正在加载图片...
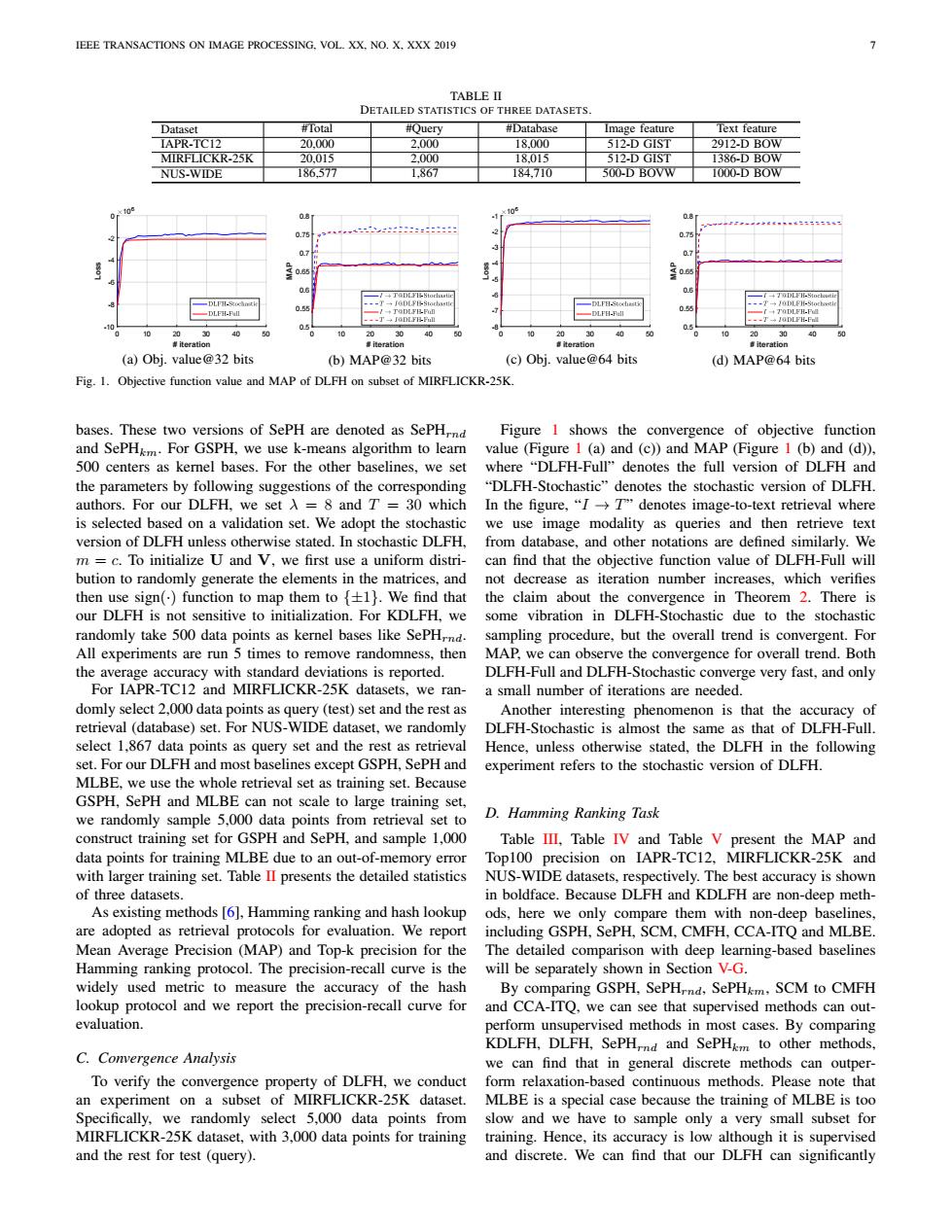
IEEE TRANSACTIONS ON IMAGE PROCESSING.VOL.XX,NO.X.XXX 2019 7 TABLE II DETAILED STATISTICS OF THREE DATASETS Dataset #Total #Query #Database Image feature Text feature IAPR-TC12 20.000 2.000 18.000 512-D GIST 2912.-DB0W MIRFLICKR-25K 20.015 2.000 18.015 512-D GIST 1386-DB0W NUS-WIDE 186.577 1.867 184,710 500-D BOVW 1000-D BOW 106 O.8 。 0.75 75 0.7 TaD[FB-Stochutic 06 TODLEH-Stoche DLFH-Scochitie 0.55 --I一DLPB-Stocbam =DLF日Stodiast ==T→LFH-ort. 一DLF-Fl 于JODLFB-Fn -DLFH-Full 0约 05 20 30 40 50 20 30 40 20 30 40 0 10 0 iteration iteration 意iteratio aiteration (a)Obj.value@32 bits (b)MAP@32 bits (c)Obj.value@64 bits (d)MAP@64 bits Fig.1.Objective function value and MAP of DLFH on subset of MIRFLICKR-25K. bases.These two versions of SePH are denoted as SePHrnd Figure 1 shows the convergence of objective function and SePHkm.For GSPH,we use k-means algorithm to learn value (Figure 1 (a)and (c))and MAP (Figure 1 (b)and (d)). 500 centers as kernel bases.For the other baselines,we set where "DLFH-Full"denotes the full version of DLFH and the parameters by following suggestions of the corresponding "DLFH-Stochastic"denotes the stochastic version of DLFH authors.For our DLFH,we set A=8 and T=30 which In the figure,"I>Tdenotes image-to-text retrieval where is selected based on a validation set.We adopt the stochastic we use image modality as queries and then retrieve text version of DLFH unless otherwise stated.In stochastic DLFH,from database,and other notations are defined similarly.We m=c.To initialize U and V,we first use a uniform distri-can find that the objective function value of DLFH-Full will bution to randomly generate the elements in the matrices,and not decrease as iteration number increases,which verifies then use sign()function to map them to {+1).We find that the claim about the convergence in Theorem 2.There is our DLFH is not sensitive to initialization.For KDLFH.we some vibration in DLFH-Stochastic due to the stochastic randomly take 500 data points as kernel bases like SePHrnd. sampling procedure,but the overall trend is convergent.For All experiments are run 5 times to remove randomness,then MAP,we can observe the convergence for overall trend.Both the average accuracy with standard deviations is reported. DLFH-Full and DLFH-Stochastic converge very fast,and only For IAPR-TC12 and MIRFLICKR-25K datasets,we ran- a small number of iterations are needed. domly select 2,000 data points as query (test)set and the rest as Another interesting phenomenon is that the accuracy of retrieval(database)set.For NUS-WIDE dataset,we randomly DLFH-Stochastic is almost the same as that of DLFH-Full. select 1,867 data points as query set and the rest as retrieval Hence,unless otherwise stated,the DLFH in the following set.For our DLFH and most baselines except GSPH.SePH and experiment refers to the stochastic version of DLFH. MLBE,we use the whole retrieval set as training set.Because GSPH,SePH and MLBE can not scale to large training set, we randomly sample 5,000 data points from retrieval set to D.Hamming Ranking Task construct training set for GSPH and SePH,and sample 1,000 Table III,Table IV and Table V present the MAP and data points for training MLBE due to an out-of-memory error Top100 precision on IAPR-TC12,MIRFLICKR-25K and with larger training set.Table II presents the detailed statistics NUS-WIDE datasets,respectively.The best accuracy is shown of three datasets. in boldface.Because DLFH and KDLFH are non-deep meth- As existing methods [6],Hamming ranking and hash lookup ods,here we only compare them with non-deep baselines, are adopted as retrieval protocols for evaluation.We report including GSPH,SePH,SCM,CMFH,CCA-ITQ and MLBE Mean Average Precision (MAP)and Top-k precision for the The detailed comparison with deep learning-based baselines Hamming ranking protocol.The precision-recall curve is the will be separately shown in Section V-G. widely used metric to measure the accuracy of the hash By comparing GSPH,SePHrnd,SePHkm,SCM to CMFH lookup protocol and we report the precision-recall curve for and CCA-ITQ,we can see that supervised methods can out- evaluation. perform unsupervised methods in most cases.By comparing KDLFH,DLFH,SePH,nd and SePHkm to other methods, C.Convergence Analysis we can find that in general discrete methods can outper- To verify the convergence property of DLFH,we conduct form relaxation-based continuous methods.Please note that an experiment on a subset of MIRFLICKR-25K dataset.MLBE is a special case because the training of MLBE is too Specifically,we randomly select 5,000 data points from slow and we have to sample only a very small subset for MIRFLICKR-25K dataset,with 3,000 data points for training training.Hence,its accuracy is low although it is supervised and the rest for test (query). and discrete.We can find that our DLFH can significantlyIEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. X, XXX 2019 7 TABLE II DETAILED STATISTICS OF THREE DATASETS. Dataset #Total #Query #Database Image feature Text feature IAPR-TC12 20,000 2,000 18,000 512-D GIST 2912-D BOW MIRFLICKR-25K 20,015 2,000 18,015 512-D GIST 1386-D BOW NUS-WIDE 186,577 1,867 184,710 500-D BOVW 1000-D BOW # iteration 0 10 20 30 40 50 L o s s 106 -10 -8 -6 -4 -2 0 (a) Obj. value@32 bits # iteration 0 10 20 30 40 50 M A P 0.5 0.55 0.6 0.65 0.7 0.75 0.8 (b) MAP@32 bits # iteration 0 10 20 30 40 50 L o s s 106 -8 -7 -6 -5 -4 -3 -2 -1 (c) Obj. value@64 bits # iteration 0 10 20 30 40 50 M A P 0.5 0.55 0.6 0.65 0.7 0.75 0.8 (d) MAP@64 bits Fig. 1. Objective function value and MAP of DLFH on subset of MIRFLICKR-25K. bases. These two versions of SePH are denoted as SePHrnd and SePHkm. For GSPH, we use k-means algorithm to learn 500 centers as kernel bases. For the other baselines, we set the parameters by following suggestions of the corresponding authors. For our DLFH, we set λ = 8 and T = 30 which is selected based on a validation set. We adopt the stochastic version of DLFH unless otherwise stated. In stochastic DLFH, m = c. To initialize U and V, we first use a uniform distribution to randomly generate the elements in the matrices, and then use sign(·) function to map them to {±1}. We find that our DLFH is not sensitive to initialization. For KDLFH, we randomly take 500 data points as kernel bases like SePHrnd. All experiments are run 5 times to remove randomness, then the average accuracy with standard deviations is reported. For IAPR-TC12 and MIRFLICKR-25K datasets, we randomly select 2,000 data points as query (test) set and the rest as retrieval (database) set. For NUS-WIDE dataset, we randomly select 1,867 data points as query set and the rest as retrieval set. For our DLFH and most baselines except GSPH, SePH and MLBE, we use the whole retrieval set as training set. Because GSPH, SePH and MLBE can not scale to large training set, we randomly sample 5,000 data points from retrieval set to construct training set for GSPH and SePH, and sample 1,000 data points for training MLBE due to an out-of-memory error with larger training set. Table II presents the detailed statistics of three datasets. As existing methods [6], Hamming ranking and hash lookup are adopted as retrieval protocols for evaluation. We report Mean Average Precision (MAP) and Top-k precision for the Hamming ranking protocol. The precision-recall curve is the widely used metric to measure the accuracy of the hash lookup protocol and we report the precision-recall curve for evaluation. C. Convergence Analysis To verify the convergence property of DLFH, we conduct an experiment on a subset of MIRFLICKR-25K dataset. Specifically, we randomly select 5,000 data points from MIRFLICKR-25K dataset, with 3,000 data points for training and the rest for test (query). Figure 1 shows the convergence of objective function value (Figure 1 (a) and (c)) and MAP (Figure 1 (b) and (d)), where “DLFH-Full” denotes the full version of DLFH and “DLFH-Stochastic” denotes the stochastic version of DLFH. In the figure, “I → T” denotes image-to-text retrieval where we use image modality as queries and then retrieve text from database, and other notations are defined similarly. We can find that the objective function value of DLFH-Full will not decrease as iteration number increases, which verifies the claim about the convergence in Theorem 2. There is some vibration in DLFH-Stochastic due to the stochastic sampling procedure, but the overall trend is convergent. For MAP, we can observe the convergence for overall trend. Both DLFH-Full and DLFH-Stochastic converge very fast, and only a small number of iterations are needed. Another interesting phenomenon is that the accuracy of DLFH-Stochastic is almost the same as that of DLFH-Full. Hence, unless otherwise stated, the DLFH in the following experiment refers to the stochastic version of DLFH. D. Hamming Ranking Task Table III, Table IV and Table V present the MAP and Top100 precision on IAPR-TC12, MIRFLICKR-25K and NUS-WIDE datasets, respectively. The best accuracy is shown in boldface. Because DLFH and KDLFH are non-deep methods, here we only compare them with non-deep baselines, including GSPH, SePH, SCM, CMFH, CCA-ITQ and MLBE. The detailed comparison with deep learning-based baselines will be separately shown in Section V-G. By comparing GSPH, SePHrnd, SePHkm, SCM to CMFH and CCA-ITQ, we can see that supervised methods can outperform unsupervised methods in most cases. By comparing KDLFH, DLFH, SePHrnd and SePHkm to other methods, we can find that in general discrete methods can outperform relaxation-based continuous methods. Please note that MLBE is a special case because the training of MLBE is too slow and we have to sample only a very small subset for training. Hence, its accuracy is low although it is supervised and discrete. We can find that our DLFH can significantly