正在加载图片...
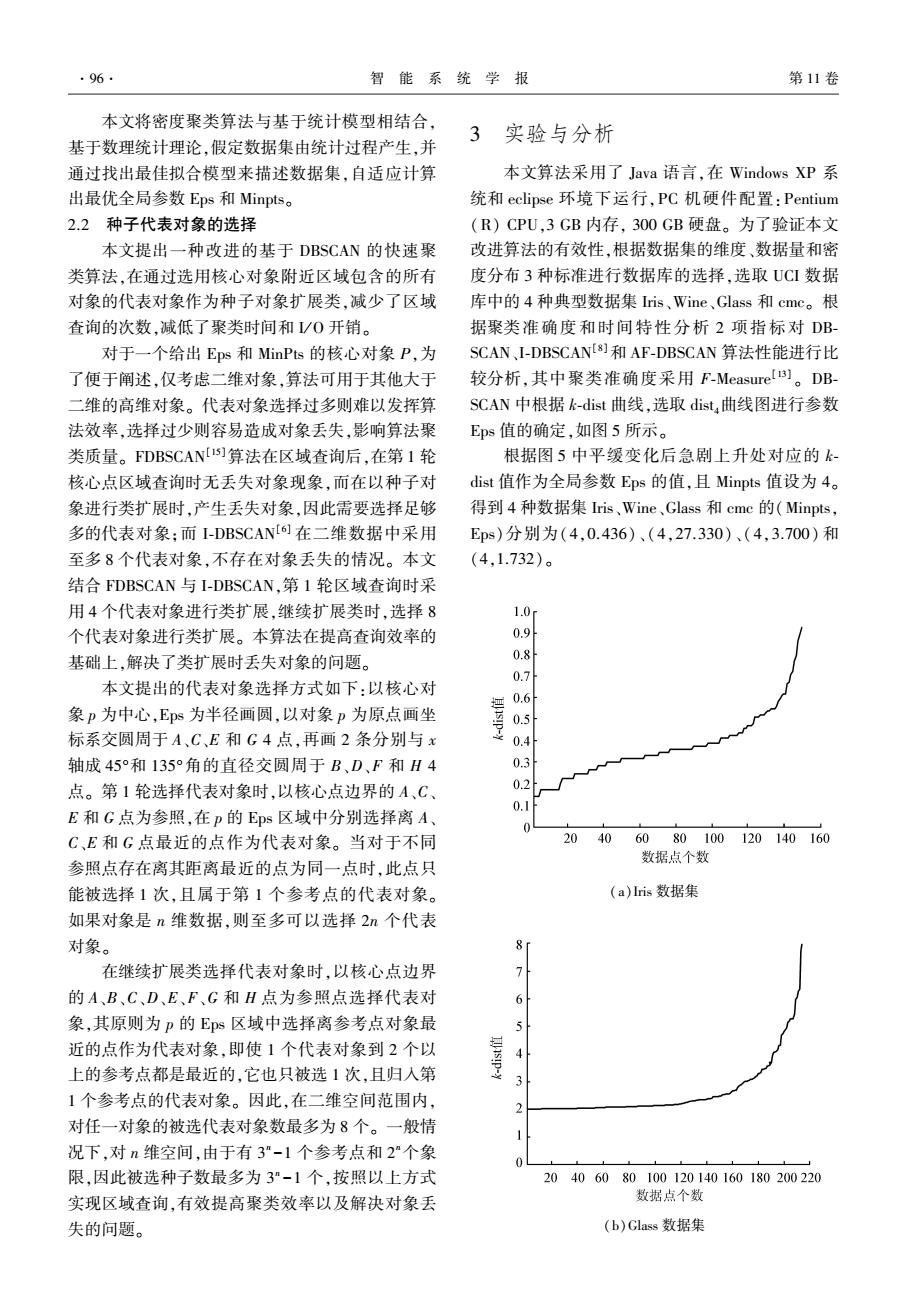
·96. 智能系统学报 第11卷 本文将密度聚类算法与基于统计模型相结合, 3实验与分析 基于数理统计理论,假定数据集由统计过程产生,并 通过找出最佳拟合模型来描述数据集,自适应计算 本文算法采用了Java语言,在Windows XP系 出最优全局参数Eps和Minpts。 统和eclipse环境下运行,PC机硬件配置:Pentium 2.2种子代表对象的选择 (R)CPU,3GB内存,300GB硬盘。为了验证本文 本文提出一种改进的基于DBSCAN的快速聚 改进算法的有效性,根据数据集的维度、数据量和密 类算法,在通过选用核心对象附近区域包含的所有 度分布3种标准进行数据库的选择,选取UCI数据 对象的代表对象作为种子对象扩展类,减少了区域 库中的4种典型数据集ris、Wine、Glass和cmc。根 查询的次数,减低了聚类时间和/0开销。 据聚类准确度和时间特性分析2项指标对DB- 对于一个给出Eps和MinPts的核心对象P,为 SCAN、I-DBSCANU8劉和AF-DBSCAN算法性能进行比 了便于阐述,仅考虑二维对象,算法可用于其他大于 较分析,其中聚类准确度采用F-Measure)。DB- 二维的高维对象。代表对象选择过多则难以发挥算 SCAN中根据k-dist曲线,选取dist,曲线图进行参数 法效率,选择过少则容易造成对象丢失,影响算法聚 Eps值的确定,如图5所示。 类质量。FDBSCAN[5]算法在区域查询后,在第1轮 根据图5中平缓变化后急剧上升处对应的k 核心点区域查询时无丢失对象现象,而在以种子对 dist值作为全局参数Eps的值,且Minpts值设为4。 象进行类扩展时,产生丢失对象,因此需要选择足够 得到4种数据集ris、Wine、Glass和cmc的(Minpts, 多的代表对象:而I-DBSCAN[6]在二维数据中采用 Eps)分别为(4,0.436)、(4,27.330)、(4,3.700)和 至多8个代表对象,不存在对象丢失的情况。本文 (4.1.732)。 结合FDBSCAN与I-DBSCAN,第1轮区域查询时采 用4个代表对象进行类扩展,继续扩展类时,选择8 1.0r 个代表对象进行类扩展。本算法在提高查询效率的 0.9 基础上,解决了类扩展时丢失对象的问题。 0.8 0.7 本文提出的代表对象选择方式如下:以核心对 0.6 象p为中心,Eps为半径画圆,以对象p为原点画坐 0.5 标系交圆周于A、C、E和G4点,再画2条分别与x 0.4 轴成45°和135°角的直径交圆周于B、D、F和H4 0.3 点。第1轮选择代表对象时,以核心点边界的A、C、 0.2 0.1 E和G点为参照,在p的Eps区域中分别选择离A、 0 C、E和G点最近的点作为代表对象。当对于不同 20 40 6080100120140160 数据点个数 参照点存在离其距离最近的点为同一点时,此点只 能被选择1次,且属于第1个参考点的代表对象。 (a)is数据集 如果对象是n维数据,则至多可以选择2n个代表 对象。 8 在继续扩展类选择代表对象时,以核心点边界 7 的A、B、C、D、E、F、G和H点为参照点选择代表对 6 象,其原则为p的Es区域中选择离参考点对象最 5 近的点作为代表对象,即使1个代表对象到2个以 4 上的参考点都是最近的,它也只被选1次,且归入第 3 1个参考点的代表对象。因此,在二维空间范围内, 对任一对象的被选代表对象数最多为8个。一般情 况下,对n维空间,由于有3"-1个参考点和2个象 0 限,因此被选种子数最多为3”-1个,按照以上方式 20406080100120140160180200220 实现区域查询,有效提高聚类效率以及解决对象丢 数据点个数 失的问题。 (b)Glass数据集本文将密度聚类算法与基于统计模型相结合, 基于数理统计理论,假定数据集由统计过程产生,并 通过找出最佳拟合模型来描述数据集,自适应计算 出最优全局参数 Eps 和 Minpts。 2.2 种子代表对象的选择 本文提出一种改进的基于 DBSCAN 的快速聚 类算法,在通过选用核心对象附近区域包含的所有 对象的代表对象作为种子对象扩展类,减少了区域 查询的次数,减低了聚类时间和 I/ O 开销。 对于一个给出 Eps 和 MinPts 的核心对象 P,为 了便于阐述,仅考虑二维对象,算法可用于其他大于 二维的高维对象。 代表对象选择过多则难以发挥算 法效率,选择过少则容易造成对象丢失,影响算法聚 类质量。 FDBSCAN [15]算法在区域查询后,在第 1 轮 核心点区域查询时无丢失对象现象,而在以种子对 象进行类扩展时,产生丢失对象,因此需要选择足够 多的代表对象;而 I⁃DBSCAN [6] 在二维数据中采用 至多 8 个代表对象,不存在对象丢失的情况。 本文 结合 FDBSCAN 与 I⁃DBSCAN,第 1 轮区域查询时采 用 4 个代表对象进行类扩展,继续扩展类时,选择 8 个代表对象进行类扩展。 本算法在提高查询效率的 基础上,解决了类扩展时丢失对象的问题。 本文提出的代表对象选择方式如下:以核心对 象 p 为中心,Eps 为半径画圆,以对象 p 为原点画坐 标系交圆周于 A、C、E 和 G 4 点,再画 2 条分别与 x 轴成 45°和 135°角的直径交圆周于 B、D、F 和 H 4 点。 第 1 轮选择代表对象时,以核心点边界的 A、C、 E 和 G 点为参照,在 p 的 Eps 区域中分别选择离 A、 C、E 和 G 点最近的点作为代表对象。 当对于不同 参照点存在离其距离最近的点为同一点时,此点只 能被选择 1 次,且属于第 1 个参考点的代表对象。 如果对象是 n 维数据,则至多可以选择 2n 个代表 对象。 在继续扩展类选择代表对象时,以核心点边界 的 A、B、C、D、E、F、G 和 H 点为参照点选择代表对 象,其原则为 p 的 Eps 区域中选择离参考点对象最 近的点作为代表对象,即使 1 个代表对象到 2 个以 上的参考点都是最近的,它也只被选 1 次,且归入第 1 个参考点的代表对象。 因此,在二维空间范围内, 对任一对象的被选代表对象数最多为 8 个。 一般情 况下,对 n 维空间,由于有 3 n -1 个参考点和 2 n个象 限,因此被选种子数最多为 3 n -1 个,按照以上方式 实现区域查询,有效提高聚类效率以及解决对象丢 失的问题。 3 实验与分析 本文算法采用了 Java 语言,在 Windows XP 系 统和 eclipse 环境下运行,PC 机硬件配置:Pentium (R) CPU,3 GB 内存, 300 GB 硬盘。 为了验证本文 改进算法的有效性,根据数据集的维度、数据量和密 度分布 3 种标准进行数据库的选择,选取 UCI 数据 库中的 4 种典型数据集 Iris、Wine、Glass 和 cmc。 根 据聚类准确度和时间特性分析 2 项指标对 DB⁃ SCAN、I⁃DBSCAN [8]和 AF⁃DBSCAN 算法性能进行比 较分析,其中聚类准确度采用 F⁃Measure [13] 。 DB⁃ SCAN 中根据 k⁃dist 曲线,选取 dist 4曲线图进行参数 Eps 值的确定,如图 5 所示。 根据图 5 中平缓变化后急剧上升处对应的 k⁃ dist 值作为全局参数 Eps 的值,且 Minpts 值设为 4。 得到 4 种数据集 Iris、Wine、Glass 和 cmc 的(Minpts, Eps)分别为(4,0.436)、(4,27.330)、(4,3.700) 和 (4,1.732)。 (a)Iris 数据集 (b)Glass 数据集 ·96· 智 能 系 统 学 报 第 11 卷