正在加载图片...
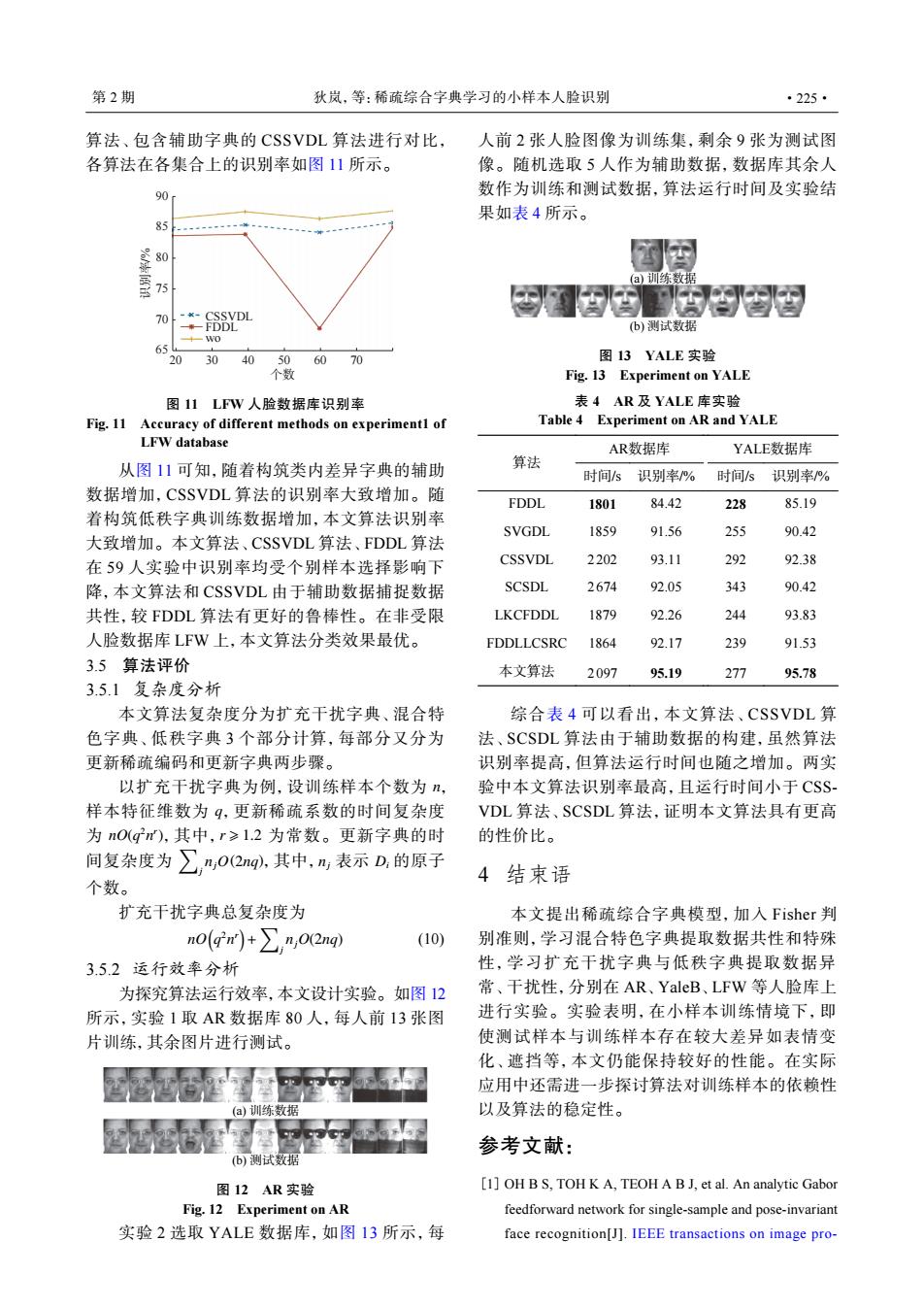
第2期 狄岚,等:稀疏综合字典学习的小样本人脸识别 ·225· 算法、包含辅助字典的CSSVDL算法进行对比, 人前2张人脸图像为训练集,剩余9张为测试图 各算法在各集合上的识别率如图11所示。 像。随机选取5人作为辅助数据,数据库其余人 90 数作为训练和测试数据,算法运行时间及实验结 果如表4所示。 85 80 (a)训练数据 70 -*-CSSVDL 一F)) (b)测试数据 Wo 65 20 3040506070 图13YALE实验 个数 Fig.13 Experiment on YALE 图11LFW人脸数据库识别率 表4AR及YALE库实验 Fig.11 Accuracy of different methods on experimentl of Table 4 Experiment on AR and YALE LFW database AR数据库 YALE数据库 从图11可知,随着构筑类内差异字典的辅助 算法 时间s 识别率% 时间s识别率% 数据增加,CSSVDL算法的识别率大致增加。随 FDDL 1801 84.42 228 85.19 着构筑低秩字典训练数据增加,本文算法识别率 SVGDL 1859 91.56 255 90.42 大致增加。本文算法、CSSVDL算法、FDDL算法 在59人实验中识别率均受个别样本选择影响下 CSSVDL 2202 93.11 292 92.38 降,本文算法和CSSVDL由于辅助数据捕捉数据 SCSDL 2674 92.05 343 90.42 共性,较FDDL算法有更好的鲁棒性。在非受限 LKCFDDL 1879 92.26 244 93.83 人脸数据库LFW上,本文算法分类效果最优, FDDLLCSRC 1864 92.17 239 91.53 3.5算法评价 本文算法 2097 95.19 277 95.78 3.5.1复杂度分析 本文算法复杂度分为扩充干扰字典、混合特 综合表4可以看出,本文算法、CSSVDL算 色字典、低秩字典3个部分计算,每部分又分为 法、SCSDL算法由于辅助数据的构建,虽然算法 更新稀疏编码和更新字典两步骤。 识别率提高,但算法运行时间也随之增加。两实 以扩充干扰字典为例,设训练样本个数为n, 验中本文算法识别率最高,且运行时间小于CS$- 样本特征维数为9,更新稀疏系数的时间复杂度 VDL算法、SCSDL算法,证明本文算法具有更高 为nO(qm),其中,r≥1.2为常数。更新字典的时 的性价比。 间复杂度为∑,n,02mg.其中,m表示D,的原子 4结束语 个数。 扩充干扰字典总复杂度为 本文提出稀疏综合字典模型,加入Fisher判 n0(r)+∑n,02mg) (10) 别准则,学习混合特色字典提取数据共性和特殊 3.5.2运行效率分析 性,学习扩充干扰字典与低秩字典提取数据异 为探究算法运行效率,本文设计实验。如图12 常、干扰性,分别在AR、YaleB、LFW等人脸库上 所示,实验1取AR数据库80人,每人前13张图 进行实验。实验表明,在小样本训练情境下,即 片训练,其余图片进行测试。 使测试样本与训练样本存在较大差异如表情变 化、遮挡等,本文仍能保持较好的性能。在实际 应用中还需进一步探讨算法对训练样本的依赖性 a)训练数据 以及算法的稳定性。 参考文献: (b)测试数据 图12AR实验 [1]OH B S.TOH K A.TEOH A B J,et al.An analytic Gabor Fig.12 Experiment on AR feedforward network for single-sample and pose-invariant 实验2选取YALE数据库,如图13所示,每 face recognition[J].IEEE transactions on image pro-算法、包含辅助字典的 CSSVDL 算法进行对比, 各算法在各集合上的识别率如图 11 所示。 CSSVDL FDDL wo 90 85 80 75 70 65 20 30 40 50 60 70 识别率/% 个数 图 11 LFW 人脸数据库识别率 Fig. 11 Accuracy of different methods on experiment1 of LFW database 从图 11 可知,随着构筑类内差异字典的辅助 数据增加,CSSVDL 算法的识别率大致增加。随 着构筑低秩字典训练数据增加,本文算法识别率 大致增加。本文算法、CSSVDL 算法、FDDL 算法 在 59 人实验中识别率均受个别样本选择影响下 降,本文算法和 CSSVDL 由于辅助数据捕捉数据 共性,较 FDDL 算法有更好的鲁棒性。在非受限 人脸数据库 LFW 上,本文算法分类效果最优。 3.5 算法评价 3.5.1 复杂度分析 本文算法复杂度分为扩充干扰字典、混合特 色字典、低秩字典 3 个部分计算,每部分又分为 更新稀疏编码和更新字典两步骤。 n q nO(q 2n r ) ∑ r ⩾ 1.2 j njO(2nq) nj Di 以扩充干扰字典为例,设训练样本个数为 , 样本特征维数为 ,更新稀疏系数的时间复杂度 为 ,其中, 为常数。更新字典的时 间复杂度为 ,其中, 表示 的原子 个数。 扩充干扰字典总复杂度为 nO( q 2 n r ) + ∑ j njO(2nq) (10) 3.5.2 运行效率分析 为探究算法运行效率,本文设计实验。如图 12 所示,实验 1 取 AR 数据库 80 人,每人前 13 张图 片训练,其余图片进行测试。 (a) 训练数据 (b) 测试数据 图 12 AR 实验 Fig. 12 Experiment on AR 实验 2 选取 YALE 数据库,如图 13 所示,每 人前 2 张人脸图像为训练集,剩余 9 张为测试图 像。随机选取 5 人作为辅助数据,数据库其余人 数作为训练和测试数据,算法运行时间及实验结 果如表 4 所示。 (a) 训练数据 (b) 测试数据 图 13 YALE 实验 Fig. 13 Experiment on YALE 表 4 AR 及 YALE 库实验 Table 4 Experiment on AR and YALE 算法 AR数据库 YALE数据库 时间/s 识别率/% 时间/s 识别率/% FDDL 1801 84.42 228 85.19 SVGDL 1859 91.56 255 90.42 CSSVDL 2 202 93.11 292 92.38 SCSDL 2 674 92.05 343 90.42 LKCFDDL 1879 92.26 244 93.83 FDDLLCSRC 1864 92.17 239 91.53 本文算法 2 097 95.19 277 95.78 综合表 4 可以看出,本文算法、CSSVDL 算 法、SCSDL 算法由于辅助数据的构建,虽然算法 识别率提高,但算法运行时间也随之增加。两实 验中本文算法识别率最高,且运行时间小于 CSSVDL 算法、SCSDL 算法,证明本文算法具有更高 的性价比。 4 结束语 本文提出稀疏综合字典模型,加入 Fisher 判 别准则,学习混合特色字典提取数据共性和特殊 性,学习扩充干扰字典与低秩字典提取数据异 常、干扰性,分别在 AR、YaleB、LFW 等人脸库上 进行实验。实验表明,在小样本训练情境下,即 使测试样本与训练样本存在较大差异如表情变 化、遮挡等,本文仍能保持较好的性能。在实际 应用中还需进一步探讨算法对训练样本的依赖性 以及算法的稳定性。 参考文献: OH B S, TOH K A, TEOH A B J, et al. An analytic Gabor feedforward network for single-sample and pose-invariant face recognition[J]. IEEE transactions on image pro- [1] 第 2 期 狄岚,等:稀疏综合字典学习的小样本人脸识别 ·225·