成的新密码集 (x1 规模) 在密码数最多的长度 (L=8) 上的比较 Table 2 Comparison on CSDN primitive dataset and new datasets(x1 scale) generated by different methods on length (L=8) with the most passwords 模型 占密码总数百分比/% 原始密码集 36.37 PG-RNN 36.86 PCFG[5] 42.59 一阶 Markov[5] 11.65 三阶 Markov[5] 12.64 四阶 Markov[5] 17.46 (c) Yahoo (d) RenRen 107 106 105 104 103 102 密码数量 4 6 8 10 12 14 16 训练集 新密码集 1 新密码集 2 新密码集 3 新密码集 4 密码长度 107 106 105 104 103 102 密码数量 4 6 8 10 12 14 16 训练集 新密码集 1 新密码集 2 新密码集 3 新密码集 4 密码长度 (e) Myspace 107 106 105 104 103 101 102 密码数量 4 6 8 10 12 14 16 训练集 新密码集 1 新密码集 2 新密码集 3 新密码集 4 密码长度 图 2 新生成的不同规模密码集的长度分布情况 Fig. 2 Length distribution of new password dataset with multiple scales 第 6 期 滕南君,等:PG-RNN: 一种基于递归神经网络的密码猜测模型 ·893·