正在加载图片...
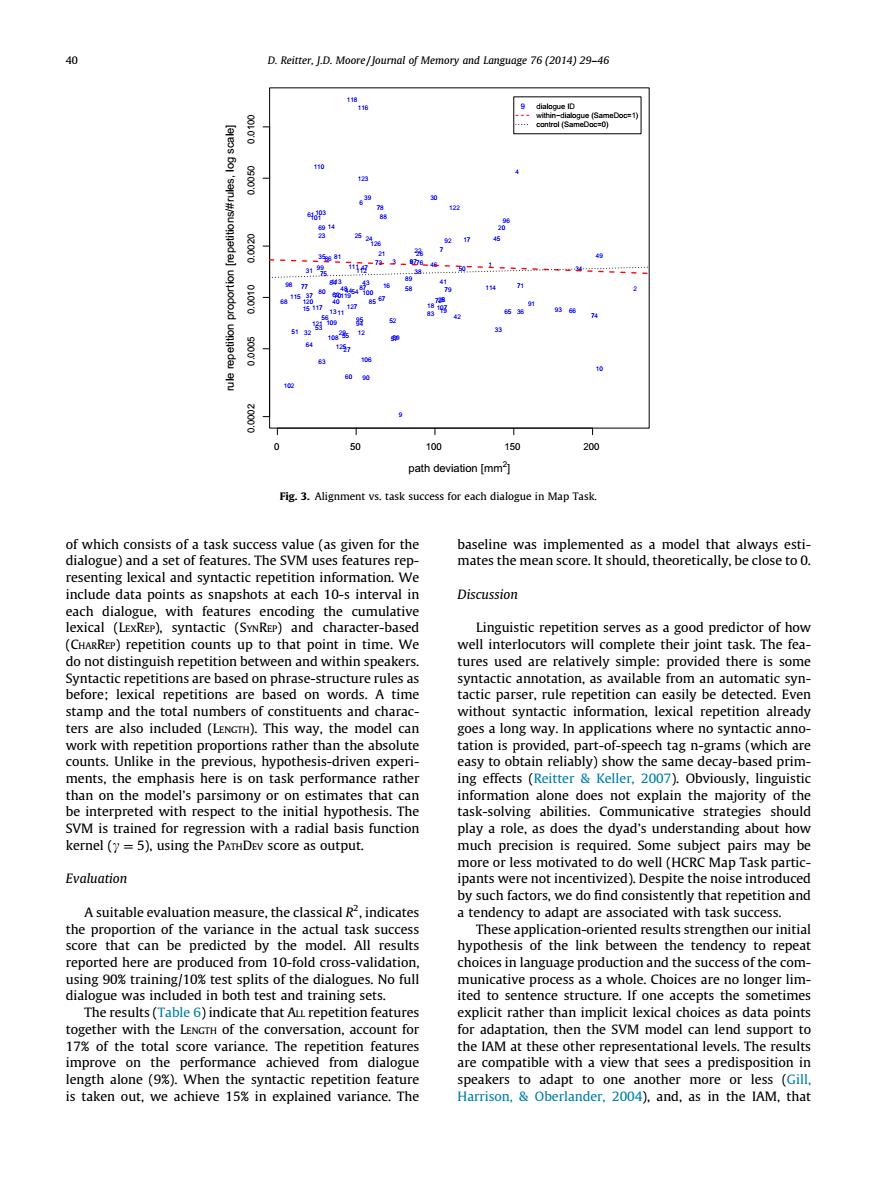
40 D.Reirter.I.D.Moore/Journal of Memory and Language 76 (2014)29-46 ,数 ath deviation [mm .Alignment vs.task success for eac dialogue in Map Task of which consists of a task success value(as given for the and a set of features.The SVM include data points as snapshots at each 10-s interval in Discussion each dia with featu Ling petition edictor of h TacaAm sting en and within spe e well interocoe ther ures ued are e relatively simp actic parser.rue repetition can eas iybe detected.Ever stamp and the total u mation.lexical repet -driven ex decay- y or on stimates that ca orma tion alone kernel (y=5).using the PATHDEv score as output. much precision is required.Some subject pairs may be Evaluation by such factors.we do find consistently that repetition and the t are asso score that can be predic h model.Alre of the link bet /10%tes plits of the dialogues no ful r lim dial ited to se ence st .If ada tation then the SyM model can lend support to the IAM at these other representational levels The resu lengt)When the syntactic speakers to adapt to one another more or less (cil is taken out,we achieve 15%in explained variance.The Harrison.Oberlander.2004).and.as in the IAM.thatof which consists of a task success value (as given for the dialogue) and a set of features. The SVM uses features representing lexical and syntactic repetition information. We include data points as snapshots at each 10-s interval in each dialogue, with features encoding the cumulative lexical (LEXREP), syntactic (SYNREP) and character-based (CHARREP) repetition counts up to that point in time. We do not distinguish repetition between and within speakers. Syntactic repetitions are based on phrase-structure rules as before; lexical repetitions are based on words. A time stamp and the total numbers of constituents and characters are also included (LENGTH). This way, the model can work with repetition proportions rather than the absolute counts. Unlike in the previous, hypothesis-driven experiments, the emphasis here is on task performance rather than on the model’s parsimony or on estimates that can be interpreted with respect to the initial hypothesis. The SVM is trained for regression with a radial basis function kernel (c ¼ 5), using the PATHDEV score as output. Evaluation A suitable evaluation measure, the classical R2 , indicates the proportion of the variance in the actual task success score that can be predicted by the model. All results reported here are produced from 10-fold cross-validation, using 90% training/10% test splits of the dialogues. No full dialogue was included in both test and training sets. The results (Table 6) indicate that ALL repetition features together with the LENGTH of the conversation, account for 17% of the total score variance. The repetition features improve on the performance achieved from dialogue length alone (9%). When the syntactic repetition feature is taken out, we achieve 15% in explained variance. The baseline was implemented as a model that always estimates the mean score. It should, theoretically, be close to 0. Discussion Linguistic repetition serves as a good predictor of how well interlocutors will complete their joint task. The features used are relatively simple: provided there is some syntactic annotation, as available from an automatic syntactic parser, rule repetition can easily be detected. Even without syntactic information, lexical repetition already goes a long way. In applications where no syntactic annotation is provided, part-of-speech tag n-grams (which are easy to obtain reliably) show the same decay-based priming effects (Reitter & Keller, 2007). Obviously, linguistic information alone does not explain the majority of the task-solving abilities. Communicative strategies should play a role, as does the dyad’s understanding about how much precision is required. Some subject pairs may be more or less motivated to do well (HCRC Map Task participants were not incentivized). Despite the noise introduced by such factors, we do find consistently that repetition and a tendency to adapt are associated with task success. These application-oriented results strengthen our initial hypothesis of the link between the tendency to repeat choices in language production and the success of the communicative process as a whole. Choices are no longer limited to sentence structure. If one accepts the sometimes explicit rather than implicit lexical choices as data points for adaptation, then the SVM model can lend support to the IAM at these other representational levels. The results are compatible with a view that sees a predisposition in speakers to adapt to one another more or less (Gill, Harrison, & Oberlander, 2004), and, as in the IAM, that 0 50 100 150 200 0.0002 0.0005 0.0010 0.0020 0.0050 0.0100 path deviation [mm2 ] rule repetition proportion [repetitions/#rules, log scale] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 83 84 85 86 87 88 89 90 91 92 93 9495 96 97 98 99 100 101 102 103 106 107 108 109 110 111112 113 114 115 116 117 118 119 120 121 122 123 125 126 127 9 dialogue ID within−dialogue (SameDoc=1) control (SameDoc=0) Fig. 3. Alignment vs. task success for each dialogue in Map Task. 40 D. Reitter, J.D. Moore / Journal of Memory and Language 76 (2014) 29–46