正在加载图片...
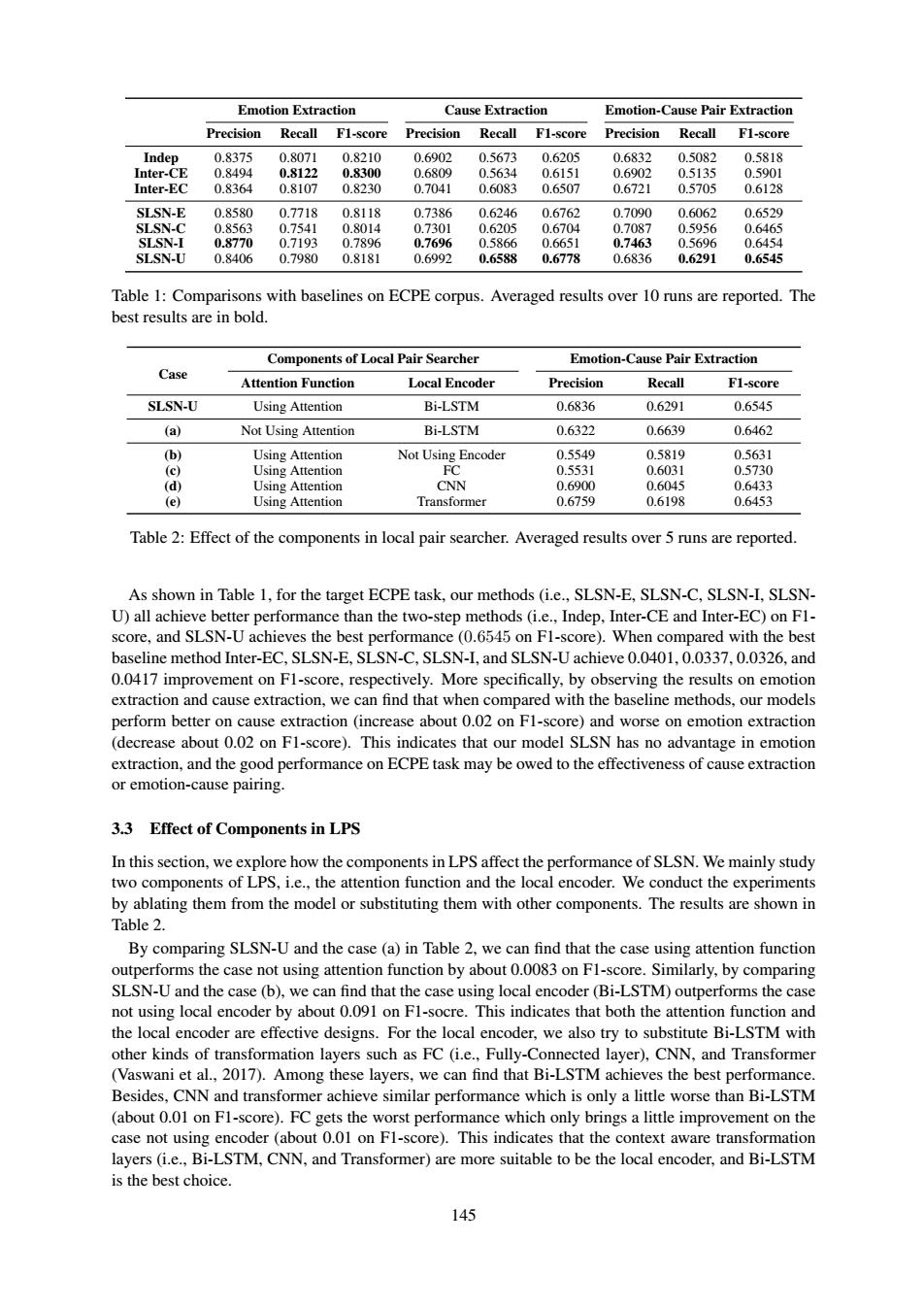
Emotion Extraction Cause Extraction Emotion-Cause Pair Extraction Precision Recall F1-score Precision Recall F1-score Precision Recall F1-score Indep 0.8375 0.8071 0.8210 0.6902 0.5673 0.6205 0.6832 0.5082 0.5818 Inter-CE 0.8494 0.8122 0.8300 0.6809 0.5634 0.6151 0.6902 0.5135 0.5901 Inter-EC 0.8364 0.8107 0.8230 0.7041 0.6083 0.6507 0.6721 0.5705 0.6128 SLSN-E 0.8580 0.7718 0.8118 0.7386 0.6246 0.6762 0.7090 0.6062 0.6529 SLSN-C 0.8563 0.7541 0.8014 0.7301 0.6205 0.6704 0.7087 0.5956 0.6465 SLSN-I 0.8770 0.7193 0.7896 0.7696 0.5866 0.6651 0.7463 0.5696 0.6454 SLSN-U 0.8406 0.7980 0.8181 0.6992 0.6588 0.6778 0.6836 0.6291 0.6545 Table 1:Comparisons with baselines on ECPE corpus.Averaged results over 10 runs are reported.The best results are in bold. Components of Local Pair Searcher Emotion-Cause Pair Extraction Case Attention Function Local Encoder Precision Recall F1-score SLSN-U Using Attention Bi-LSTM 0.6836 0.6291 0.6545 (a) Not Using Attention Bi-LSTM 0.6322 0.6639 0.6462 (b) Using Attention Not Using Encoder 0.5549 0.5819 0.5631 (c) Using Attention FC 0.5531 0.6031 0.5730 (d) Using Attention CNN 0.6900 0.6045 0.6433 (e) Using Attention Transformer 0.6759 0.6198 0.6453 Table 2:Effect of the components in local pair searcher.Averaged results over 5 runs are reported. As shown in Table 1.for the target ECPE task.our methods (i.e..SLSN-E.SLSN-C,SLSN-I.SLSN- U)all achieve better performance than the two-step methods (i.e.,Indep,Inter-CE and Inter-EC)on F1- score,and SLSN-U achieves the best performance(0.6545 on Fl-score).When compared with the best baseline method Inter-EC,SLSN-E,SLSN-C,SLSN-I,and SLSN-U achieve 0.0401,0.0337,0.0326,and 0.0417 improvement on F1-score,respectively.More specifically,by observing the results on emotion extraction and cause extraction,we can find that when compared with the baseline methods,our models perform better on cause extraction (increase about 0.02 on Fl-score)and worse on emotion extraction (decrease about 0.02 on Fl-score).This indicates that our model SLSN has no advantage in emotion extraction,and the good performance on ECPE task may be owed to the effectiveness of cause extraction or emotion-cause pairing. 3.3 Effect of Components in LPS In this section,we explore how the components in LPS affect the performance of SLSN.We mainly study two components of LPS,i.e.,the attention function and the local encoder.We conduct the experiments by ablating them from the model or substituting them with other components.The results are shown in Table 2. By comparing SLSN-U and the case (a)in Table 2,we can find that the case using attention function outperforms the case not using attention function by about 0.0083 on Fl-score.Similarly,by comparing SLSN-U and the case (b),we can find that the case using local encoder(Bi-LSTM)outperforms the case not using local encoder by about 0.091 on Fl-socre.This indicates that both the attention function and the local encoder are effective designs.For the local encoder,we also try to substitute Bi-LSTM with other kinds of transformation layers such as FC(i.e.,Fully-Connected layer),CNN,and Transformer (Vaswani et al.,2017).Among these layers,we can find that Bi-LSTM achieves the best performance. Besides,CNN and transformer achieve similar performance which is only a little worse than Bi-LSTM (about 0.01 on Fl-score).FC gets the worst performance which only brings a little improvement on the case not using encoder (about 0.01 on F1-score).This indicates that the context aware transformation layers (i.e.,Bi-LSTM,CNN,and Transformer)are more suitable to be the local encoder,and Bi-LSTM is the best choice. 145145 Emotion Extraction Cause Extraction Emotion-Cause Pair Extraction Precision Recall F1-score Precision Recall F1-score Precision Recall F1-score Indep 0.8375 0.8071 0.8210 0.6902 0.5673 0.6205 0.6832 0.5082 0.5818 Inter-CE 0.8494 0.8122 0.8300 0.6809 0.5634 0.6151 0.6902 0.5135 0.5901 Inter-EC 0.8364 0.8107 0.8230 0.7041 0.6083 0.6507 0.6721 0.5705 0.6128 SLSN-E 0.8580 0.7718 0.8118 0.7386 0.6246 0.6762 0.7090 0.6062 0.6529 SLSN-C 0.8563 0.7541 0.8014 0.7301 0.6205 0.6704 0.7087 0.5956 0.6465 SLSN-I 0.8770 0.7193 0.7896 0.7696 0.5866 0.6651 0.7463 0.5696 0.6454 SLSN-U 0.8406 0.7980 0.8181 0.6992 0.6588 0.6778 0.6836 0.6291 0.6545 Table 1: Comparisons with baselines on ECPE corpus. Averaged results over 10 runs are reported. The best results are in bold. Case Components of Local Pair Searcher Emotion-Cause Pair Extraction Attention Function Local Encoder Precision Recall F1-score SLSN-U Using Attention Bi-LSTM 0.6836 0.6291 0.6545 (a) Not Using Attention Bi-LSTM 0.6322 0.6639 0.6462 (b) Using Attention Not Using Encoder 0.5549 0.5819 0.5631 (c) Using Attention FC 0.5531 0.6031 0.5730 (d) Using Attention CNN 0.6900 0.6045 0.6433 (e) Using Attention Transformer 0.6759 0.6198 0.6453 Table 2: Effect of the components in local pair searcher. Averaged results over 5 runs are reported. As shown in Table 1, for the target ECPE task, our methods (i.e., SLSN-E, SLSN-C, SLSN-I, SLSNU) all achieve better performance than the two-step methods (i.e., Indep, Inter-CE and Inter-EC) on F1- score, and SLSN-U achieves the best performance (0.6545 on F1-score). When compared with the best baseline method Inter-EC, SLSN-E, SLSN-C, SLSN-I, and SLSN-U achieve 0.0401, 0.0337, 0.0326, and 0.0417 improvement on F1-score, respectively. More specifically, by observing the results on emotion extraction and cause extraction, we can find that when compared with the baseline methods, our models perform better on cause extraction (increase about 0.02 on F1-score) and worse on emotion extraction (decrease about 0.02 on F1-score). This indicates that our model SLSN has no advantage in emotion extraction, and the good performance on ECPE task may be owed to the effectiveness of cause extraction or emotion-cause pairing. 3.3 Effect of Components in LPS In this section, we explore how the components in LPS affect the performance of SLSN. We mainly study two components of LPS, i.e., the attention function and the local encoder. We conduct the experiments by ablating them from the model or substituting them with other components. The results are shown in Table 2. By comparing SLSN-U and the case (a) in Table 2, we can find that the case using attention function outperforms the case not using attention function by about 0.0083 on F1-score. Similarly, by comparing SLSN-U and the case (b), we can find that the case using local encoder (Bi-LSTM) outperforms the case not using local encoder by about 0.091 on F1-socre. This indicates that both the attention function and the local encoder are effective designs. For the local encoder, we also try to substitute Bi-LSTM with other kinds of transformation layers such as FC (i.e., Fully-Connected layer), CNN, and Transformer (Vaswani et al., 2017). Among these layers, we can find that Bi-LSTM achieves the best performance. Besides, CNN and transformer achieve similar performance which is only a little worse than Bi-LSTM (about 0.01 on F1-score). FC gets the worst performance which only brings a little improvement on the case not using encoder (about 0.01 on F1-score). This indicates that the context aware transformation layers (i.e., Bi-LSTM, CNN, and Transformer) are more suitable to be the local encoder, and Bi-LSTM is the best choice