正在加载图片...
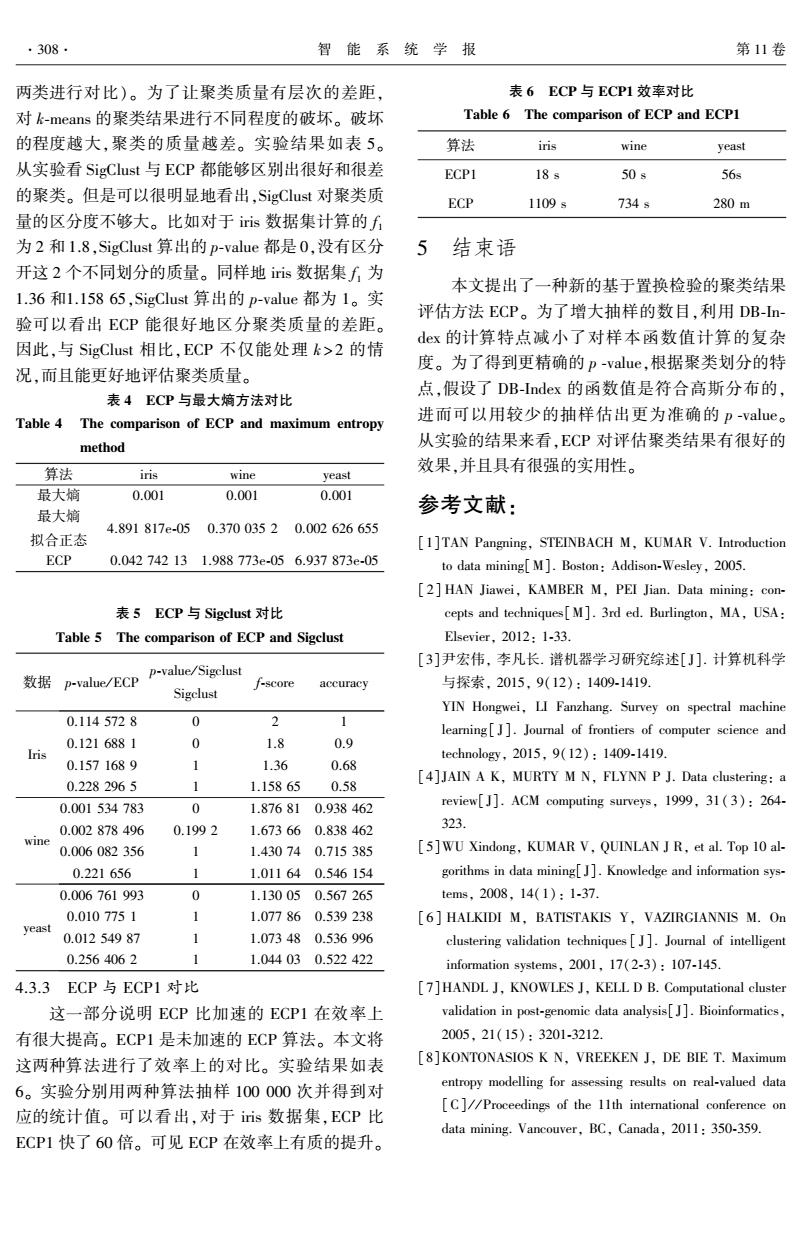
·308 智能系统学报 第11卷 两类进行对比)。为了让聚类质量有层次的差距, 表6ECP与ECP1效率对比 对k-means的聚类结果进行不同程度的破坏。破坏 Table 6 The comparison of ECP and ECPI 的程度越大,聚类的质量越差。实验结果如表5。 算法 iris wine yeast 从实验看SigClust与ECP都能够区别出很好和很差 ECP1 18s 50s 56s 的聚类。但是可以很明显地看出,SigClust对聚类质 ECP 1109s 734÷ 280m 量的区分度不够大。比如对于iis数据集计算的f 为2和1.8,SigClust算出的p-value都是0,没有区分 5 结束语 开这2个不同划分的质量。同样地iis数据集f为 本文提出了一种新的基于置换检验的聚类结果 1.36和1.15865,SigClust算出的p-value都为1。实 评估方法ECP。为了增大抽样的数目,利用DB-n- 验可以看出ECP能很好地区分聚类质量的差距。 dex的计算特点减小了对样本函数值计算的复杂 因此,与SigClust相比,ECP不仅能处理k>2的情 度。为了得到更精确的p-value,根据聚类划分的特 况,而且能更好地评估聚类质量。 点,假设了DB-Index的函数值是符合高斯分布的, 表4ECP与最大熵方法对比 Table 4 The comparison of ECP and maximum entropy 进而可以用较少的抽样估出更为准确的p-value。 method 从实验的结果来看,ECP对评估聚类结果有很好的 算法 iris 效果,并且具有很强的实用性。 wine yeast 最大嫡 0.001 0.001 0.001 最大嫡 参考文献: 4.891817e-050.37003520.002626655 拟合正态 [1]TAN Pangning,STEINBACH M,KUMAR V.Introduction ECP 0.042742131.988773e-056.937873e-05 to data mining[M.Boston:Addison-Wesley,2005. [2]HAN Jiawei,KAMBER M,PEI Jian.Data mining:con- 表5ECP与Sigclust对比 cepts and techniques[M].3rd ed.Burlington,MA,USA: Table 5 The comparison of ECP and Sigclust Elsevier,2012:1-33. [3]尹宏伟,李凡长.谱机器学习研究综述[J].计算机科学 p-value/Sigclust 数据p-value/ECP f-score accuracy 与探索,2015,9(12):1409-1419. Sigclust YIN Hongwei,LI Fanzhang.Survey on spectral machine 0.1145728 0 2 1 learning[]].Journal of frontiers of computer science and 0.1216881 0 1.8 0.9 Iris technolog,2015,9(12):1409-1419. 0.1571689 1.36 0.68 0.2282965 [4]JAIN A K,MURTY M N,FLYNN P J.Data clustering:a 1.15865 0.58 0.001534783 0 1.876810.938462 review[J].ACM computing surveys,1999,31(3):264- 0.002878496 0.1992 1.673660.838462 323 wine 0.006082356 1 1.430740.715385 [5]WU Xindong,KUMAR V,QUINLAN J R,et al.Top 10 al- 0.221656 1.011640.546154 gorithms in data mining[J].Knowledge and information sys- 0.006761993 0 1.130050.567265 tems,2008,14(1):1-37. 0.0107751 1.077860.539238 [6]HALKIDI M,BATISTAKIS Y,VAZIRGIANNIS M.On yeast 0.01254987 1 1.073480.536996 clustering validation techniques[J].Journal of intelligent 0.2564062 1.044030.522422 information systems,2001,17(2-3):107-145. 4.3.3 ECP与ECP1对比 [7]HANDL J,KNOWLES J,KELL D B.Computational cluster 这一部分说明ECP比加速的ECP1在效率上 validation in post-genomic data analysis[J].Bioinformatics. 有很大提高。ECP1是未加速的ECP算法。本文将 2005,21(15):3201-3212. 这两种算法进行了效率上的对比。实验结果如表 8]KONTONASIOS K N.VREEKEN J,DE BIE T.Maximum 6。实验分别用两种算法抽样100000次并得到对 entropy modelling for assessing results on real-valued data [C]//Proceedings of the 11th international conference on 应的统计值。可以看出,对于iis数据集,ECP比 data mining.Vancouver,BC,Canada,2011:350-359. ECP1快了60倍。可见ECP在效率上有质的提升。两类进行对比)。 为了让聚类质量有层次的差距, 对 k⁃means 的聚类结果进行不同程度的破坏。 破坏 的程度越大,聚类的质量越差。 实验结果如表 5。 从实验看 SigClust 与 ECP 都能够区别出很好和很差 的聚类。 但是可以很明显地看出,SigClust 对聚类质 量的区分度不够大。 比如对于 iris 数据集计算的 f 1 为 2 和 1.8,SigClust 算出的 p⁃value 都是 0,没有区分 开这 2 个不同划分的质量。 同样地 iris 数据集 f 1 为 1.36 和1.158 65,SigClust 算出的 p⁃value 都为 1。 实 验可以看出 ECP 能很好地区分聚类质量的差距。 因此,与 SigClust 相比,ECP 不仅能处理 k > 2 的情 况,而且能更好地评估聚类质量。 表 4 ECP 与最大熵方法对比 Table 4 The comparison of ECP and maximum entropy method 算法 iris wine yeast 最大熵 0.001 0.001 0.001 最大熵 拟合正态 4.891 817e⁃05 0.370 035 2 0.002 626 655 ECP 0.042 742 13 1.988 773e⁃05 6.937 873e⁃05 表 5 ECP 与 Sigclust 对比 Table 5 The comparison of ECP and Sigclust 数据 p⁃value / ECP p⁃value / Sigclust Sigclust f⁃score accuracy Iris 0.114 572 8 0 2 1 0.121 688 1 0 1.8 0.9 0.157 168 9 1 1.36 0.68 0.228 296 5 1 1.158 65 0.58 wine 0.001 534 783 0 1.876 81 0.938 462 0.002 878 496 0.199 2 1.673 66 0.838 462 0.006 082 356 1 1.430 74 0.715 385 0.221 656 1 1.011 64 0.546 154 yeast 0.006 761 993 0 1.130 05 0.567 265 0.010 775 1 1 1.077 86 0.539 238 0.012 549 87 1 1.073 48 0.536 996 0.256 406 2 1 1.044 03 0.522 422 4.3.3 ECP 与 ECP1 对比 这一部分说明 ECP 比加速的 ECP1 在效率上 有很大提高。 ECP1 是未加速的 ECP 算法。 本文将 这两种算法进行了效率上的对比。 实验结果如表 6。 实验分别用两种算法抽样 100 000 次并得到对 应的统计值。 可以看出,对于 iris 数据集,ECP 比 ECP1 快了 60 倍。 可见 ECP 在效率上有质的提升。 表 6 ECP 与 ECP1 效率对比 Table 6 The comparison of ECP and ECP1 算法 iris wine yeast ECP1 18 s 50 s 56s ECP 1109 s 734 s 280 m 5 结束语 本文提出了一种新的基于置换检验的聚类结果 评估方法 ECP。 为了增大抽样的数目,利用 DB⁃In⁃ dex 的计算特点减小了对样本函数值计算的复杂 度。 为了得到更精确的 p ⁃value,根据聚类划分的特 点,假设了 DB⁃Index 的函数值是符合高斯分布的, 进而可以用较少的抽样估出更为准确的 p ⁃value。 从实验的结果来看,ECP 对评估聚类结果有很好的 效果,并且具有很强的实用性。 参考文献: [1]TAN Pangning, STEINBACH M, KUMAR V. Introduction to data mining[M]. Boston: Addison⁃Wesley, 2005. [ 2] HAN Jiawei, KAMBER M, PEI Jian. Data mining: con⁃ cepts and techniques[M]. 3rd ed. Burlington, MA, USA: Elsevier, 2012: 1⁃33. [3]尹宏伟, 李凡长. 谱机器学习研究综述[ J]. 计算机科学 与探索, 2015, 9(12): 1409⁃1419. YIN Hongwei, LI Fanzhang. Survey on spectral machine learning[ J]. Journal of frontiers of computer science and technology, 2015, 9(12): 1409⁃1419. [4]JAIN A K, MURTY M N, FLYNN P J. Data clustering: a review[J]. ACM computing surveys, 1999, 31( 3): 264⁃ 323. [5]WU Xindong, KUMAR V, QUINLAN J R, et al. Top 10 al⁃ gorithms in data mining[J]. Knowledge and information sys⁃ tems, 2008, 14(1): 1⁃37. [6] HALKIDI M, BATISTAKIS Y, VAZIRGIANNIS M. On clustering validation techniques [ J]. Journal of intelligent information systems, 2001, 17(2⁃3): 107⁃145. [7]HANDL J, KNOWLES J, KELL D B. Computational cluster validation in post⁃genomic data analysis[J]. Bioinformatics, 2005, 21(15): 3201⁃3212. [8]KONTONASIOS K N, VREEKEN J, DE BIE T. Maximum entropy modelling for assessing results on real⁃valued data [C] / / Proceedings of the 11th international conference on data mining. Vancouver, BC, Canada, 2011: 350⁃359. ·308· 智 能 系 统 学 报 第 11 卷