正在加载图片...
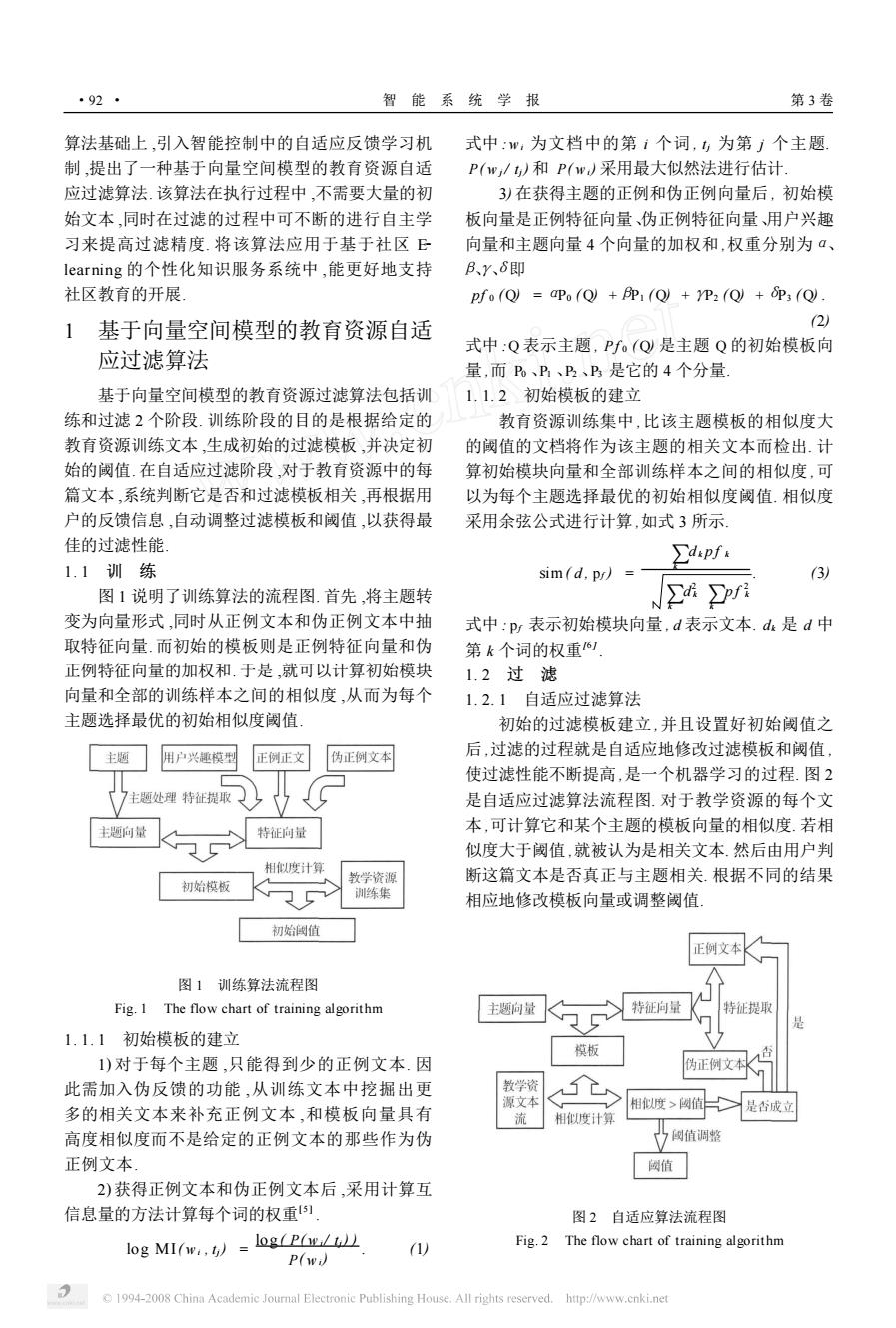
·92 智能系统学报 第3卷 算法基础上,引入智能控制中的自适应反馈学习机 式中:w:为文档中的第1个词,为第j个主题 制,提出了一种基于向量空间模型的教育资源自适 P(w,/)和P(w)采用最大似然法进行估计 应过滤算法.该算法在执行过程中,不需要大量的初 3)在获得主题的正例和伪正例向量后,初始模 始文本,同时在过滤的过程中可不断的进行自主学 板向量是正例特征向量、伪正例特征向量、用户兴趣 习来提高过滤精度.将该算法应用于基于社区E 向量和主题向量4个向量的加权和,权重分别为a、 learning的个性化知识服务系统中,能更好地支持 B、Y、6即 社区教育的开展 pfo(Q)aPo(Q)BP(Q)+YP2 (Q)P3 (Q) 1 基于向量空间模型的教育资源自适 2) 式中:Q表示主题,Pf(Q是主题Q的初始模板向 应过滤算法 量,而B、P、B、P是它的4个分量 基于向量空间模型的教育资源过滤算法包括训 1.1.2初始模板的建立 练和过滤2个阶段.训练阶段的目的是根据给定的 教育资源训练集中,比该主题模板的相似度大 教育资源训练文本,生成初始的过滤模板,并决定初 的阈值的文档将作为该主题的相关文本而检出.计 始的阈值.在自适应过滤阶段,对于教育资源中的每 算初始模块向量和全部训练样本之间的相似度,可 篇文本,系统判断它是否和过滤模板相关,再根据用 以为每个主题选择最优的初始相似度阈值.相似度 户的反馈信息,自动调整过滤模板和阈值,以获得最 采用余弦公式进行计算,如式3所示 佳的过滤性能 ∑dpfk 1.1训练 sim(d.pr) (3) 图1说明了训练算法的流程图.首先,将主题转 hpri 变为向量形式,同时从正例文本和伪正例文本中抽 式中:p表示初始模块向量,d表示文本.d是d中 取特征向量.而初始的模板则是正例特征向量和伪 第k个词的权重1 正例特征向量的加权和.于是,就可以计算初始模块 1.2过滤 向量和全部的训练样本之间的相似度,从而为每个 1.2.1自适应过滤算法 主题选择最优的初始相似度阈值 初始的过滤模板建立,并且设置好初始阈值之 主题 用户兴趣模型 正例正文 伪正例文本 后,过滤的过程就是自适应地修改过滤模板和阈值, 使过滤性能不断提高,是一个机器学习的过程.图2 主题处理特征提取 是自适应过滤算法流程图.对于教学资源的每个文 题向量 特征向量 本,可计算它和某个主题的模板向量的相似度.若相 似度大于阈值,就被认为是相关文本.然后由用户判 相似度计算 教学资源 断这篇文本是否真正与主题相关.根据不同的结果 初始模板 训练集 相应地修改模板向量或调整阈值 初始倒值 正例文本 图1训练算法流程图 Fig.1 The flow chart of training algorithm 主题向量 特征向量 特征提取 是 1.1.1初始模板的建立 慎板 1)对于每个主题,只能得到少的正例文本.因 伪正例文本 此需加入伪反馈的功能,从训练文本中挖掘出更 教学资 相似度>圆值 多的相关文本来补充正例文本,和模板向量具有 是否成立 相似度计算 高度相似度而不是给定的正例文本的那些作为伪 倒值调整 正例文本 圆值 2)获得正例文本和伪正例文本后,采用计算互 信息量的方法计算每个词的权重 图2自适应算法流程图 log MI(w.)=log(p (1) Fig.2 The flow chart of training algorithm P(wi) 1994-2008 China Academic Journal Electronic Publishing House.All rights reserved.http://www.cnki.net算法基础上 ,引入智能控制中的自适应反馈学习机 制 ,提出了一种基于向量空间模型的教育资源自适 应过滤算法. 该算法在执行过程中 ,不需要大量的初 始文本 ,同时在过滤的过程中可不断的进行自主学 习来提高过滤精度. 将该算法应用于基于社区 E2 learning 的个性化知识服务系统中 ,能更好地支持 社区教育的开展. 1 基于向量空间模型的教育资源自适 应过滤算法 基于向量空间模型的教育资源过滤算法包括训 练和过滤 2 个阶段. 训练阶段的目的是根据给定的 教育资源训练文本 ,生成初始的过滤模板 ,并决定初 始的阈值. 在自适应过滤阶段 ,对于教育资源中的每 篇文本 ,系统判断它是否和过滤模板相关 ,再根据用 户的反馈信息 ,自动调整过滤模板和阈值 ,以获得最 佳的过滤性能. 1. 1 训 练 图 1 说明了训练算法的流程图. 首先 ,将主题转 变为向量形式 ,同时从正例文本和伪正例文本中抽 取特征向量. 而初始的模板则是正例特征向量和伪 正例特征向量的加权和. 于是 ,就可以计算初始模块 向量和全部的训练样本之间的相似度 ,从而为每个 主题选择最优的初始相似度阈值. 图 1 训练算法流程图 Fig. 1 The flow chart of training algorithm 1. 1. 1 初始模板的建立 1) 对于每个主题 ,只能得到少的正例文本. 因 此需加入伪反馈的功能 ,从训练文本中挖掘出更 多的相关文本来补充正例文本 ,和模板向量具有 高度相似度而不是给定的正例文本的那些作为伪 正例文本. 2) 获得正例文本和伪正例文本后 ,采用计算互 信息量的方法计算每个词的权重[5 ] . log MI( wi , tj) = log ( P( wi / tj) ) P( wi) . (1) 式中 :wi 为文档中的第 i 个词 , tj 为第 j 个主题. P( wj / tj) 和 P( wi) 采用最大似然法进行估计. 3) 在获得主题的正例和伪正例向量后 , 初始模 板向量是正例特征向量、伪正例特征向量、用户兴趣 向量和主题向量 4 个向量的加权和 ,权重分别为α、 β、γ、δ即 pf 0 (Q) =αP0 ( Q) +βP1 ( Q) +γP2 (Q) +δP3 ( Q) . (2) 式中 :Q 表示主题 , Pf 0 ( Q) 是主题 Q 的初始模板向 量 ,而 P0 、P1 、P2 、P3 是它的 4 个分量. 1. 1. 2 初始模板的建立 教育资源训练集中 ,比该主题模板的相似度大 的阈值的文档将作为该主题的相关文本而检出. 计 算初始模块向量和全部训练样本之间的相似度 ,可 以为每个主题选择最优的初始相似度阈值. 相似度 采用余弦公式进行计算 ,如式 3 所示. sim( d , pf ) = ∑k d k p f k ∑k d 2 k ∑k p f 2 k . (3) 式中 : pf 表示初始模块向量 , d 表示文本. dk 是 d 中 第 k 个词的权重[6 ] . 1. 2 过 滤 1. 2. 1 自适应过滤算法 初始的过滤模板建立 ,并且设置好初始阈值之 后 ,过滤的过程就是自适应地修改过滤模板和阈值 , 使过滤性能不断提高 ,是一个机器学习的过程. 图 2 是自适应过滤算法流程图. 对于教学资源的每个文 本 ,可计算它和某个主题的模板向量的相似度. 若相 似度大于阈值 ,就被认为是相关文本. 然后由用户判 断这篇文本是否真正与主题相关. 根据不同的结果 相应地修改模板向量或调整阈值. 图 2 自适应算法流程图 Fig. 2 The flow chart of training algorithm · 29 · 智 能 系 统 学 报 第 3 卷