正在加载图片...
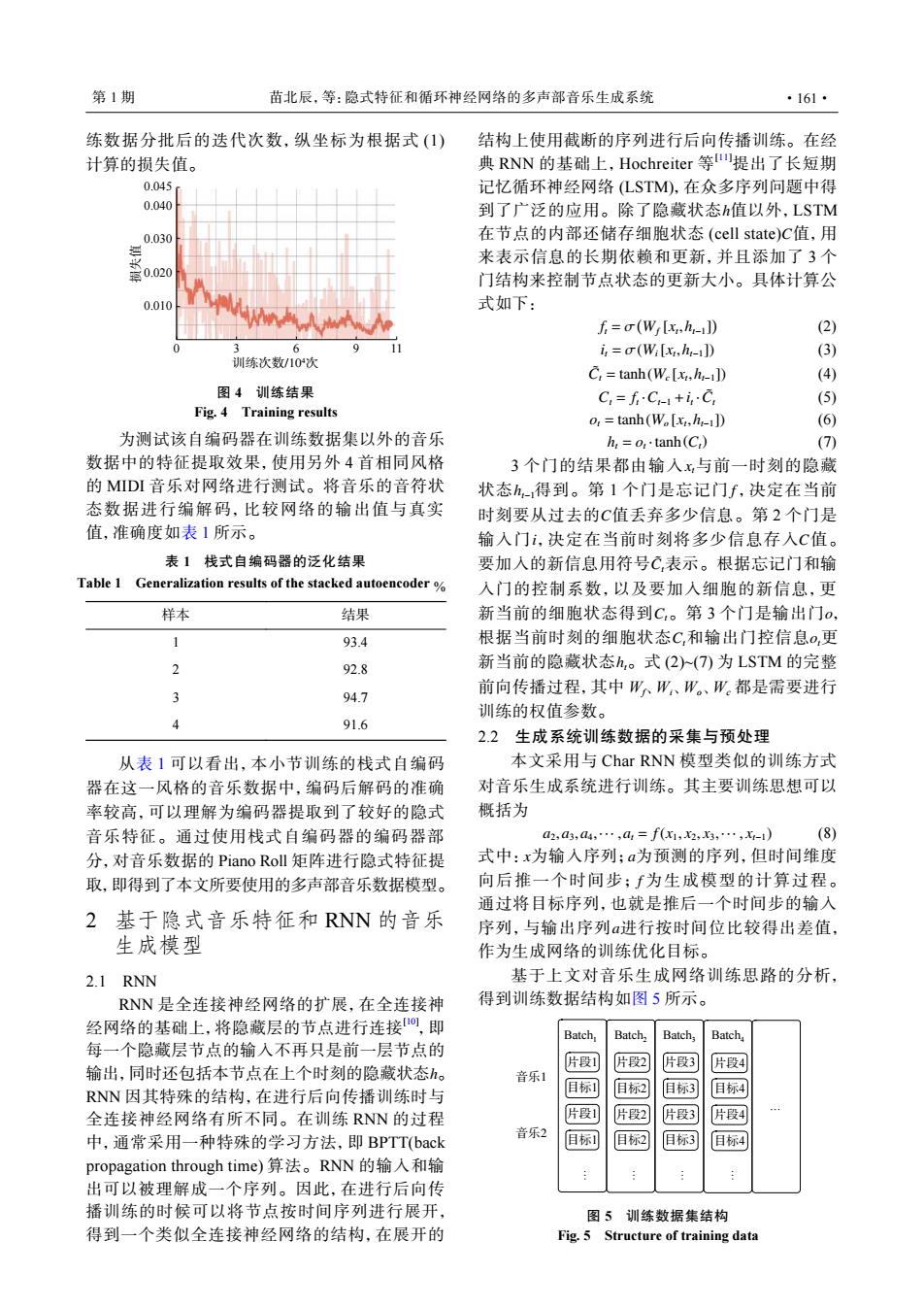
第1期 苗北辰,等:隐式特征和循环神经网络的多声部音乐生成系统 ·161· 练数据分批后的迭代次数,纵坐标为根据式(1) 结构上使用截断的序列进行后向传播训练。在经 计算的损失值。 典RNN的基础上,Hochreiter等提出了长短期 0.045 记忆循环神经网络(LSTM),在众多序列问题中得 0.040 到了广泛的应用。除了隐藏状态h值以外,LSTM 0.030 在节点的内部还储存细胞状态(cell state)C值,用 0.020 来表示信息的长期依赖和更新,并且添加了3个 门结构来控制节点状态的更新大小。具体计算公 0.010 式如下: f=(Wi[x,h1]) (2) 6 i,=(Wi[x,h1]) (3) 训练次数/10次 C:=tanh(We[x.h-11) (4) 图4训练结果 C=fC+iC (5) Fig.4 Training results o:tanh(W[x,h1]) (6) 为测试该自编码器在训练数据集以外的音乐 h,=o,·tanh(C) (7) 数据中的特征提取效果,使用另外4首相同风格 3个门的结果都由输入x与前一时刻的隐藏 的MIDI音乐对网络进行测试。将音乐的音符状 状态h得到。第1个门是忘记门f,决定在当前 态数据进行编解码,比较网络的输出值与真实 时刻要从过去的C值丢弃多少信息。第2个门是 值,准确度如表1所示。 输入门i,决定在当前时刻将多少信息存入C值。 表1栈式自编码器的泛化结果 要加入的新信息用符号C,表示。根据忘记门和输 Table 1 Generalization results of the stacked autoencoder% 入门的控制系数,以及要加入细胞的新信息,更 样本 结果 新当前的细胞状态得到C,。第3个门是输出门o, 1 93.4 根据当前时刻的细胞状态C,和输出门控信息o,更 2 92.8 新当前的隐藏状态h。式(2)(7)为LSTM的完整 前向传播过程,其中W。W、W。、W都是需要进行 94.7 训练的权值参数。 4 91.6 2.2生成系统训练数据的采集与预处理 从表1可以看出,本小节训练的栈式自编码 本文采用与Char RNN模型类似的训练方式 器在这一风格的音乐数据中,编码后解码的准确 对音乐生成系统进行训练。其主要训练思想可以 率较高,可以理解为编码器提取到了较好的隐式 概括为 音乐特征。通过使用栈式自编码器的编码器部 a2,a3,a4,·,a1=f(x1,2,x3,…,X-1) (8) 分,对音乐数据的Piano Roll矩阵进行隐式特征提 式中:x为输入序列:a为预测的序列,但时间维度 取,即得到了本文所要使用的多声部音乐数据模型。 向后推一个时间步;f为生成模型的计算过程。 通过将目标序列,也就是推后一个时间步的输入 2基于隐式音乐特征和RNN的音乐 序列,与输出序列a进行按时间位比较得出差值, 生成模型 作为生成网络的训练优化目标。 2.1 RNN 基于上文对音乐生成网络训练思路的分析, RNN是全连接神经网络的扩展,在全连接神 得到训练数据结构如图5所示。 经网络的基础上,将隐藏层的节点进行连接,即 Batch, Batch, Batch; Batch 每一个隐藏层节点的输入不再只是前一层节点的 片段1 片段2 片段3 输出,同时还包括本节点在上个时刻的隐藏状态。 片段4 音乐1 RNN因其特殊的结构,在进行后向传播训练时与 日标1 目标2 目标3 目标4 全连接神经网络有所不同。在训练RNN的过程 片段1 片段2 片段3 片段4 中,通常采用一种特殊的学习方法,即BPTT(back 音乐2 目标] 目标2 旧标3 目标4 propagation through time)算法。RNN的输入和输 出可以被理解成一个序列。因此,在进行后向传 播训练的时候可以将节点按时间序列进行展开, 图5训练数据集结构 得到一个类似全连接神经网络的结构,在展开的 Fig.5 Structure of training data练数据分批后的迭代次数,纵坐标为根据式 (1) 计算的损失值。 0.040 0.030 0.020 0.010 0 3 6 9 训练次数/104次 损失值 11 0.045 图 4 训练结果 Fig. 4 Training results 为测试该自编码器在训练数据集以外的音乐 数据中的特征提取效果,使用另外 4 首相同风格 的 MIDI 音乐对网络进行测试。将音乐的音符状 态数据进行编解码,比较网络的输出值与真实 值,准确度如表 1 所示。 表 1 栈式自编码器的泛化结果 Table 1 Generalization results of the stacked autoencoder % 样本 结果 1 93.4 2 92.8 3 94.7 4 91.6 从表 1 可以看出,本小节训练的栈式自编码 器在这一风格的音乐数据中,编码后解码的准确 率较高,可以理解为编码器提取到了较好的隐式 音乐特征。通过使用栈式自编码器的编码器部 分,对音乐数据的 Piano Roll 矩阵进行隐式特征提 取,即得到了本文所要使用的多声部音乐数据模型。 2 基于隐式音乐特征和 RNN 的音乐 生成模型 2.1 RNN h RNN 是全连接神经网络的扩展,在全连接神 经网络的基础上,将隐藏层的节点进行连接[10] ,即 每一个隐藏层节点的输入不再只是前一层节点的 输出,同时还包括本节点在上个时刻的隐藏状态 。 RNN 因其特殊的结构,在进行后向传播训练时与 全连接神经网络有所不同。在训练 RNN 的过程 中,通常采用一种特殊的学习方法,即 BPTT(back propagation through time) 算法。RNN 的输入和输 出可以被理解成一个序列。因此,在进行后向传 播训练的时候可以将节点按时间序列进行展开, 得到一个类似全连接神经网络的结构,在展开的 h C 结构上使用截断的序列进行后向传播训练。在经 典 RNN 的基础上,Hochreiter 等 [11]提出了长短期 记忆循环神经网络 (LSTM),在众多序列问题中得 到了广泛的应用。除了隐藏状态 值以外,LSTM 在节点的内部还储存细胞状态 (cell state) 值,用 来表示信息的长期依赖和更新,并且添加了 3 个 门结构来控制节点状态的更新大小。具体计算公 式如下: ft = σ ( Wf [xt ,ht−1] ) (2) it = σ(Wi[xt ,ht−1]) (3) C˜ t = tanh(Wc [xt ,ht−1]) (4) Ct = ft ·Ct−1 +it ·C˜ t (5) ot = tanh(Wo [xt ,ht−1]) (6) ht = ot ·tanh(Ct) (7) xt ht−1 f C i C C˜ t Ct o Ct ot ht 3 个门的结果都由输入 与前一时刻的隐藏 状态 得到。第 1 个门是忘记门 ,决定在当前 时刻要从过去的 值丢弃多少信息。第 2 个门是 输入门 ,决定在当前时刻将多少信息存入 值。 要加入的新信息用符号 表示。根据忘记门和输 入门的控制系数,以及要加入细胞的新信息,更 新当前的细胞状态得到 。第 3 个门是输出门 , 根据当前时刻的细胞状态 和输出门控信息 更 新当前的隐藏状态 。式 (2)~(7) 为 LSTM 的完整 前向传播过程,其中 Wf、Wi、Wo、Wc 都是需要进行 训练的权值参数。 2.2 生成系统训练数据的采集与预处理 本文采用与 Char RNN 模型类似的训练方式 对音乐生成系统进行训练。其主要训练思想可以 概括为 a2,a3,a4,··· ,at = f(x1, x2, x3,··· , xt−1) (8) x a f a 式中: 为输入序列; 为预测的序列,但时间维度 向后推一个时间步; 为生成模型的计算过程。 通过将目标序列,也就是推后一个时间步的输入 序列,与输出序列 进行按时间位比较得出差值, 作为生成网络的训练优化目标。 基于上文对音乐生成网络训练思路的分析, 得到训练数据结构如图 5 所示。 Batch1 Batch2 Batch3 Batch4 音乐1 音乐2 片段1 目标1 片段1 片段2 片段3 片段4 目标1 目标2 目标3 目标4 目标2 目标3 目标4 片段2 片段3 片段4 … … … … … 图 5 训练数据集结构 Fig. 5 Structure of training data 第 1 期 苗北辰,等:隐式特征和循环神经网络的多声部音乐生成系统 ·161·