正在加载图片...
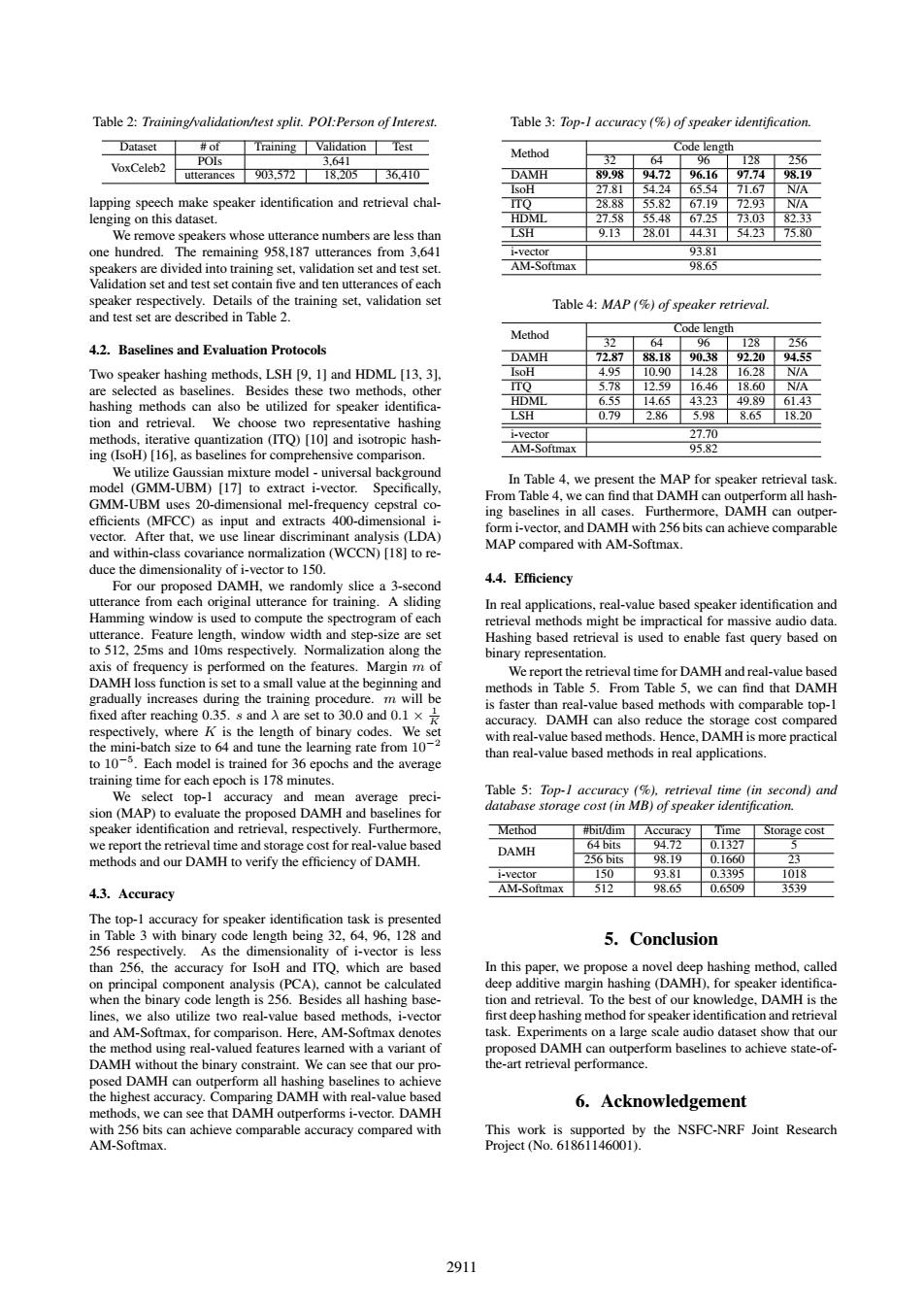
Table 2:Training/validation/test split.POl:Person of Interest Table 3:Top-I accuracy (%of speaker identification Dataset of Training Validation Test Method Code length POIs 3641 3 64 96 128 256 VoxCeleb2 utterances903.57218,20536.410 DAMH 89.9894.7296.1697.7498.19 IsoH 27.81 54.2465.54 71.67 NIA lapping speech make speaker identification and retrieval chal- 父85)6710 7793 N/A lenging on this dataset. HDML 2758 .55.48672573.038233 We remove speakers whose utterance numbers are less than LSH 9.13 28.0144.3154.2375.80 one hundred.The remaining 958.187 utterances from 3.641 i-vector 93.81 speakers are divided into training set,validation set and test set. AM-Softmax 98.65 Validation set and test set contain five and ten utterances of each speaker respectively.Details of the training set,validation set Table 4:MAP (%of speaker retrieval. and test set are described in Table 2. Method Code length 32 4.2.Baselines and Evaluation Protocols 64 96 128 256 DAMH 72.87 88.1890.3892.20 0455 Two speaker hashing methods,LSH [9.1]and HDML [13,3] IsoH 4.95 10.9014.2816.28 N/A are selected as baselines.Besides these two methods,other Io 5.78 12.5916.46 18.60 N/A hashing methods can also be utilized for speaker identifica- HDMI 6.55 14.6543.23 49.8961.43 LSH 0.79 286 5.98 8.65 18.20 tion and retrieval.We choose two representative hashing methods,iterative quantization (ITQ)[10]and isotropic hash- i-vector 27.70 AM-Softmax 9582 ing (IsoH)[16],as baselines for comprehensive comparison. We utilize Gaussian mixture model-universal background In Table 4,we present the MAP for speaker retrieval task model (GMM-UBM)[17]to extract i-vector. Specifically, From Table 4.we can find that DAMH can outperform all hash- GMM-UBM uses 20-dimensional mel-frequency cepstral co- ing baselines in all cases.Furthermore,DAMH can outper- efficients (MFCC)as input and extracts 400-dimensional i- form i-vector,and DAMH with 256 bits can achieve comparable vector.After that,we use linear discriminant analysis (LDA) MAP compared with AM-Softmax. and within-class covariance normalization (WCCN)[18]to re- duce the dimensionality of i-vector to 150. 4.4.Efficiency For our proposed DAMH,we randomly slice a 3-second utterance from each original utterance for training.A sliding In real applications,real-value based speaker identification and Hamming window is used to compute the spectrogram of each retrieval methods might be impractical for massive audio data. utterance.Feature length,window width and step-size are set Hashing based retrieval is used to enable fast query based on to 512,25ms and 10ms respectively.Normalization along the binary representation. axis of frequency is performed on the features.Margin m of We report the retrieval time for DAMH and real-value based DAMH loss function is set to a small value at the beginning and methods in Table 5.From Table 5.we can find that DAMH gradually increases during the training procedure.m will be is faster than real-value based methods with comparable top-1 fixed after reaching 0.35.s and A are set to 30.0 and 0.1 x accuracy.DAMH can also reduce the storage cost compared respectively,where K is the length of binary codes.We set the mini-batch size to 64 and tune the learning rate from 10-2 with real-value based methods.Hence,DAMH is more practical than real-value based methods in real applications. to 10-5.Each model is trained for 36 epochs and the average training time for each epoch is 178 minutes. We select top-1 accuracy and mean average preci- Table 5:Top-I accuracy (%)retrieval time (in second)and sion (MAP)to evaluate the proposed DAMH and baselines for database storage cost (in MB)of speaker identification. speaker identification and retrieval,respectively.Furthermore. Method #bit/dim Accuracy Time Storage cost we report the retrieval time and storage cost for real-value based 64 bits DAMH 94.72 0.1327 methods and our DAMH to verify the efficiency of DAMH. 256 bits 98.19 0.1660 23 i-vector 150 9381 03395 1018 4.3.Accuracy AM-Softmax 512 98.65 0.6509 3539 The top-1 accuracy for speaker identification task is presented in Table 3 with binary code length being 32,64,96.128 and 5.Conclusion 256 respectively.As the dimensionality of i-vector is less than 256,the accuracy for IsoH and ITQ,which are based In this paper,we propose a novel deep hashing method,called on principal component analysis(PCA),cannot be calculated deep additive margin hashing (DAMH),for speaker identifica- when the binary code length is 256.Besides all hashing base- tion and retrieval.To the best of our knowledge,DAMH is the lines,we also utilize two real-value based methods,i-vector first deep hashing method for speaker identification and retrieval and AM-Softmax,for comparison.Here,AM-Softmax denotes task.Experiments on a large scale audio dataset show that our the method using real-valued features learned with a variant of proposed DAMH can outperform baselines to achieve state-of- DAMH without the binary constraint.We can see that our pro- the-art retrieval performance. posed DAMH can outperform all hashing baselines to achieve the highest accuracy.Comparing DAMH with real-value based 6.Acknowledgement methods,we can see that DAMH outperforms i-vector.DAMH with 256 bits can achieve comparable accuracy compared with This work is supported by the NSFC-NRF Joint Research AM-Softmax. Project(No.61861146001). 2911Table 2: Training/validation/test split. POI:Person of Interest. Dataset # of Training Validation Test VoxCeleb2 POIs 3,641 utterances 903,572 18,205 36,410 lapping speech make speaker identification and retrieval challenging on this dataset. We remove speakers whose utterance numbers are less than one hundred. The remaining 958,187 utterances from 3,641 speakers are divided into training set, validation set and test set. Validation set and test set contain five and ten utterances of each speaker respectively. Details of the training set, validation set and test set are described in Table 2. 4.2. Baselines and Evaluation Protocols Two speaker hashing methods, LSH [9, 1] and HDML [13, 3], are selected as baselines. Besides these two methods, other hashing methods can also be utilized for speaker identification and retrieval. We choose two representative hashing methods, iterative quantization (ITQ) [10] and isotropic hashing (IsoH) [16], as baselines for comprehensive comparison. We utilize Gaussian mixture model - universal background model (GMM-UBM) [17] to extract i-vector. Specifically, GMM-UBM uses 20-dimensional mel-frequency cepstral coefficients (MFCC) as input and extracts 400-dimensional ivector. After that, we use linear discriminant analysis (LDA) and within-class covariance normalization (WCCN) [18] to reduce the dimensionality of i-vector to 150. For our proposed DAMH, we randomly slice a 3-second utterance from each original utterance for training. A sliding Hamming window is used to compute the spectrogram of each utterance. Feature length, window width and step-size are set to 512, 25ms and 10ms respectively. Normalization along the axis of frequency is performed on the features. Margin m of DAMH loss function is set to a small value at the beginning and gradually increases during the training procedure. m will be fixed after reaching 0.35. s and λ are set to 30.0 and 0.1 × 1 K respectively, where K is the length of binary codes. We set the mini-batch size to 64 and tune the learning rate from 10−2 to 10−5 . Each model is trained for 36 epochs and the average training time for each epoch is 178 minutes. We select top-1 accuracy and mean average precision (MAP) to evaluate the proposed DAMH and baselines for speaker identification and retrieval, respectively. Furthermore, we report the retrieval time and storage cost for real-value based methods and our DAMH to verify the efficiency of DAMH. 4.3. Accuracy The top-1 accuracy for speaker identification task is presented in Table 3 with binary code length being 32, 64, 96, 128 and 256 respectively. As the dimensionality of i-vector is less than 256, the accuracy for IsoH and ITQ, which are based on principal component analysis (PCA), cannot be calculated when the binary code length is 256. Besides all hashing baselines, we also utilize two real-value based methods, i-vector and AM-Softmax, for comparison. Here, AM-Softmax denotes the method using real-valued features learned with a variant of DAMH without the binary constraint. We can see that our proposed DAMH can outperform all hashing baselines to achieve the highest accuracy. Comparing DAMH with real-value based methods, we can see that DAMH outperforms i-vector. DAMH with 256 bits can achieve comparable accuracy compared with AM-Softmax. Table 3: Top-1 accuracy (%) of speaker identification. Method Code length 32 64 96 128 256 DAMH 89.98 94.72 96.16 97.74 98.19 IsoH 27.81 54.24 65.54 71.67 N/A ITQ 28.88 55.82 67.19 72.93 N/A HDML 27.58 55.48 67.25 73.03 82.33 LSH 9.13 28.01 44.31 54.23 75.80 i-vector 93.81 AM-Softmax 98.65 Table 4: MAP (%) of speaker retrieval. Method Code length 32 64 96 128 256 DAMH 72.87 88.18 90.38 92.20 94.55 IsoH 4.95 10.90 14.28 16.28 N/A ITQ 5.78 12.59 16.46 18.60 N/A HDML 6.55 14.65 43.23 49.89 61.43 LSH 0.79 2.86 5.98 8.65 18.20 i-vector 27.70 AM-Softmax 95.82 In Table 4, we present the MAP for speaker retrieval task. From Table 4, we can find that DAMH can outperform all hashing baselines in all cases. Furthermore, DAMH can outperform i-vector, and DAMH with 256 bits can achieve comparable MAP compared with AM-Softmax. 4.4. Efficiency In real applications, real-value based speaker identification and retrieval methods might be impractical for massive audio data. Hashing based retrieval is used to enable fast query based on binary representation. We report the retrieval time for DAMH and real-value based methods in Table 5. From Table 5, we can find that DAMH is faster than real-value based methods with comparable top-1 accuracy. DAMH can also reduce the storage cost compared with real-value based methods. Hence, DAMH is more practical than real-value based methods in real applications. Table 5: Top-1 accuracy (%), retrieval time (in second) and database storage cost (in MB) of speaker identification. Method #bit/dim Accuracy Time Storage cost DAMH 64 bits 94.72 0.1327 5 256 bits 98.19 0.1660 23 i-vector 150 93.81 0.3395 1018 AM-Softmax 512 98.65 0.6509 3539 5. Conclusion In this paper, we propose a novel deep hashing method, called deep additive margin hashing (DAMH), for speaker identification and retrieval. To the best of our knowledge, DAMH is the first deep hashing method for speaker identification and retrieval task. Experiments on a large scale audio dataset show that our proposed DAMH can outperform baselines to achieve state-ofthe-art retrieval performance. 6. Acknowledgement This work is supported by the NSFC-NRF Joint Research Project (No. 61861146001). 2911