正在加载图片...
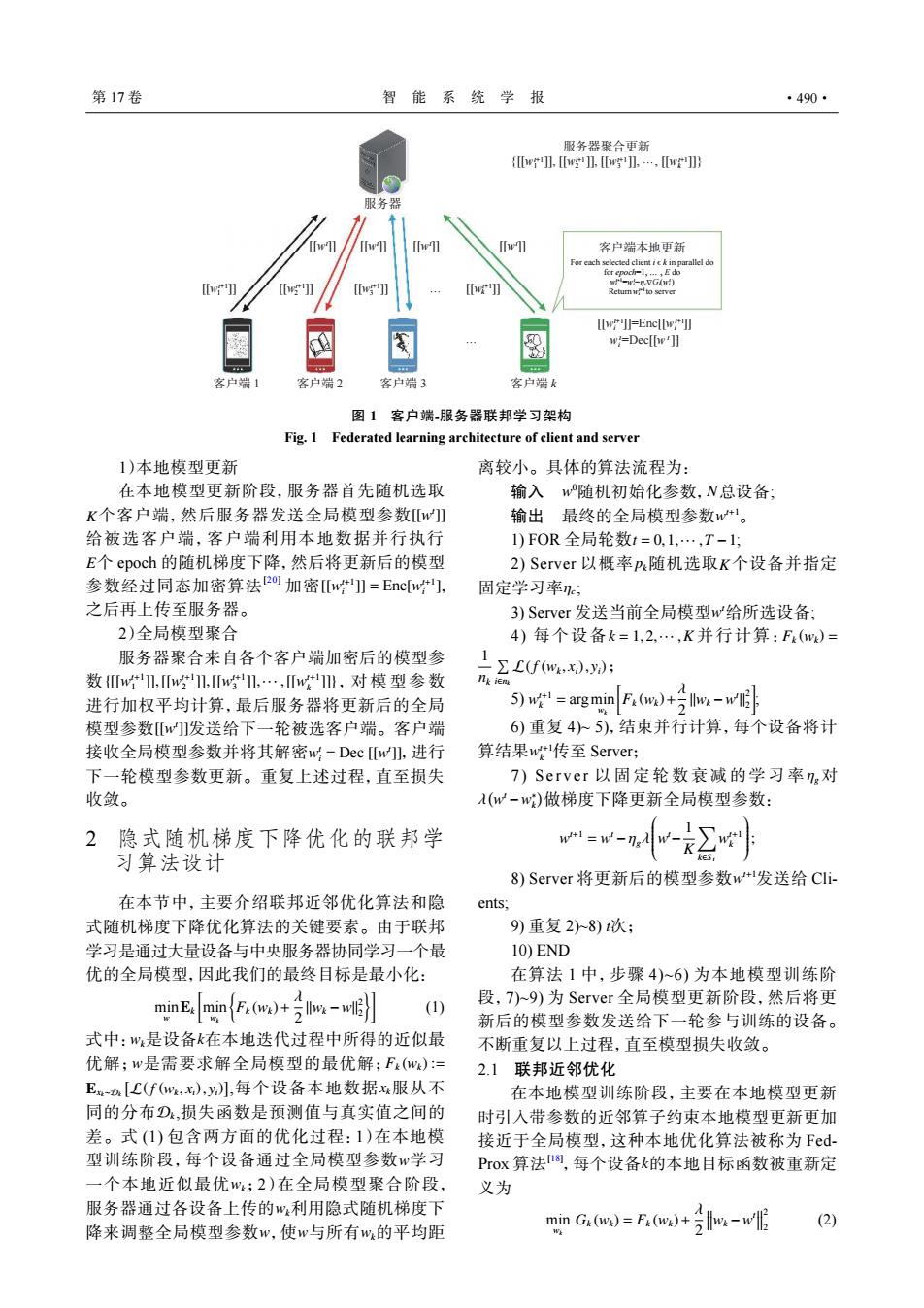
第17卷 智能系统学报 ·490· 服务器聚合更新 {w】wg】wg】,…,wr 服务器 [w] [w]] [w] [w]] 客户端本地更新 For each selected clientick in parallel do [] [w]]=Enc[[w 0 w=Dec[[p']] 客户端1 客户端2 客户端3 客户端k 图1客户端-服务器联邦学习架构 Fig.1 Federated learning architecture of client and server 1)本地模型更新 离较小。具体的算法流程为: 在本地模型更新阶段,服务器首先随机选取 输入w随机初始化参数,N总设备: K个客户端,然后服务器发送全局模型参数[w 输出最终的全局模型参数w。 给被选客户端,客户端利用本地数据并行执行 1)FOR全局轮数t=0,1,…,T-1; E个epoch的随机梯度下降,然后将更新后的模型 2)Server以概率p随机选取K个设备并指定 参数经过同态加密算法2o加密w】=Encw], 固定学习率; 之后再上传至服务器。 3)Server发送当前全局模型w给所选设备; 2)全局模型聚合 4)每个设备k=1,2,…,K并行计算:F(w)= 服务器聚合来自各个客户端加密后的模型参 数{w,w]】,[w],…,w]》,对模型参数 (f(wxy) 几ke 进行加权平均计算,最后服务器将更新后的全局 5)w!-arg min F.(m)hv 模型参数[]发送给下一轮被选客户端。客户端 6)重复4人5),结束并行计算,每个设备将计 接收全局模型参数并将其解密w=Dec[w],进行 算结果w传至Server; 下一轮模型参数更新。重复上述过程,直至损失 7)Server以固定轮数衰减的学习率n,对 收敛。 (w-w)做梯度下降更新全局模型参数: 2隐式随机梯度下降优化的联邦学 w+1=w- 习算法设计 - 8)Server将更新后的模型参数w+1发送给CIi- 在本节中,主要介绍联邦近邻优化算法和隐 ents: 式随机梯度下降优化算法的关键要素。由于联邦 9)重复28)t次; 学习是通过大量设备与中央服务器协同学习一个最 10)END 优的全局模型,因此我们的最终目标是最小化: 在算法1中,步骤4)~6)为本地模型训练阶 minEminF()+w 段,7)~9)为Server全局模型更新阶段,然后将更 (1) 新后的模型参数发送给下一轮参与训练的设备。 式中:w是设备k在本地迭代过程中所得的近似最 不断重复以上过程,直至模型损失收敛。 优解;w是需要求解全局模型的最优解;F(w)= 2.1联邦近邻优化 En[C(f(w,x),y】,每个设备本地数据x服从不 在本地模型训练阶段,主要在本地模型更新 同的分布D,损失函数是预测值与真实值之间的 时引入带参数的近邻算子约束本地模型更新更加 差。式(1)包含两方面的优化过程:1)在本地模 接近于全局模型,这种本地优化算法被称为Fed- 型训练阶段,每个设备通过全局模型参数w学习 PrOx算法8,每个设备k的本地目标函数被重新定 一个本地近似最优w;2)在全局模型聚合阶段, 义为 服务器通过各设备上传的w利用隐式随机梯度下 minG.ow)=Fa(w)+号-wG (2) 降来调整全局模型参数w,使w与所有w,的平均距服务器 {[[w1 ]], [[w2 ]], [[w3 ]], …, [[wk ]]} t+1 t+1 t+1 t+1 [[wt ]] [[wt ]] [[wt ]] [[wt ]] [[wt+1 [[w ]] t+1 [[w 3 ]] k t+1]] 2 [[wt+1]] 1 客户端 1 客户端 2 客户端 3 客户端 k … … 客户端本地更新 For each selected client i ϵ k in parallel do for epoch=1, … , E do wt+1 i =wi−ηc t Δ G t i(wi ) Returnwi t+1to server t+1 t+1 [[wi ]]=Enc[[wi ]] t t wi =Dec[[w ]] 服务器聚合更新 图 1 客户端-服务器联邦学习架构 Fig. 1 Federated learning architecture of client and server 1)本地模型更新 K [[w t ]] E [[w t+1 i ]] = Enc[w t+1 i ] 在本地模型更新阶段,服务器首先随机选取 个客户端,然后服务器发送全局模型参数 给被选客户端,客户端利用本地数据并行执行 个 epoch 的随机梯度下降,然后将更新后的模型 参数经过同态加密算法[20] 加密 , 之后再上传至服务器。 2)全局模型聚合 {[[w t+1 1 ]],[[w t+1 2 ]],[[w t+1 3 ]],··· ,[[w t+1 k ]]} [[w t ]] w t i = Dec [[w t ]] 服务器聚合来自各个客户端加密后的模型参 数 ,对模型参数 进行加权平均计算,最后服务器将更新后的全局 模型参数 发送给下一轮被选客户端。客户端 接收全局模型参数并将其解密 ,进行 下一轮模型参数更新。重复上述过程,直至损失 收敛。 2 隐式随机梯度下降优化的联邦学 习算法设计 在本节中,主要介绍联邦近邻优化算法和隐 式随机梯度下降优化算法的关键要素。由于联邦 学习是通过大量设备与中央服务器协同学习一个最 优的全局模型,因此我们的最终目标是最小化: min w Ek [ min wk { Fk (wk)+ λ 2 ∥wk −w∥ 2 2 }] (1) wk k w Fk (wk) := Exk∼Dk [ L(f (wk , xi), yi) ] xk Dk w wk wk w w wk 式中: 是设备 在本地迭代过程中所得的近似最 优解; 是需要求解全局模型的最优解; ,每个设备本地数据 服从不 同的分布 ,损失函数是预测值与真实值之间的 差。式 (1) 包含两方面的优化过程:1)在本地模 型训练阶段,每个设备通过全局模型参数 学习 一个本地近似最优 ;2)在全局模型聚合阶段, 服务器通过各设备上传的 利用隐式随机梯度下 降来调整全局模型参数 ,使 与所有 的平均距 离较小。具体的算法流程为: w 0 输入 随机初始化参数, N 总设备; w 输出 最终的全局模型参数 t+1。 1) FOR 全局轮数 t = 0,1,··· ,T −1 ; pk K ηc 2) Server 以概率 随机选取 个设备并指定 固定学习率 ; w t 3) Server 发送当前全局模型 给所选设备; k = 1,2,··· ,K Fk (wk) = 1 nk ∑ i∈nk L(f (wk , xi), yi) 4) 每个设备 并行计算: ; w t+1 k = argmin wk [ Fk (wk)+ λ 2 ∥wk −w t ∥ 2 2 ] 5) ; w t+1 k 6) 重复 4)~ 5),结束并行计算,每个设备将计 算结果 传至 Server; ηg λ ( w t −w ∗ k ) 7) Serve r 以固定轮数衰减的学习率 对 做梯度下降更新全局模型参数: w t+1 = w t −ηgλ w t− 1 K ∑ k∈S t w t+1 k ; w t+1 8) Server 将更新后的模型参数 发送给 Clients; 9) 重复 2)~8) t 次; 10) END 在算法 1 中,步骤 4)~6) 为本地模型训练阶 段,7)~9) 为 Server 全局模型更新阶段,然后将更 新后的模型参数发送给下一轮参与训练的设备。 不断重复以上过程,直至模型损失收敛。 2.1 联邦近邻优化 k 在本地模型训练阶段,主要在本地模型更新 时引入带参数的近邻算子约束本地模型更新更加 接近于全局模型,这种本地优化算法被称为 FedProx 算法[18] ,每个设备 的本地目标函数被重新定 义为 min wk Gk (wk) = Fk (wk)+ λ 2 wk −w t 2 2 (2) 第 17 卷 智 能 系 统 学 报 ·490·