正在加载图片...
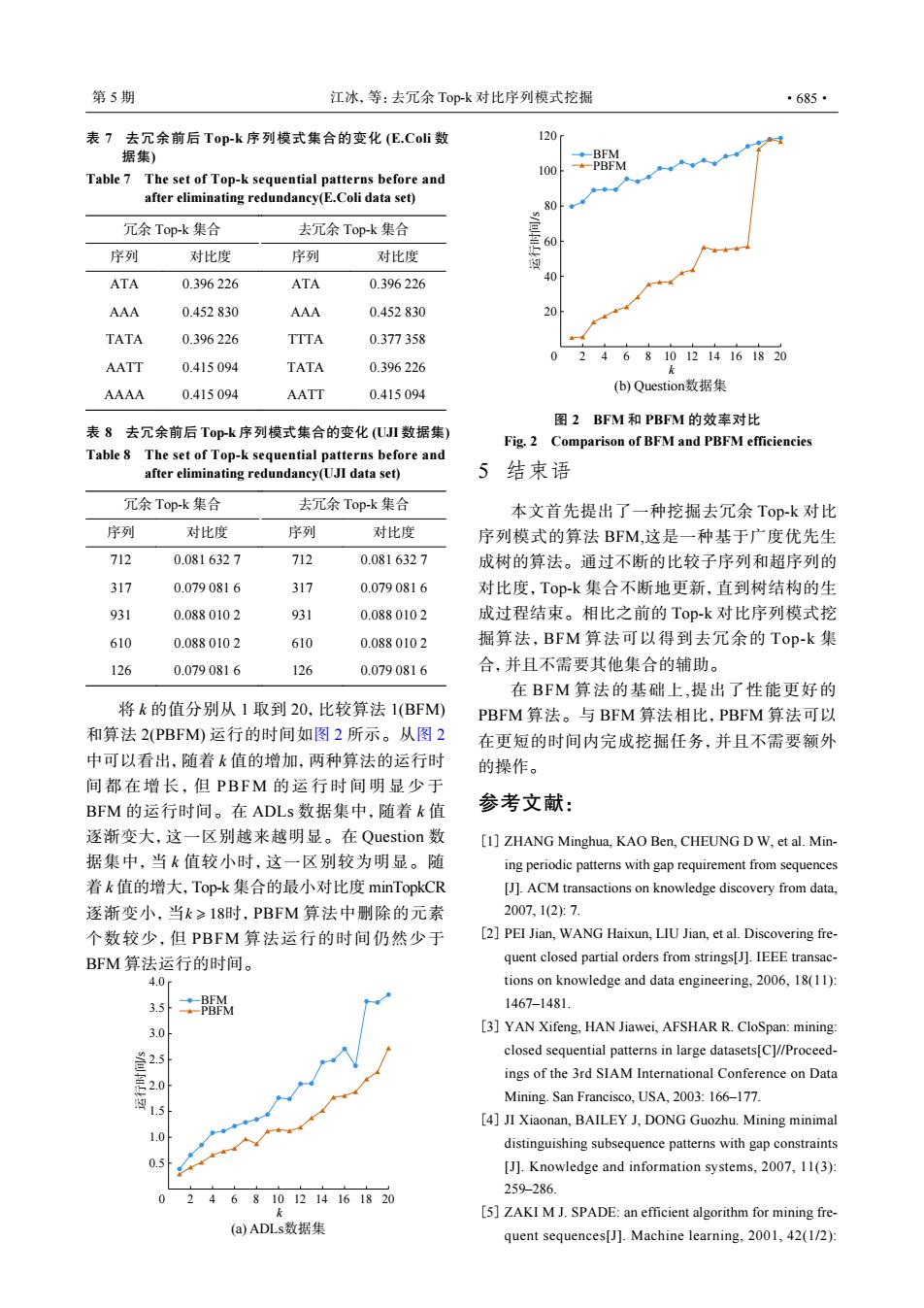
第5期 江冰,等:去冗余Top-k对比序列模式挖掘 ·685· 表7去冗余前后Top-k序列模式集合的变化(E.Coli数 120 据集) ◆-BFM Table 7 The set of Top-k sequential patterns before and 100 *-PBFM after eliminating redundancy(E.Coli data set) 冗余Top-k集合 去冗余Top-k集合 序列 对比度 序列 对比度 ATA 0.396226 ATA 0.396226 40 AAA 0.452830 AAA 0.452830 20 TATA 0.396226 TTTA 0.377358 2468101214161820 AATT 0.415094 TATA 0.396226 AAAA 0.415094 AATT 0.415094 (b)Question数据集 图2BFM和PBFM的效率对比 表8去冗余前后Top-k序列模式集合的变化(UJI数据集) Fig.2 Comparison of BFM and PBFM efficiencies Table 8 The set of Top-k sequential patterns before and after eliminating redundancy(UJI data set) 结束语 冗余Top-k集合 去冗余Top-k集合 本文首先提出了一种挖掘去冗余Top-k对比 序列 对比度 序列 对比度 序列模式的算法BFM,这是一种基于广度优先生 712 0.0816327 712 0.0816327 成树的算法。通过不断的比较子序列和超序列的 317 0.0790816 317 0.0790816 对比度,Top-k集合不断地更新,直到树结构的生 931 0.0880102 931 0.0880102 成过程结束。相比之前的Top-k对比序列模式挖 610 0.0880102 610 0.0880102 掘算法,BFM算法可以得到去冗余的Top-k集 126 0.0790816 126 0.0790816 合,并且不需要其他集合的辅助。 在BFM算法的基础上,提出了性能更好的 将k的值分别从1取到20,比较算法1(BFM) PBFM算法。与BFM算法相比,PBFM算法可以 和算法2(PBFM)运行的时间如图2所示。从图2 在更短的时间内完成挖掘任务,并且不需要额外 中可以看出,随着k值的增加,两种算法的运行时 的操作。 间都在增长,但PBFM的运行时间明显少于 BFM的运行时间。在ADLs数据集中,随着k值 参考文献: 逐渐变大,这一区别越来越明显。在Question数 [1]ZHANG Minghua,KAO Ben,CHEUNG D W,et al.Min- 据集中,当k值较小时,这一区别较为明显。随 ing periodic patterns with gap requirement from sequences 着k值的增大,Top-k集合的最小对比度minTopkCR [J].ACM transactions on knowledge discovery from data. 逐渐变小,当k≥18时,PBFM算法中删除的元素 2007,12):7. 个数较少,但PBFM算法运行的时间仍然少于 [2]PEI Jian,WANG Haixun,LIU Jian,et al.Discovering fre- BFM算法运行的时间。 quent closed partial orders from strings[J].IEEE transac- 4.0r tions on knowledge and data engineering,2006,18(11): 3.5 PBEM 1467-1481. 3.0 [3]YAN Xifeng,HAN Jiawei,AFSHAR R.CloSpan:mining: closed sequential patterns in large datasets[C]//Proceed- ings of the 3rd SIAM International Conference on Data Mining.San Francisco,USA,2003:166-177. 1.5 [4]JI Xiaonan,BAILEY J,DONG Guozhu.Mining minimal 1.0 distinguishing subsequence patterns with gap constraints 0.5 [J].Knowledge and information systems,2007,11(3): 259-286. 4 68101214161820 [5]ZAKI M J.SPADE:an efficient algorithm for mining fre- (a)ADLs数据集 quent sequences[J].Machine learning,2001,42(1/2):k ⩾ 18 将 k 的值分别从 1 取到 20,比较算法 1(BFM) 和算法 2(PBFM) 运行的时间如图 2 所示。从图 2 中可以看出,随着 k 值的增加,两种算法的运行时 间都在增长, 但 PBFM 的运行时间明显少 于 BFM 的运行时间。在 ADLs 数据集中,随着 k 值 逐渐变大,这一区别越来越明显。在 Question 数 据集中,当 k 值较小时,这一区别较为明显。随 着 k 值的增大,Top-k 集合的最小对比度 minTopkCR 逐渐变小,当 时,PBFM 算法中删除的元素 个数较少,但 PBFM 算法运行的时间仍然少于 BFM 算法运行的时间。 5 结束语 本文首先提出了一种挖掘去冗余 Top-k 对比 序列模式的算法 BFM,这是一种基于广度优先生 成树的算法。通过不断的比较子序列和超序列的 对比度,Top-k 集合不断地更新,直到树结构的生 成过程结束。相比之前的 Top-k 对比序列模式挖 掘算法,BFM 算法可以得到去冗余的 Top-k 集 合,并且不需要其他集合的辅助。 在 BFM 算法的基础上,提出了性能更好的 PBFM 算法。与 BFM 算法相比,PBFM 算法可以 在更短的时间内完成挖掘任务,并且不需要额外 的操作。 参考文献: ZHANG Minghua, KAO Ben, CHEUNG D W, et al. Mining periodic patterns with gap requirement from sequences [J]. ACM transactions on knowledge discovery from data, 2007, 1(2): 7. [1] PEI Jian, WANG Haixun, LIU Jian, et al. Discovering frequent closed partial orders from strings[J]. IEEE transactions on knowledge and data engineering, 2006, 18(11): 1467–1481. [2] YAN Xifeng, HAN Jiawei, AFSHAR R. CloSpan: mining: closed sequential patterns in large datasets[C]//Proceedings of the 3rd SIAM International Conference on Data Mining. San Francisco, USA, 2003: 166–177. [3] JI Xiaonan, BAILEY J, DONG Guozhu. Mining minimal distinguishing subsequence patterns with gap constraints [J]. Knowledge and information systems, 2007, 11(3): 259–286. [4] ZAKI M J. SPADE: an efficient algorithm for mining frequent sequences[J]. Machine learning, 2001, 42(1/2): [5] 表 7 去冗余前后 Top-k 序列模式集合的变化 (E.Coli 数 据集) Table 7 The set of Top-k sequential patterns before and after eliminating redundancy(E.Coli data set) 冗余 Top-k 集合 去冗余 Top-k 集合 序列 对比度 序列 对比度 ATA 0.396 226 ATA 0.396 226 AAA 0.452 830 AAA 0.452 830 TATA 0.396 226 TTTA 0.377 358 AATT 0.415 094 TATA 0.396 226 AAAA 0.415 094 AATT 0.415 094 表 8 去冗余前后 Top-k 序列模式集合的变化 (UJI 数据集) Table 8 The set of Top-k sequential patterns before and after eliminating redundancy(UJI data set) 冗余 Top-k 集合 去冗余 Top-k 集合 序列 对比度 序列 对比度 712 0.081 632 7 712 0.081 632 7 317 0.079 081 6 317 0.079 081 6 931 0.088 010 2 931 0.088 010 2 610 0.088 010 2 610 0.088 010 2 126 0.079 081 6 126 0.079 081 6 (b) Question数据集 BFM PBFM 120 100 80 60 40 20 运行时间/s 0 2 4 6 8 10 12 14 16 18 20 k 图 2 BFM 和 PBFM 的效率对比 Fig. 2 Comparison of BFM and PBFM efficiencies (a) ADLs数据集 BFM PBFM 4.0 3.5 3.0 2.5 2.0 1.5 1.0 0.5 运行时间/s 0 2 4 6 8 10 12 14 16 18 20 k 第 5 期 江冰,等:去冗余 Top-k 对比序列模式挖掘 ·685·