正在加载图片...
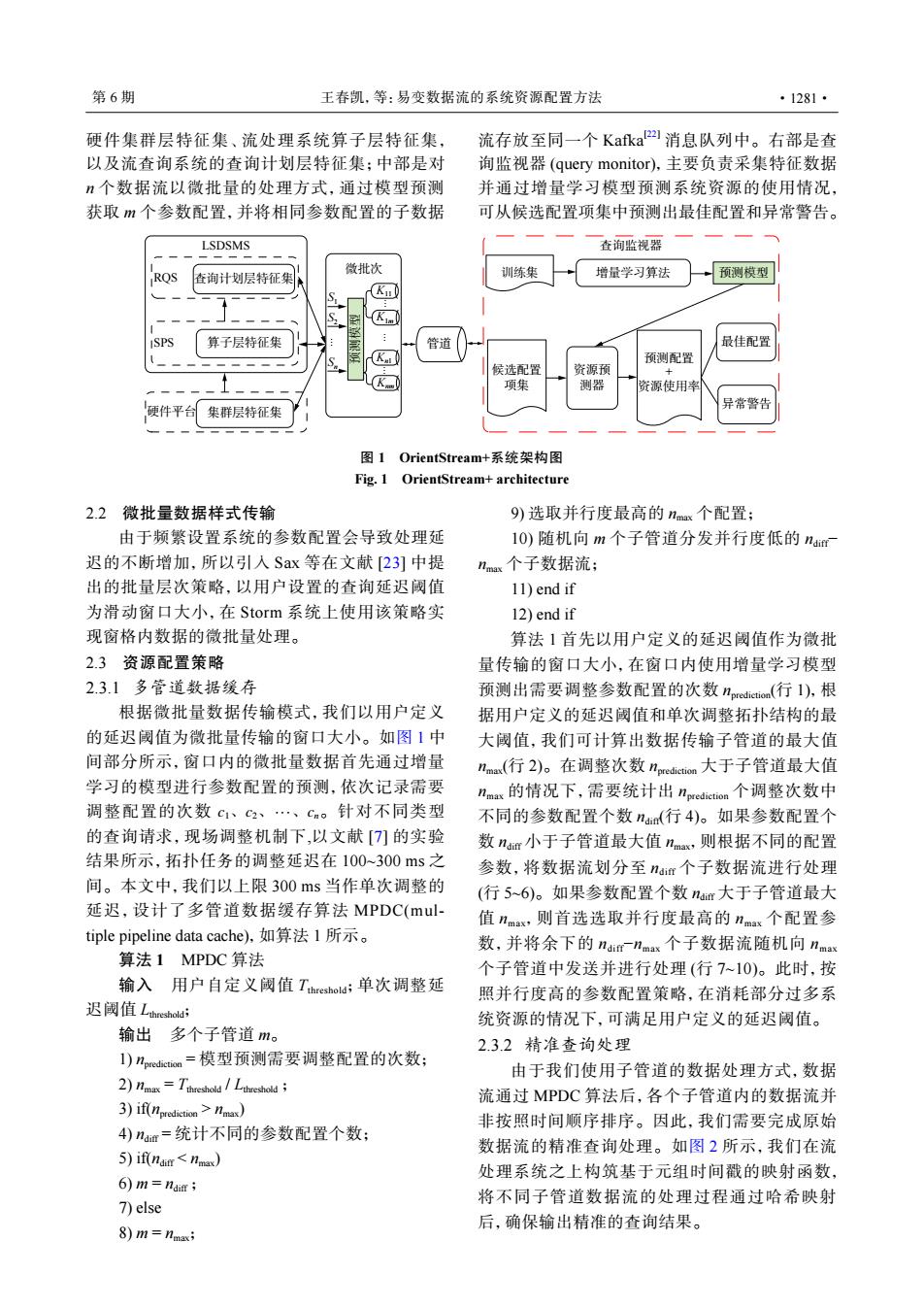
第6期 王春凯,等:易变数据流的系统资源配置方法 ·1281· 硬件集群层特征集、流处理系统算子层特征集, 流存放至同一个Kafka2消息队列中。右部是查 以及流查询系统的查询计划层特征集;中部是对 询监视器(query monitor),主要负责采集特征数据 n个数据流以微批量的处理方式,通过模型预测 并通过增量学习模型预测系统资源的使用情况, 获取m个参数配置,并将相同参数配置的子数据 可从候选配置项集中预测出最佳配置和异常警告。 LSDSMS 查询监视器 查询计划层特征集、 微批次 RQS 训练集 增量学习算法 预测模型 Kn K 算子层特征集 管道 最佳配置 预测配置 候选配置 资源预 + 项集 测器 资源使用幸 硬件平集群层特征集 异常警告 图1 OrientStream+系统架构图 Fig.1 OrientStream+architecture 2.2微批量数据样式传输 9)选取并行度最高的nax个配置: 由于频繁设置系统的参数配置会导致处理延 10)随机向m个子管道分发并行度低的nar 迟的不断增加,所以引入Sax等在文献[23]中提 nma个子数据流: 出的批量层次策略,以用户设置的查询延迟阈值 11)end if 为滑动窗口大小,在Storm系统上使用该策略实 12)end if 现窗格内数据的微批量处理。 算法1首先以用户定义的延迟阈值作为微批 2.3资源配置策略 量传输的窗口大小,在窗口内使用增量学习模型 2.3.1多管道数据缓存 预测出需要调整参数配置的次数redit(行I),根 根据微批量数据传输模式,我们以用户定义 据用户定义的延迟阈值和单次调整拓扑结构的最 的延迟阈值为微批量传输的窗口大小。如图1中 大阈值,我们可计算出数据传输子管道的最大值 间部分所示,窗口内的微批量数据首先通过增量 nma(行2)。在调整次数reition大于子管道最大值 学习的模型进行参数配置的预测,依次记录需要 nmax的情况下,需要统计出pediction个调整次数中 调整配置的次数c1、c2、、cn。针对不同类型 不同的参数配置个数n(行4)。如果参数配置个 的查询请求,现场调整机制下,以文献[⑦)的实验 数nm小于子管道最大值nax,则根据不同的配置 结果所示,拓扑任务的调整延迟在100~300ms之 参数,将数据流划分至nar个子数据流进行处理 间。本文中,我们以上限300ms当作单次调整的 (行5~6)。如果参数配置个数nm大于子管道最大 延迟,设计了多管道数据缓存算法MPDC(mul- 值nmax,则首选选取并行度最高的nmax个配置参 tiple pipeline data cache),如算法l所示。 数,并将余下的nuim一nmax个子数据流随机向nmax 算法1MPDC算法 个子管道中发送并进行处理(行7~10)。此时,按 输入用户自定义阈值Tthreshold;单次调整延 照并行度高的参数配置策略,在消耗部分过多系 迟阈值treho; 统资源的情况下,可满足用户定义的延迟阈值。 输出多个子管道m。 2.3.2精准查询处理 1)pdii=模型预测需要调整配置的次数; 由于我们使用子管道的数据处理方式,数据 2)1m-Tthreshold Ltheshold 流通过MPDC算法后,各个子管道内的数据流并 3)if(npredictionMmax) 非按照时间顺序排序。因此,我们需要完成原始 4)nm=统计不同的参数配置个数; 数据流的精准查询处理。如图2所示,我们在流 5)if(naitr<nmax) 处理系统之上构筑基于元组时间戳的映射函数, 6)m=ndif 将不同子管道数据流的处理过程通过哈希映射 7)else 后,确保输出精准的查询结果。 8)m=nmax;硬件集群层特征集、流处理系统算子层特征集, 以及流查询系统的查询计划层特征集;中部是对 n 个数据流以微批量的处理方式,通过模型预测 获取 m 个参数配置,并将相同参数配置的子数据 流存放至同一个 Kafka[22] 消息队列中。右部是查 询监视器 (query monitor),主要负责采集特征数据 并通过增量学习模型预测系统资源的使用情况, 可从候选配置项集中预测出最佳配置和异常警告。 训练集 预测模型 资源预 测器 SPS 算子层特征集 RQS 查询计划层特征集 硬件平台 集群层特征集 查询监视器 增量学习算法 LSDSMS 候选配置 项集 预测配置 + 资源使用率 最佳配置 异常警告 管道 微批次 S1 K11 K1m Knm Kn1 S2 Sn... 预测模型 ... ... ... 图 1 OrientStream+系统架构图 Fig. 1 OrientStream+ architecture 2.2 微批量数据样式传输 由于频繁设置系统的参数配置会导致处理延 迟的不断增加,所以引入 Sax 等在文献 [23] 中提 出的批量层次策略,以用户设置的查询延迟阈值 为滑动窗口大小,在 Storm 系统上使用该策略实 现窗格内数据的微批量处理。 2.3 资源配置策略 2.3.1 多管道数据缓存 c1、c2、···、cn 根据微批量数据传输模式,我们以用户定义 的延迟阈值为微批量传输的窗口大小。如图 1 中 间部分所示,窗口内的微批量数据首先通过增量 学习的模型进行参数配置的预测,依次记录需要 调整配置的次数 。针对不同类型 的查询请求,现场调整机制下,以文献 [7] 的实验 结果所示,拓扑任务的调整延迟在 100~300 ms 之 间。本文中,我们以上限 300 ms 当作单次调整的 延迟,设计了多管道数据缓存算法 MPDC(multiple pipeline data cache),如算法 1 所示。 算法 1 MPDC 算法 输入 用户自定义阈值 Tthreshold;单次调整延 迟阈值 Lthreshold; 输出 多个子管道 m。 1) nprediction = 模型预测需要调整配置的次数; 2) nmax = Tthreshold / Lthreshold ; 3) if(nprediction > nmax) 4) ndiff = 统计不同的参数配置个数; 5) if(ndiff < nmax) 6) m = ndiff ; 7) else 8) m = nmax; 9) 选取并行度最高的 nmax 个配置; 10) 随机向 m 个子管道分发并行度低的 ndiff− nmax 个子数据流; 11) end if 12) end if 算法 1 首先以用户定义的延迟阈值作为微批 量传输的窗口大小,在窗口内使用增量学习模型 预测出需要调整参数配置的次数 nprediction(行 1),根 据用户定义的延迟阈值和单次调整拓扑结构的最 大阈值,我们可计算出数据传输子管道的最大值 nmax(行 2)。在调整次数 nprediction 大于子管道最大值 nmax 的情况下,需要统计出 nprediction 个调整次数中 不同的参数配置个数 ndiff(行 4)。如果参数配置个 数 ndiff 小于子管道最大值 nmax,则根据不同的配置 参数,将数据流划分至 ndiff 个子数据流进行处理 (行 5~6)。如果参数配置个数 ndiff 大于子管道最大 值 nmax,则首选选取并行度最高的 nmax 个配置参 数,并将余下的 ndiff−nmax 个子数据流随机向 nmax 个子管道中发送并进行处理 (行 7~10)。此时,按 照并行度高的参数配置策略,在消耗部分过多系 统资源的情况下,可满足用户定义的延迟阈值。 2.3.2 精准查询处理 由于我们使用子管道的数据处理方式,数据 流通过 MPDC 算法后,各个子管道内的数据流并 非按照时间顺序排序。因此,我们需要完成原始 数据流的精准查询处理。如图 2 所示,我们在流 处理系统之上构筑基于元组时间戳的映射函数, 将不同子管道数据流的处理过程通过哈希映射 后,确保输出精准的查询结果。 第 6 期 王春凯,等:易变数据流的系统资源配置方法 ·1281·