正在加载图片...
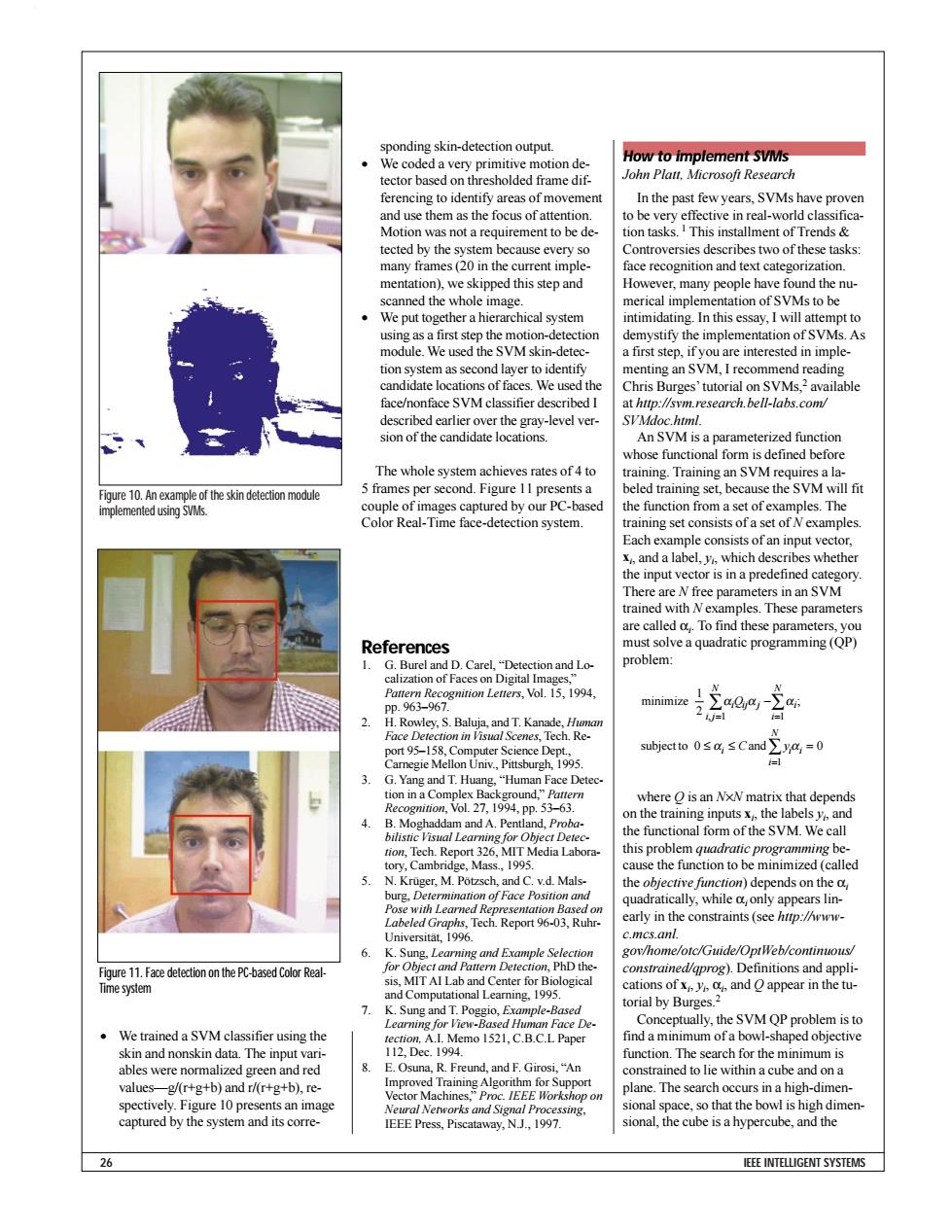
sponding skin-detection output. We coded a very primitive motion de- How to implement SVMs tector based on thresholded frame dif John Platt.Microsoft Research ferencing to identify areas of movement In the past few years,SVMs have proven and use them as the focus of attention. to be very effective in real-world classifica- Motion was not a requirement to be de- tion tasks.I This installment of Trends tected by the system because every so Controversies describes two of these tasks: many frames(20 in the current imple- face recognition and text categorization. mentation),we skipped this step and However,many people have found the nu- scanned the whole image. merical implementation of SVMs to be We put together a hierarchical system intimidating.In this essay,I will attempt to using as a first step the motion-detection demystify the implementation of SVMs.As module.We used the SVM skin-detec- a first step,if you are interested in imple- tion system as second layer to identify menting an SVM,I recommend reading candidate locations of faces.We used the Chris Burges'tutorial on SVMs,2 available face/nonface SVM classifier described I at http://svm.research.bell-labs.com/ described earlier over the gray-level ver- SVMdoc.himl. sion of the candidate locations. An SVM is a parameterized function whose functional form is defined before The whole system achieves rates of 4 to training.Training an SVM requires a la- Figure 10.An example of the skin detection module 5 frames per second.Figure 11 presents a beled training set,because the SVM will fit implemented using SVMs. couple of images captured by our PC-based the function from a set of examples.The Color Real-Time face-detection system. training set consists of a set of N examples. Each example consists of an input vector, x,and a label,y.which describes whether the input vector is in a predefined category. There are N free parameters in an SVM trained with Nexamples.These parameters are called o.To find these parameters,you References must solve a quadratic programming (QP) 1.G.Burel and D.Carel,"Detection and Lo- problem: calization of Faces on Digital Images," Pattern Recognition Letters,Vol.15,1994. pp.963-967. minimize 2 2. H.Rowley,S.Baluja,and T.Kanade,Human Face Detection in Visual Scenes,Tech.Re- N port 95-158,Computer Science Dept., subjectto0≤a,≤Cand∑y,=0 Carnegie Mellon Univ.,Pittsburgh,1995. 3. G.Yang and T.Huang,"Human Face Detec- tion in a Complex Background,"Pattern where O is an NxN matrix that depends Recognition,Vol.27,1994,pp.53-63. 4. on the training inputsxthe labelsy and B.Moghaddam and A.Pentland,Proba- bilistic Visual Learning for Object Detec- the functional form of the SVM.We call tion,Tech.Report 326,MIT Media Labora- this problem quadratic programming be- tory,Cambridge,Mass.,1995. cause the function to be minimized(called 5. N.Kruger,M.Potzsch,and C.v.d.Mals- the objective function)depends on the a burg,Determination of Face Position and quadratically,while o,only appears lin- Pose with Learned Representation Based on Labeled Graphs,Tech.Report 96-03,Ruhr- early in the constraints (see http://www- Universitat,1996. c.mcs.anl. 6. K.Sung,Learning and Example Selection gov/home/otc/Guide/OptWeb/continuous/ Figure 11.Face detcion thePC-based Color Real- for Object and Pattern Detection,PhD the. constrained/gprog).Definitions and appli- Time system sis,MIT AI Lab and Center for Biological and Computational Learning.1995. cations ofxand appear in the tu- 7. torial by Burges.2 K.Sung and T.Poggio,Example-Based Learning for View-Based Human Face De Conceptually,the SVM QP problem is to We trained a SVM classifier using the tection.A.I.Memo 1521,C.B.C.L Paper find a minimum of a bowl-shaped objective skin and nonskin data.The input vari- 112,Dec.1994. function.The search for the minimum is ables were normalized green and red E.Osuna,R.Freund,and F.Girosi,"An constrained to lie within a cube and on a values-g/(r+g+b)and r/(r+g+b),re- Improved Training Algorithm for Support Vector Machines,"Proc.IEEE Workshop on plane.The search occurs in a high-dimen- spectively.Figure 10 presents an image Neural Networks and Signal Processing, sional space,so that the bowl is high dimen- captured by the system and its corre- IEEE Press,Piscataway,N.J.,1997. sional,the cube is a hypercube,and the 26 IEEE INTELLIGENT SYSTEMS• We trained a SVM classifier using the skin and nonskin data. The input variables were normalized green and red values—g/(r+g+b) and r/(r+g+b), respectively. Figure 10 presents an image captured by the system and its corresponding skin-detection output. • We coded a very primitive motion detector based on thresholded frame differencing to identify areas of movement and use them as the focus of attention. Motion was not a requirement to be detected by the system because every so many frames (20 in the current implementation), we skipped this step and scanned the whole image. • We put together a hierarchical system using as a first step the motion-detection module. We used the SVM skin-detection system as second layer to identify candidate locations of faces. We used the face/nonface SVM classifier described I described earlier over the gray-level version of the candidate locations. The whole system achieves rates of 4 to 5 frames per second. Figure 11 presents a couple of images captured by our PC-based Color Real-Time face-detection system. References 1. G. Burel and D. Carel, “Detection and Localization of Faces on Digital Images,” Pattern Recognition Letters, Vol. 15, 1994, pp. 963–967. 2. H. Rowley, S. Baluja, and T. Kanade, Human Face Detection in Visual Scenes, Tech. Report 95–158, Computer Science Dept., Carnegie Mellon Univ., Pittsburgh, 1995. 3. G. Yang and T. Huang, “Human Face Detection in a Complex Background,” Pattern Recognition, Vol. 27, 1994, pp. 53–63. 4. B. Moghaddam and A. Pentland, Probabilistic Visual Learning for Object Detection, Tech. Report 326, MIT Media Laboratory, Cambridge, Mass., 1995. 5. N. Krüger, M. Pötzsch, and C. v.d. Malsburg, Determination of Face Position and Pose with Learned Representation Based on Labeled Graphs, Tech. Report 96-03, RuhrUniversität, 1996. 6. K. Sung, Learning and Example Selection for Object and Pattern Detection, PhD thesis, MIT AI Lab and Center for Biological and Computational Learning, 1995. 7. K. Sung and T. Poggio, Example-Based Learning for View-Based Human Face Detection, A.I. Memo 1521, C.B.C.L Paper 112, Dec. 1994. 8. E. Osuna, R. Freund, and F. Girosi, “An Improved Training Algorithm for Support Vector Machines,” Proc. IEEE Workshop on Neural Networks and Signal Processing, IEEE Press, Piscataway, N.J., 1997. How to implement SVMs John Platt, Microsoft Research In the past few years, SVMs have proven to be very effective in real-world classification tasks. 1 This installment of Trends & Controversies describes two of these tasks: face recognition and text categorization. However, many people have found the numerical implementation of SVMs to be intimidating. In this essay, I will attempt to demystify the implementation of SVMs. As a first step, if you are interested in implementing an SVM, I recommend reading Chris Burges’tutorial on SVMs,2 available at http://svm.research.bell-labs.com/ SVMdoc.html. An SVM is a parameterized function whose functional form is defined before training. Training an SVM requires a labeled training set, because the SVM will fit the function from a set of examples. The training set consists of a set of N examples. Each example consists of an input vector, xi , and a label, yi , which describes whether the input vector is in a predefined category. There are N free parameters in an SVM trained with N examples. These parameters are called αi . To find these parameters, you must solve a quadratic programming (QP) problem: where Q is an N×N matrix that depends on the training inputs xi , the labels yi , and the functional form of the SVM. We call this problem quadratic programming because the function to be minimized (called the objective function) depends on the αi quadratically, while αi only appears linearly in the constraints (see http://wwwc.mcs.anl. gov/home/otc/Guide/OptWeb/continuous/ constrained/qprog). Definitions and applications of xi , yi , αi , and Q appear in the tutorial by Burges.2 Conceptually, the SVM QP problem is to find a minimum of a bowl-shaped objective function. The search for the minimum is constrained to lie within a cube and on a plane. The search occurs in a high-dimensional space, so that the bowl is high dimensional, the cube is a hypercube, and the minimize subject to and 1 2 0 0 1 1 1 α α α α α i ij j i j N i i N i i i i N Q C y − ≤ ≤ = = = = ∑ ∑ ∑ , ; 26 IEEE INTELLIGENT SYSTEMS Figure 10. An example of the skin detection module implemented using SVMs. Figure 11. Face detection on the PC-based Color RealTime system