正在加载图片...
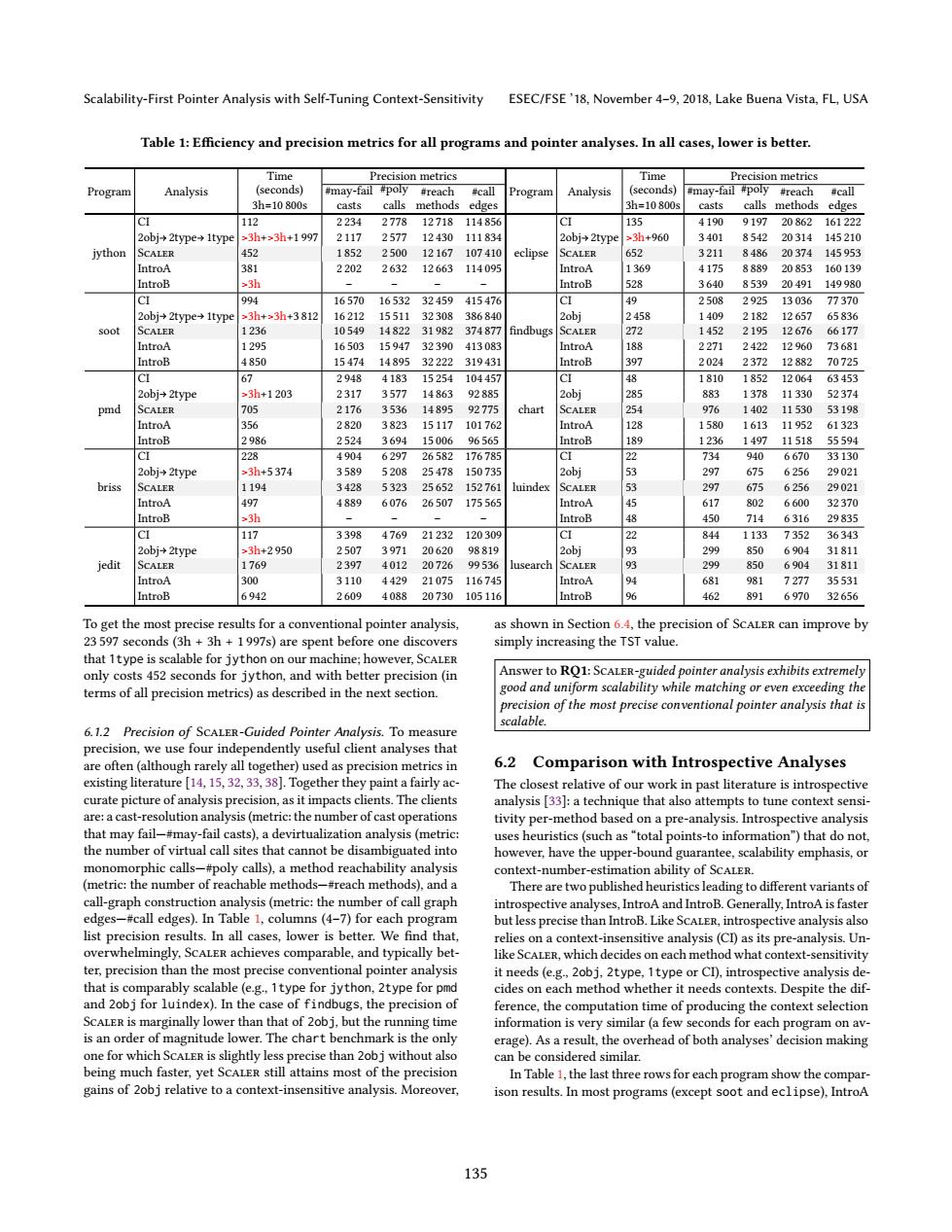
Scalability-First Pointer Analysis with Self-Tuning Context-Sensitivity ESEC/FSE'18.November 4-9,2018,Lake Buena Vista.FL,USA Table 1:Efficiency and precision metrics for all programs and pointer analyses.In all cases,lower is better. Time Precision metrics Time Precision metrics Progran Analysis (seconds) #may-fail #poly #reach #call Program Analysis (seconds) #may-fail #poly #reach #call 3h=10800s casts calls methods edges 3h=10800s casts calls methods edges CI 112 2234 2778 12718 114856 CI 135 4190 9197 20862161222 2obj+2type→1typd 3h+>3h+1997 2117 2577 12430111834 2obj2type ≥3h+960 3401 8542 20314145210 jython SCALER 452 1852 250012167 107410 eclipse SCALER 652 3211 848620374145953 IntroA 381 2202 2632 12663 114095 IntroA 1369 4175 888920853 160139 IntroB 23h IntroB 528 3640 853920491 149980 CI 994 16570 16532 32459 415476 CI 49 2508 292513036 77370 2obj+2type1type >3h+3h+3812 16212 15511 32308 386840 2458 1409 2182 12657 65836 soot SCALER 1236 10549 14822 31982 374877 findbugs SCALER 272 1452 2195 12676 66177 IntroA 1295 16503 15947 32390 413083 IntroA 188 2271 2422 12960 73681 IntroB 4850 15474 14895 32222 319431 IntroB 397 2024 2372 12882 70725 CI 67 2948 4183 15254 104457 CI 48 1810 1852 12064 63453 2obj+2type >3h+1203 2317 3577 14863 92885 2obj 285 883 1378 11330 52374 pmd SCALER 705 2176 3536 14895 92775 chart SCALER 254 976 1402 11530 53198 IntroA 356 2820 3823 15117 101762 IntroA 128 1580 1613 11952 61323 IntroB 2986 2524 3694 15006 96565 IntroB 189 1236 1497 11518 55594 CI 228 4904 6297 26582176785 CI 22 734 940 6670 33130 2obj+2type 33h+5374 3589 5208 25478 150735 2obj 53 297 675 6256 29021 briss SCALER 1194 3428 5323 25652 152761 luindex SCALER 5 297 675 6256 29021 IntroA 497 4889 6076 26507 175565 IntroA 45 617 802 6600 32370 IntroB ≥3弘 IntroB 8 450 714 6316 29835 CI 117 3398 4769 21232120309 CI 22 844 1133 7352 36343 2obj+2type 3h+2950 2507 3971 20620 98819 2obj 93 299 850 6904 31811 jedit SCALER 1769 2397 4012 20726 99536 lusearch SCALER 93 299 850 6904 31811 IntroA 300 3110 442921075116745 IntroA 94 681 981 7277 35531 IntroB 6942 2609 408820730105116 IntroB 462 891 6970 32656 To get the most precise results for a conventional pointer analysis, as shown in Section 6.4,the precision of SCALER can improve by 23 597 seconds (3h 3h 1997s)are spent before one discovers simply increasing the TST value. that 1type is scalable for jython on our machine;however,SCALER only costs 452 seconds for jython,and with better precision(in Answer to RQ1:SCALER-guided pointer analysis exhibits extremely terms of all precision metrics)as described in the next section. good and uniform scalability while matching or even exceeding the precision of the most precise conventional pointer analysis that is scalable 6.1.2 Precision of SCALER-Guided Pointer Analysis.To measure precision,we use four independently useful client analyses that are often(although rarely all together)used as precision metrics in 6.2 Comparison with Introspective Analyses existing literature [14,15,32,33,38].Together they paint a fairly ac- The closest relative of our work in past literature is introspective curate picture of analysis precision,as it impacts clients.The clients analysis [33]:a technique that also attempts to tune context sensi- are:a cast-resolution analysis(metric:the number of cast operations tivity per-method based on a pre-analysis.Introspective analysis that may fail-#may-fail casts),a devirtualization analysis(metric uses heuristics(such as "total points-to information")that do not, the number of virtual call sites that cannot be disambiguated into however,have the upper-bound guarantee,scalability emphasis,or monomorphic calls-#poly calls),a method reachability analysis context-number-estimation ability of SCALER (metric:the number of reachable methods-#reach methods),and a There are two published heuristics leading to different variants of call-graph construction analysis (metric:the number of call graph introspective analyses,IntroA and IntroB.Generally,IntroA is faster edges-#call edges).In Table 1,columns(4-7)for each program but less precise than IntroB.Like SCALER,introspective analysis also list precision results.In all cases,lower is better.We find that. relies on a context-insensitive analysis(CI)as its pre-analysis.Un- overwhelmingly,ScALER achieves comparable,and typically bet- like SCALER,which decides on each method what context-sensitivity ter,precision than the most precise conventional pointer analysis it needs(e.g.,2obj.2type,1type or CI),introspective analysis de- that is comparably scalable(e.g..1type for jython,2type for pmd cides on each method whether it needs contexts.Despite the dif- and 2obj for luindex).In the case of findbugs,the precision of ference,the computation time of producing the context selection SCALER is marginally lower than that of 2obj,but the running time information is very similar (a few seconds for each program on av- is an order of magnitude lower.The chart benchmark is the only erage).As a result,the overhead of both analyses'decision making one for which SCALER is slightly less precise than 2obj without also can be considered similar. being much faster,yet ScALER still attains most of the precision In Table 1,the last three rows for each program show the compar- gains of 2obj relative to a context-insensitive analysis.Moreover, ison results.In most programs(except soot and eclipse),IntroA 135Scalability-First Pointer Analysis with Self-Tuning Context-Sensitivity ESEC/FSE ’18, November 4–9, 2018, Lake Buena Vista, FL, USA Table 1: Efficiency and precision metrics for all programs and pointer analyses. In all cases, lower is better. Program Analysis Time (seconds) 3h=10 800s Precision metrics Program Analysis Time (seconds) 3h=10 800s Precision metrics #may-fail casts #poly calls #reach methods #call edges #may-fail casts #poly calls #reach methods #call edges CI 112 2 234 2 778 12 718 114 856 CI 135 4 190 9 197 20 862 161 222 2obj 2type 1type >3h+>3h+1 997 2 117 2 577 12 430 111 834 2obj 2type >3h+960 3 401 8 542 20 314 145 210 jython Scaler 452 1 852 2 500 12 167 107 410 eclipse Scaler 652 3 211 8 486 20 374 145 953 IntroA 381 2 202 2 632 12 663 114 095 IntroA 1 369 4 175 8 889 20 853 160 139 IntroB >3h ś ś ś ś IntroB 528 3 640 8 539 20 491 149 980 CI 994 16 570 16 532 32 459 415 476 CI 49 2 508 2 925 13 036 77 370 2obj 2type 1type >3h+>3h+3 812 16 212 15 511 32 308 386 840 2obj 2 458 1 409 2 182 12 657 65 836 soot Scaler 1 236 10 549 14 822 31 982 374 877 findbugs Scaler 272 1 452 2 195 12 676 66 177 IntroA 1 295 16 503 15 947 32 390 413 083 IntroA 188 2 271 2 422 12 960 73 681 IntroB 4 850 15 474 14 895 32 222 319 431 IntroB 397 2 024 2 372 12 882 70 725 CI 67 2 948 4 183 15 254 104 457 CI 48 1 810 1 852 12 064 63 453 2obj 2type >3h+1 203 2 317 3 577 14 863 92 885 2obj 285 883 1 378 11 330 52 374 pmd Scaler 705 2 176 3 536 14 895 92 775 chart Scaler 254 976 1 402 11 530 53 198 IntroA 356 2 820 3 823 15 117 101 762 IntroA 128 1 580 1 613 11 952 61 323 IntroB 2 986 2 524 3 694 15 006 96 565 IntroB 189 1 236 1 497 11 518 55 594 CI 228 4 904 6 297 26 582 176 785 CI 22 734 940 6 670 33 130 2obj 2type >3h+5 374 3 589 5 208 25 478 150 735 2obj 53 297 675 6 256 29 021 briss Scaler 1 194 3 428 5 323 25 652 152 761 luindex Scaler 53 297 675 6 256 29 021 IntroA 497 4 889 6 076 26 507 175 565 IntroA 45 617 802 6 600 32 370 IntroB >3h ś ś ś ś IntroB 48 450 714 6 316 29 835 CI 117 3 398 4 769 21 232 120 309 CI 22 844 1 133 7 352 36 343 2obj 2type >3h+2 950 2 507 3 971 20 620 98 819 2obj 93 299 850 6 904 31 811 jedit Scaler 1 769 2 397 4 012 20 726 99 536 lusearch Scaler 93 299 850 6 904 31 811 IntroA 300 3 110 4 429 21 075 116 745 IntroA 94 681 981 7 277 35 531 IntroB 6 942 2 609 4 088 20 730 105 116 IntroB 96 462 891 6 970 32 656 To get the most precise results for a conventional pointer analysis, 23 597 seconds (3h + 3h + 1 997s) are spent before one discovers that 1type is scalable for jython on our machine; however, Scaler only costs 452 seconds for jython, and with better precision (in terms of all precision metrics) as described in the next section. 6.1.2 Precision of Scaler-Guided Pointer Analysis. To measure precision, we use four independently useful client analyses that are often (although rarely all together) used as precision metrics in existing literature [14, 15, 32, 33, 38]. Together they paint a fairly accurate picture of analysis precision, as it impacts clients. The clients are: a cast-resolution analysis (metric: the number of cast operations that may failÐ#may-fail casts), a devirtualization analysis (metric: the number of virtual call sites that cannot be disambiguated into monomorphic callsÐ#poly calls), a method reachability analysis (metric: the number of reachable methodsÐ#reach methods), and a call-graph construction analysis (metric: the number of call graph edgesÐ#call edges). In Table 1, columns (4ś7) for each program list precision results. In all cases, lower is better. We find that, overwhelmingly, Scaler achieves comparable, and typically better, precision than the most precise conventional pointer analysis that is comparably scalable (e.g., 1type for jython, 2type for pmd and 2obj for luindex). In the case of findbugs, the precision of Scaler is marginally lower than that of 2obj, but the running time is an order of magnitude lower. The chart benchmark is the only one for which Scaler is slightly less precise than 2obj without also being much faster, yet Scaler still attains most of the precision gains of 2obj relative to a context-insensitive analysis. Moreover, as shown in Section 6.4, the precision of Scaler can improve by simply increasing the TST value. Answer to RQ1: Scaler-guided pointer analysis exhibits extremely good and uniform scalability while matching or even exceeding the precision of the most precise conventional pointer analysis that is scalable. 6.2 Comparison with Introspective Analyses The closest relative of our work in past literature is introspective analysis [33]: a technique that also attempts to tune context sensitivity per-method based on a pre-analysis. Introspective analysis uses heuristics (such as łtotal points-to informationž) that do not, however, have the upper-bound guarantee, scalability emphasis, or context-number-estimation ability of Scaler. There are two published heuristics leading to different variants of introspective analyses, IntroA and IntroB. Generally, IntroA is faster but less precise than IntroB. Like Scaler, introspective analysis also relies on a context-insensitive analysis (CI) as its pre-analysis. Unlike Scaler, which decides on each method what context-sensitivity it needs (e.g., 2obj, 2type, 1type or CI), introspective analysis decides on each method whether it needs contexts. Despite the difference, the computation time of producing the context selection information is very similar (a few seconds for each program on average). As a result, the overhead of both analyses’ decision making can be considered similar. In Table 1, the last three rows for each program show the comparison results. In most programs (except soot and eclipse), IntroA 135