正在加载图片...
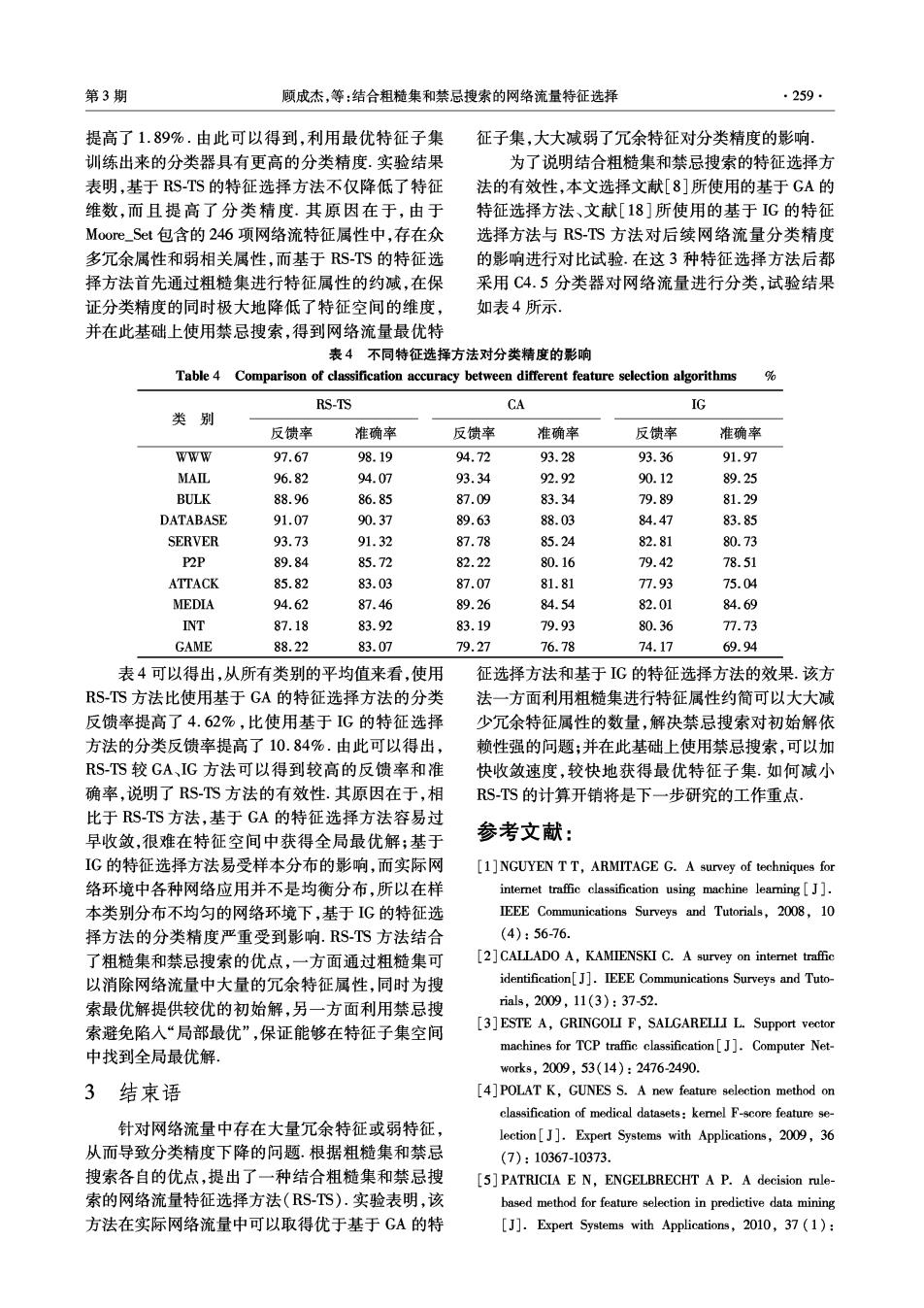
第3期 顾成杰,等:结合粗糙集和禁忌搜索的网络流量特征选择 ·259· 提高了1.89%.由此可以得到,利用最优特征子集 征子集,大大减弱了冗余特征对分类精度的影响, 训练出来的分类器具有更高的分类精度.实验结果 为了说明结合粗糙集和禁忌搜索的特征选择方 表明,基于S-TS的特征选择方法不仅降低了特征 法的有效性,本文选择文献[8]所使用的基于GA的 维数,而且提高了分类精度.其原因在于,由于 特征选择方法、文献[18]所使用的基于IG的特征 Moore_.Set包含的246项网络流特征属性中,存在众 选择方法与RS-TS方法对后续网络流量分类精度 多冗余属性和弱相关属性,而基于RS-TS的特征选 的影响进行对比试验.在这3种特征选择方法后都 择方法首先通过粗糙集进行特征属性的约减,在保 采用C4.5分类器对网络流量进行分类,试验结果 证分类精度的同时极大地降低了特征空间的维度, 如表4所示。 并在此基础上使用禁忌搜索,得到网络流量最优特 表4不同特征选择方法对分类精度的影响 Table 4 Comparison of classification accuracy between different feature selection algorithms % RS-TS CA IG 类别 反馈率 准确率 反馈率 准确率 反馈率 准确率 WWw 97.67 98.19 94.72 93.28 93.36 91.97 MAIL 96.82 94.07 93.34 92.92 90.12 89.25 BULK 88.96 86.85 87.09 83.34 79.89 81.29 DATABASE 91.07 90.37 89.63 88.03 84.47 83.85 SERVER 93.73 91.32 87.78 85.24 82.81 80.73 P2P 89.84 85.72 82.22 80.16 79.42 78.51 ATTACK 85.82 83.03 87.07 81.81 77.93 75.04 MEDIA 94.62 87.46 89.26 84.54 82.01 84.69 INT 87.18 83.92 83.19 79.93 80.36 77.73 GAME 88.22 83.07 79.27 76.78 74.17 69.94 表4可以得出,从所有类别的平均值来看,使用 征选择方法和基于IG的特征选择方法的效果.该方 RSTS方法比使用基于GA的特征选择方法的分类 法一方面利用粗糙集进行特征属性约简可以大大减 反馈率提高了4.62%,比使用基于IG的特征选择 少冗余特征属性的数量,解决禁忌搜索对初始解依 方法的分类反馈率提高了10.84%.由此可以得出, 赖性强的问题:并在此基础上使用禁忌搜索,可以加 RS-TS较GA、IG方法可以得到较高的反馈率和准 快收敛速度,较快地获得最优特征子集.如何减小 确率,说明了RS-TS方法的有效性.其原因在于,相 RS-TS的计算开销将是下一步研究的工作重点. 比于RS-TS方法,基于GA的特征选择方法容易过 早收敛,很难在特征空间中获得全局最优解;基于 参考文献: IG的特征选择方法易受样本分布的影响,而实际网 [1]NGUYEN TT,ARMITAGE G.A survey of techniques for 络环境中各种网络应用并不是均衡分布,所以在样 internet traffic classification using machine learning[J]. 本类别分布不均匀的网络环境下,基于IG的特征选 IEEE Communications Surveys and Tutorials,2008,10 择方法的分类精度严重受到影响.RS-TS方法结合 (4):56-76. 了粗糙集和禁忌搜索的优点,一方面通过粗糙集可 [2]CALLADO A,KAMIENSKI C.A survey on interet traffic 以消除网络流量中大量的冗余特征属性,同时为搜 identification[J].IEEE Communications Surveys and Tuto- 索最优解提供较优的初始解,另一方面利用禁忌搜 rials,2009,11(3):37-52. 索避免陷人“局部最优”,保证能够在特征子集空间 [3]ESTE A,GRINGOLI F,SALGARELLI L.Support vector machines for TCP traffic classification[J].Computer Net- 中找到全局最优解. w0rks,2009,53(14):2476-2490. 3 结束语 4]POLAT K.GUNES S.A new feature selection method on classification of medical datasets:kemel F-score feature se- 针对网络流量中存在大量冗余特征或弱特征, lection[J].Expert Systems with Applications,2009,36 从而导致分类精度下降的问题.根据粗糙集和禁忌 (7):10367-10373. 搜索各自的优点,提出了一种结合粗糙集和禁忌搜 [5]PATRICIA E N,ENGELBRECHT A P.A decision rule 索的网络流量特征选择方法(RS-TS).实验表明,该 based method for feature selection in predictive data mining 方法在实际网络流量中可以取得优于基于GA的特 [J].Expert Systems with Applications,2010,37(1):