正在加载图片...
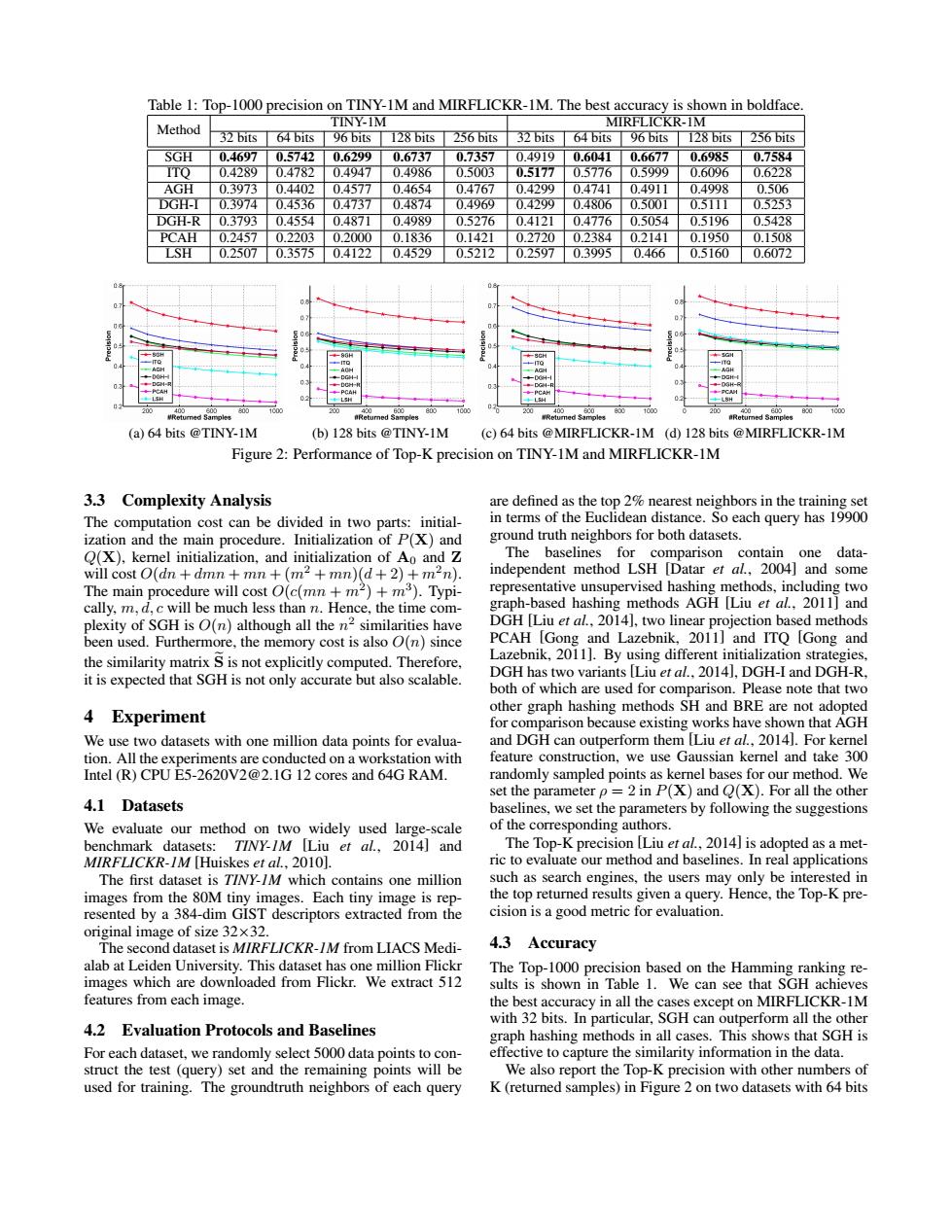
Table 1:Top-1000 precision on TINY-1M and MIRFLICKR-1M.The best accuracy is shown in boldface. Method TINY-IM MIRFLICKR-1M 32 bits 64 bits 96 bits 128 bits 256 bits 32 bits 64 bits 96 bits 128 bits 256 bits SGH 0.4697 0.5742 0.6299 0.6737 0.7357 0.49190.60410.6677 0.6985 0.7584 ITO 0.4289 0.4782 0.4947 0.4986 0.5003 0.5177 0.5776 0.5999 0.6096 0.6228 AGH 0.3973 0.4402 0.4577 0.4654 0.4767 0.4299 0.4741 0.4911 0.4998 0.506 DGH-I 0.3974 0.4536 0.4737 0.4874 0.4969 0.4299 0.4806 0.5001 0.5111 0.5253 DGH-R0.3793 0.4554 0.4871 0.4989 0.5276 0.4121 0.47760.5054 0.5196 0.5428 PCAH 0.2457 0.2203 0.2000 0.1836 0.1421 0.2720 0.2384 0.2141 0.1950 0.1508 LSH 0.2507 0.3575 0.4122 0.4529 0.5212 0.2597 0.3995 0.466 0.5160 0.6072 200 800 200 800 00 200 800 1000 200 (a)64 bits @TINY-1M (b)128 bits @TINY-1M (c)64 bits @MIRFLICKR-1M (d)128 bits @MIRFLICKR-1M Figure 2:Performance of Top-K precision on TINY-1M and MIRFLICKR-1M 3.3 Complexity Analysis are defined as the top 2%nearest neighbors in the training set The computation cost can be divided in two parts:initial- in terms of the Euclidean distance.So each query has 19900 ization and the main procedure.Initialization of P(X)and ground truth neighbors for both datasets. Q(X),kernel initialization,and initialization of Ao and Z The baselines for comparison contain one data- will cost O(dn dmn+mn+(m-+mn)(d+2)+m-n). independent method LSH [Datar et al.,2004]and some The main procedure will cost O(c(mn +m2)+m3).Typi- representative unsupervised hashing methods,including two cally,m,d,c will be much less than n.Hence,the time com- graph-based hashing methods AGH [Liu et al.,2011]and plexity of SGH is O(n)although all the n2 similarities have DGH Liu et al..2014,two linear projection based methods been used.Furthermore,the memory cost is also O(n)since PCAH [Gong and Lazebnik,2011]and ITQ [Gong and the similarity matrix S is not explicitly computed.Therefore, Lazebnik,2011].By using different initialization strategies, it is expected that SGH is not only accurate but also scalable. DGH has two variants [Liu et al.,2014],DGH-I and DGH-R both of which are used for comparison.Please note that two 4 Experiment other graph hashing methods SH and BRE are not adopted for comparison because existing works have shown that AGH We use two datasets with one million data points for evalua- and DGH can outperform them [Liu et al.,2014].For kernel tion.All the experiments are conducted on a workstation with feature construction,we use Gaussian kernel and take 300 Intel(R)CPU E5-2620V2@2.1G 12 cores and 64G RAM. randomly sampled points as kernel bases for our method.We set the parameter p =2 in P(X)and Q(X).For all the other 4.1 Datasets baselines,we set the parameters by following the suggestions We evaluate our method on two widely used large-scale of the corresponding authors. benchmark datasets:TINY-/M Liu et al..2014]and The Top-K precision [Liu et al,2014]is adopted as a met- MIRFLICKR-IM [Huiskes et al..20101. ric to evaluate our method and baselines.In real applications The first dataset is TINY-IM which contains one million such as search engines,the users may only be interested in images from the 80M tiny images.Each tiny image is rep- the top returned results given a query.Hence,the Top-K pre- resented by a 384-dim GIST descriptors extracted from the cision is a good metric for evaluation. original image of size 32x32. The second dataset is MIRFL/CKR-IM from LIACS Medi- 4.3 Accuracy alab at Leiden University.This dataset has one million Flickr The Top-1000 precision based on the Hamming ranking re- images which are downloaded from Flickr.We extract 512 sults is shown in Table 1.We can see that SGH achieves features from each image. the best accuracy in all the cases except on MIRFLICKR-1M with 32 bits.In particular,SGH can outperform all the other 4.2 Evaluation Protocols and Baselines graph hashing methods in all cases.This shows that SGH is For each dataset,we randomly select 5000 data points to con- effective to capture the similarity information in the data. struct the test(query)set and the remaining points will be We also report the Top-K precision with other numbers of used for training.The groundtruth neighbors of each query K(returned samples)in Figure 2 on two datasets with 64 bitsTable 1: Top-1000 precision on TINY-1M and MIRFLICKR-1M. The best accuracy is shown in boldface. Method TINY-1M MIRFLICKR-1M 32 bits 64 bits 96 bits 128 bits 256 bits 32 bits 64 bits 96 bits 128 bits 256 bits SGH 0.4697 0.5742 0.6299 0.6737 0.7357 0.4919 0.6041 0.6677 0.6985 0.7584 ITQ 0.4289 0.4782 0.4947 0.4986 0.5003 0.5177 0.5776 0.5999 0.6096 0.6228 AGH 0.3973 0.4402 0.4577 0.4654 0.4767 0.4299 0.4741 0.4911 0.4998 0.506 DGH-I 0.3974 0.4536 0.4737 0.4874 0.4969 0.4299 0.4806 0.5001 0.5111 0.5253 DGH-R 0.3793 0.4554 0.4871 0.4989 0.5276 0.4121 0.4776 0.5054 0.5196 0.5428 PCAH 0.2457 0.2203 0.2000 0.1836 0.1421 0.2720 0.2384 0.2141 0.1950 0.1508 LSH 0.2507 0.3575 0.4122 0.4529 0.5212 0.2597 0.3995 0.466 0.5160 0.6072 (a) 64 bits @TINY-1M (b) 128 bits @TINY-1M (c) 64 bits @MIRFLICKR-1M (d) 128 bits @MIRFLICKR-1M Figure 2: Performance of Top-K precision on TINY-1M and MIRFLICKR-1M 3.3 Complexity Analysis The computation cost can be divided in two parts: initialization and the main procedure. Initialization of P(X) and Q(X), kernel initialization, and initialization of A0 and Z will cost O(dn + dmn + mn + (m2 + mn)(d + 2) + m2n). The main procedure will cost O(c(mn + m2 ) + m3 ). Typically, m, d, c will be much less than n. Hence, the time complexity of SGH is O(n) although all the n 2 similarities have been used. Furthermore, the memory cost is also O(n) since the similarity matrix Se is not explicitly computed. Therefore, it is expected that SGH is not only accurate but also scalable. 4 Experiment We use two datasets with one million data points for evaluation. All the experiments are conducted on a workstation with Intel (R) CPU E5-2620V2@2.1G 12 cores and 64G RAM. 4.1 Datasets We evaluate our method on two widely used large-scale benchmark datasets: TINY-1M [Liu et al., 2014] and MIRFLICKR-1M [Huiskes et al., 2010]. The first dataset is TINY-1M which contains one million images from the 80M tiny images. Each tiny image is represented by a 384-dim GIST descriptors extracted from the original image of size 32×32. The second dataset is MIRFLICKR-1M from LIACS Medialab at Leiden University. This dataset has one million Flickr images which are downloaded from Flickr. We extract 512 features from each image. 4.2 Evaluation Protocols and Baselines For each dataset, we randomly select 5000 data points to construct the test (query) set and the remaining points will be used for training. The groundtruth neighbors of each query are defined as the top 2% nearest neighbors in the training set in terms of the Euclidean distance. So each query has 19900 ground truth neighbors for both datasets. The baselines for comparison contain one dataindependent method LSH [Datar et al., 2004] and some representative unsupervised hashing methods, including two graph-based hashing methods AGH [Liu et al., 2011] and DGH [Liu et al., 2014], two linear projection based methods PCAH [Gong and Lazebnik, 2011] and ITQ [Gong and Lazebnik, 2011]. By using different initialization strategies, DGH has two variants [Liu et al., 2014], DGH-I and DGH-R, both of which are used for comparison. Please note that two other graph hashing methods SH and BRE are not adopted for comparison because existing works have shown that AGH and DGH can outperform them [Liu et al., 2014]. For kernel feature construction, we use Gaussian kernel and take 300 randomly sampled points as kernel bases for our method. We set the parameter ρ = 2 in P(X) and Q(X). For all the other baselines, we set the parameters by following the suggestions of the corresponding authors. The Top-K precision [Liu et al., 2014] is adopted as a metric to evaluate our method and baselines. In real applications such as search engines, the users may only be interested in the top returned results given a query. Hence, the Top-K precision is a good metric for evaluation. 4.3 Accuracy The Top-1000 precision based on the Hamming ranking results is shown in Table 1. We can see that SGH achieves the best accuracy in all the cases except on MIRFLICKR-1M with 32 bits. In particular, SGH can outperform all the other graph hashing methods in all cases. This shows that SGH is effective to capture the similarity information in the data. We also report the Top-K precision with other numbers of K (returned samples) in Figure 2 on two datasets with 64 bits