正在加载图片...
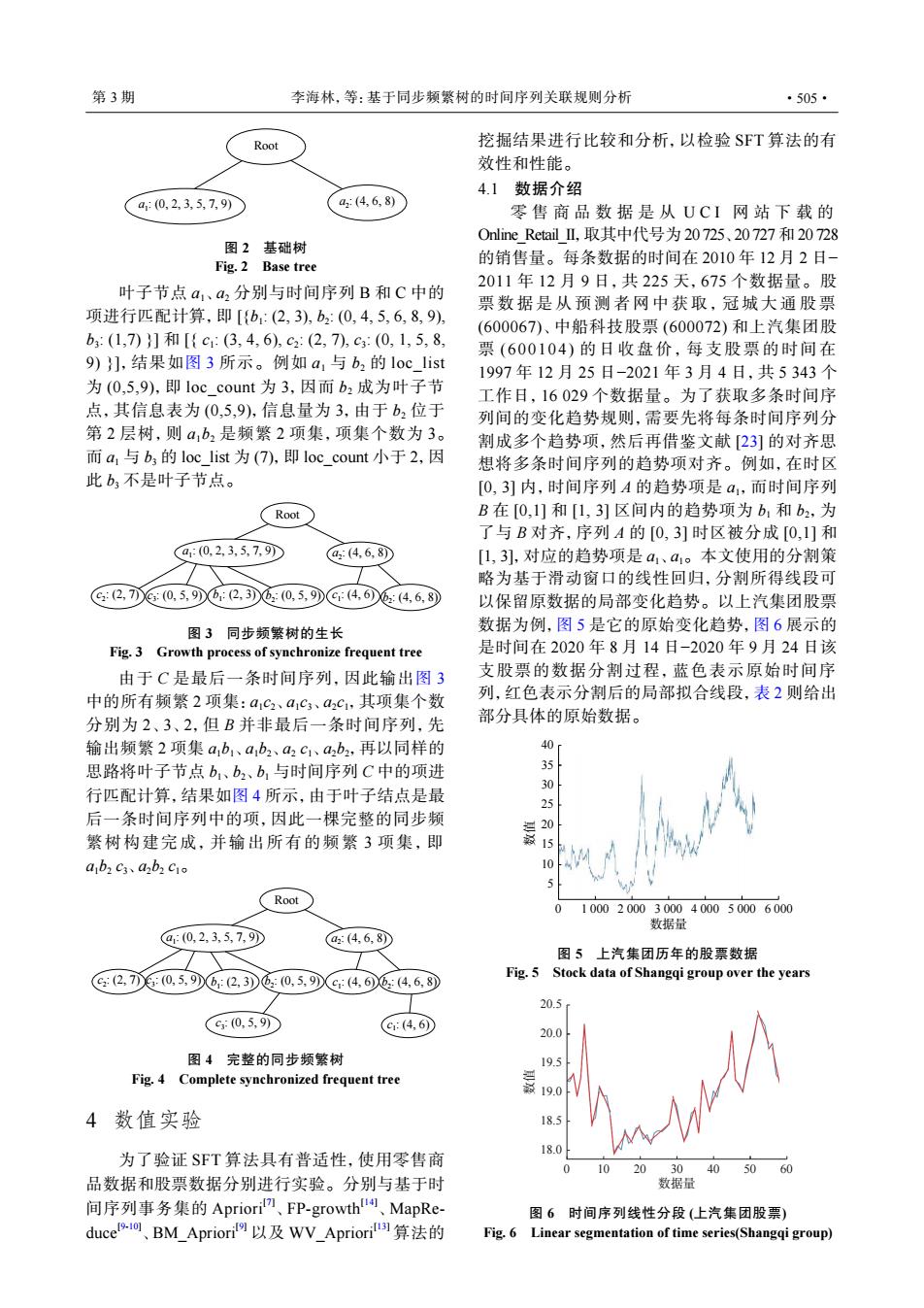
第3期 李海林,等:基于同步频繁树的时间序列关联规则分析 ·505· Root 挖掘结果进行比较和分析,以检验SFT算法的有 效性和性能。 41数据介绍 a:0,2,3,5,7,9y a2(4,6,8) 零售商品数据是从UCI网站下载的 Online RetailⅡ,取其中代号为20725、20727和20728 图2基础树 Fig.2 Base tree 的销售量。每条数据的时间在2010年12月2日- 2011年12月9日,共225天,675个数据量。股 叶子节点a、a2分别与时间序列B和C中的 票数据是从预测者网中获取,冠城大通股票 项进行匹配计算,即[{b:(2,3),b2:0,4,5,6,8,9), (600067)、中船科技股票(600072)和上汽集团股 b:(1,7)}]和[{c:(3,4,6),c2:(2,7),c3:(0,1,5,8, 票(600104)的日收盘价,每支股票的时间在 9)】,结果如图3所示。例如a1与b2的loc_Iist 1997年12月25日-2021年3月4日,共5343个 为(0,5,9),即1 oc count为3,因而b2成为叶子节 工作日,16029个数据量。为了获取多条时间序 点,其信息表为(0,5,9),信息量为3,由于b2位于 列间的变化趋势规则,需要先将每条时间序列分 第2层树,则a1b2是频繁2项集,项集个数为3。 割成多个趋势项,然后再借鉴文献[23]的对齐思 而a,与b3的loc list为(7),即loc_count小于2,因 想将多条时间序列的趋势项对齐。例如,在时区 此b3不是叶子节点。 [0,3】内,时间序列A的趋势项是a1,而时间序列 Root B在[0,1]和[1,3]区间内的趋势项为b1和b2,为 了与B对齐,序列A的[0,3]时区被分成[0,1]和 a1(0,2,3,5,7,9の a:(4,6,8 [1,3引,对应的趋势项是a、a。本文使用的分割策 略为基于滑动窗口的线性回归,分割所得线段可 G:(2,7:0,5,の0:(2,36:0,5,9G年(4,66e:(4,6,8 以保留原数据的局部变化趋势。以上汽集团股票 图3同步频繁树的生长 数据为例,图5是它的原始变化趋势,图6展示的 Fig.3 Growth process of synchronize frequent tree 是时间在2020年8月14日-2020年9月24日该 由于C是最后一条时间序列,因此输出图3 支股票的数据分割过程,蓝色表示原始时间序 中的所有频繁2项集:a1C2、a1c3、a2c1,其项集个数 列,红色表示分割后的局部拟合线段,表2则给出 分别为2、3、2,但B并非最后一条时间序列,先 部分具体的原始数据。 输出频繁2项集ab1、ab2、a2c1、ab2,再以同样的 思路将叶子节点b、b2、b,与时间序列C中的项进 行匹配计算,结果如图4所示,由于叶子结点是最 25 后一条时间序列中的项,因此一棵完整的同步频 繁树构建完成,并输出所有的频繁3项集,即 15 ab2c3、a2b2C1o 10 Root 100020003000400050006000 数据量 @:0,2,3,5,7,9の a2:(4,6,8 图5上汽集团历年的股票数据 G2,70,5,96:(2,3)6:0,5.G4664,68 Fig.5 Stock data of Shangqi group over the years 20.5 G3(0,5,9の C:(4,6) 20.0 图4完整的同步频繁树 19.5 Fig.4 Complete synchronized frequent tree 藏190 4数值实验 8.0 为了验证SFT算法具有普适性,使用零售商 20 304050.60 品数据和股票数据分别进行实验。分别与基于时 数据量 间序列事务集的Apriori、FP-growth、MapRe- 图6时间序列线性分段(上汽集团股票) duce、BM_Apriori9以及WV_Aprior算法的 Fig.6 Linear segmentation of time series(Shangqi group)Root a1 : (0, 2, 3, 5, 7, 9) a2 : (4, 6, 8) 图 2 基础树 Fig. 2 Base tree 叶子节点 a1、a2 分别与时间序列 B 和 C 中的 项进行匹配计算,即 [{b1 : (2, 3), b2 : (0, 4, 5, 6, 8, 9), b3 : (1,7) }] 和 [{ c1 : (3, 4, 6), c2 : (2, 7), c3 : (0, 1, 5, 8, 9) }],结果如图 3 所示。例如 a1 与 b2 的 loc_list 为 (0,5,9),即 loc_count 为 3,因而 b2 成为叶子节 点,其信息表为 (0,5,9),信息量为 3,由于 b2 位于 第 2 层树,则 a1b2 是频繁 2 项集,项集个数为 3。 而 a1 与 b3 的 loc_list 为 (7),即 loc_count 小于 2,因 此 b3 不是叶子节点。 Root a2 : (4, 6, 8) b1 : (2, 3) b2 c2 : (2, 7) c : (0, 5, 9) 3 : (0, 5, 9) a1 : (0, 2, 3, 5, 7, 9) b2 c1 : (4, 6, 8) : (4, 6) 图 3 同步频繁树的生长 Fig. 3 Growth process of synchronize frequent tree 由于 C 是最后一条时间序列,因此输出图 3 中的所有频繁 2 项集:a1c2、a1c3、a2c1,其项集个数 分别为 2、3、2,但 B 并非最后一条时间序列,先 输出频繁 2 项集 a1b1、a1b2、a2 c1、a2b2,再以同样的 思路将叶子节点 b1、b2、b1 与时间序列 C 中的项进 行匹配计算,结果如图 4 所示,由于叶子结点是最 后一条时间序列中的项,因此一棵完整的同步频 繁树构建完成,并输出所有的频繁 3 项集,即 a1b2 c3、a2b2 c1。 Root a2 : (4, 6, 8) b1 : (2, 3) b2 c2 : (2, 7) c3 : (0, 5, 9) : (0, 5, 9) a1 : (0, 2, 3, 5, 7, 9) b2 c : (4, 6, 8) 1 : (4, 6) c3 : (0, 5, 9) c1 : (4, 6) 图 4 完整的同步频繁树 Fig. 4 Complete synchronized frequent tree 4 数值实验 为了验证 SFT 算法具有普适性,使用零售商 品数据和股票数据分别进行实验。分别与基于时 间序列事务集的 Apriori[7] 、FP-growth[14] 、MapReduce[9-10] 、BM_Apriori[9] 以及 WV_Apriori[13] 算法的 挖掘结果进行比较和分析,以检验 SFT 算法的有 效性和性能。 4.1 数据介绍 零售商品数据是 从 UCI 网站下载 的 Online_Retail_II,取其中代号为 20 725、20 727 和 20 728 的销售量。每条数据的时间在 2010 年 12 月 2 日− 2011 年 12 月 9 日,共 225 天,675 个数据量。股 票数据是从预测者网中获取,冠城大通股 票 (600067)、中船科技股票 (600072) 和上汽集团股 票 (600104) 的日收盘价,每支股票的时间在 1997 年 12 月 25 日−2021 年 3 月 4 日,共 5 343 个 工作日,16 029 个数据量。为了获取多条时间序 列间的变化趋势规则,需要先将每条时间序列分 割成多个趋势项,然后再借鉴文献 [23] 的对齐思 想将多条时间序列的趋势项对齐。例如,在时区 [0, 3] 内,时间序列 A 的趋势项是 a1,而时间序列 B 在 [0,1] 和 [1, 3] 区间内的趋势项为 b1 和 b2,为 了与 B 对齐,序列 A 的 [0, 3] 时区被分成 [0,1] 和 [1, 3],对应的趋势项是 a1、a1。本文使用的分割策 略为基于滑动窗口的线性回归,分割所得线段可 以保留原数据的局部变化趋势。以上汽集团股票 数据为例,图 5 是它的原始变化趋势,图 6 展示的 是时间在 2020 年 8 月 14 日−2020 年 9 月 24 日该 支股票的数据分割过程,蓝色表示原始时间序 列,红色表示分割后的局部拟合线段,表 2 则给出 部分具体的原始数据。 35 40 30 25 20 15 10 5 0 1 000 2 000 3 000 4 000 5 000 6 000 数据量 数值 图 5 上汽集团历年的股票数据 Fig. 5 Stock data of Shangqi group over the years 20.0 20.5 19.5 19.0 18.5 18.0 0 10 20 30 40 50 60 数据量 数值 图 6 时间序列线性分段 (上汽集团股票) Fig. 6 Linear segmentation of time series(Shangqi group) 第 3 期 李海林,等:基于同步频繁树的时间序列关联规则分析 ·505·