正在加载图片...
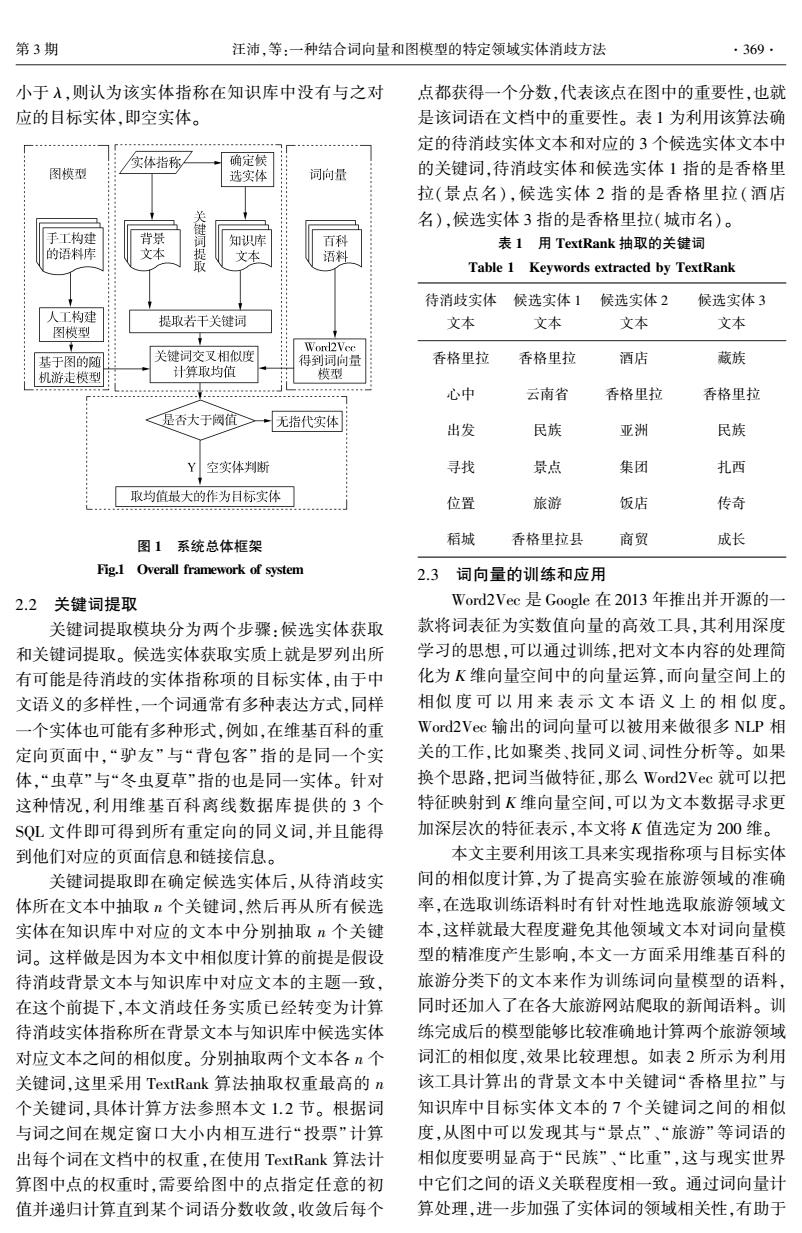
第3期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·369- 小于入,则认为该实体指称在知识库中没有与之对 点都获得一个分数,代表该点在图中的重要性,也就 应的目标实体,即空实体。 是该词语在文档中的重要性。表1为利用该算法确 定的待消歧实体文本和对应的3个候选实体文本中 /实体指称 确定候 图模型 选实体 词向量 的关键词,待消歧实体和候选实体1指的是香格里 拉(景点名),候选实体2指的是香格里拉(酒店 毽 名),候选实体3指的是香格里拉(城市名)。 手工构建 背景 知识库 百科 表I用TextRank抽取的关键词 的语料库 文本 最 文本 语料 Table 1 Keywords extracted by TextRank 待消歧实体 候选实体1 候选实体2 候选实体3 人工构建 提取若干关键词 文本 文本 文本 文本 图模型 基于图的随 关键词交叉相似度 Word2Vee 得到词问量 香格里拉 香格里拉 酒店 藏族 机游走模型 计算取均值 模型 心中 云南省 香格里拉 香格里拉 <是否大于岗值 无指代实体 出发 民族 亚洲 民族 Y空实体判断 寻找 景点 集团 扎西 取均值最大的作为目标实体 位置 旅游 饭店 传奇 图1系统总体框架 稻城 香格里拉县 商贸 成长 Fig.1 Overall framework of system 2.3词向量的训练和应用 2.2关键词提取 Word2Vec是Google在2013年推出并开源的一 关键词提取模块分为两个步骤:候选实体获取 款将词表征为实数值向量的高效工具,其利用深度 和关键词提取。候选实体获取实质上就是罗列出所 学习的思想,可以通过训练把对文本内容的处理简 有可能是待消歧的实体指称项的目标实体,由于中 化为K维向量空间中的向量运算,而向量空间上的 文语义的多样性,一个词通常有多种表达方式,同样 相似度可以用来表示文本语义上的相似度。 一个实体也可能有多种形式,例如,在维基百科的重 Word2Vec输出的词向量可以被用来做很多NLP相 定向页面中,“驴友”与“背包客”指的是同一个实 关的工作,比如聚类、找同义词、词性分析等。如果 体,“虫草”与“冬虫夏草”指的也是同一实体。针对 换个思路,把词当做特征,那么Word2Vec就可以把 这种情况,利用维基百科离线数据库提供的3个 特征映射到K维向量空间,可以为文本数据寻求更 SQL文件即可得到所有重定向的同义词,并且能得 加深层次的特征表示,本文将K值选定为200维。 到他们对应的页面信息和链接信息。 本文主要利用该工具来实现指称项与目标实体 关键词提取即在确定候选实体后,从待消歧实 间的相似度计算,为了提高实验在旅游领域的准确 体所在文本中抽取n个关键词,然后再从所有候选 率,在选取训练语料时有针对性地选取旅游领域文 实体在知识库中对应的文本中分别抽取n个关键 本,这样就最大程度避免其他领域文本对词向量模 词。这样做是因为本文中相似度计算的前提是假设 型的精准度产生影响,本文一方面采用维基百科的 待消歧背景文本与知识库中对应文本的主题一致, 旅游分类下的文本来作为训练词向量模型的语料, 在这个前提下,本文消歧任务实质已经转变为计算 同时还加入了在各大旅游网站爬取的新闻语料。训 待消歧实体指称所在背景文本与知识库中候选实体 练完成后的模型能够比较准确地计算两个旅游领域 对应文本之间的相似度。分别抽取两个文本各个 词汇的相似度,效果比较理想。如表2所示为利用 关键词,这里采用TextRank算法抽取权重最高的n 该工具计算出的背景文本中关键词“香格里拉”与 个关键词,具体计算方法参照本文1.2节。根据词 知识库中目标实体文本的7个关键词之间的相似 与词之间在规定窗口大小内相互进行“投票”计算 度,从图中可以发现其与“景点”、“旅游”等词语的 出每个词在文档中的权重,在使用TextRank算法计 相似度要明显高于“民族”、“比重”,这与现实世界 算图中点的权重时,需要给图中的点指定任意的初 中它们之间的语义关联程度相一致。通过词向量计 值并递归计算直到某个词语分数收敛,收敛后每个 算处理,进一步加强了实体词的领域相关性,有助于小于 λ,则认为该实体指称在知识库中没有与之对 应的目标实体,即空实体。 图 1 系统总体框架 Fig.1 Overall framework of system 2.2 关键词提取 关键词提取模块分为两个步骤:候选实体获取 和关键词提取。 候选实体获取实质上就是罗列出所 有可能是待消歧的实体指称项的目标实体,由于中 文语义的多样性,一个词通常有多种表达方式,同样 一个实体也可能有多种形式,例如,在维基百科的重 定向页面中,“驴友” 与“背包客” 指的是同一个实 体,“虫草”与“冬虫夏草”指的也是同一实体。 针对 这种情况,利用维基百科离线数据库提供的 3 个 SQL 文件即可得到所有重定向的同义词,并且能得 到他们对应的页面信息和链接信息。 关键词提取即在确定候选实体后,从待消歧实 体所在文本中抽取 n 个关键词,然后再从所有候选 实体在知识库中对应的文本中分别抽取 n 个关键 词。 这样做是因为本文中相似度计算的前提是假设 待消歧背景文本与知识库中对应文本的主题一致, 在这个前提下,本文消歧任务实质已经转变为计算 待消歧实体指称所在背景文本与知识库中候选实体 对应文本之间的相似度。 分别抽取两个文本各 n 个 关键词,这里采用 TextRank 算法抽取权重最高的 n 个关键词,具体计算方法参照本文 1.2 节。 根据词 与词之间在规定窗口大小内相互进行“投票” 计算 出每个词在文档中的权重,在使用 TextRank 算法计 算图中点的权重时,需要给图中的点指定任意的初 值并递归计算直到某个词语分数收敛,收敛后每个 点都获得一个分数,代表该点在图中的重要性,也就 是该词语在文档中的重要性。 表 1 为利用该算法确 定的待消歧实体文本和对应的 3 个候选实体文本中 的关键词,待消歧实体和候选实体 1 指的是香格里 拉(景点名),候选实体 2 指的是香格里拉( 酒店 名),候选实体 3 指的是香格里拉(城市名)。 表 1 用 TextRank 抽取的关键词 Table 1 Keywords extracted by TextRank 待消歧实体 文本 候选实体 1 文本 候选实体 2 文本 候选实体 3 文本 香格里拉 香格里拉 酒店 藏族 心中 云南省 香格里拉 香格里拉 出发 民族 亚洲 民族 寻找 景点 集团 扎西 位置 旅游 饭店 传奇 稻城 香格里拉县 商贸 成长 2.3 词向量的训练和应用 Word2Vec 是 Google 在 2013 年推出并开源的一 款将词表征为实数值向量的高效工具,其利用深度 学习的思想,可以通过训练,把对文本内容的处理简 化为 K 维向量空间中的向量运算,而向量空间上的 相似 度 可 以 用 来 表 示 文 本 语 义 上 的 相 似 度。 Word2Vec 输出的词向量可以被用来做很多 NLP 相 关的工作,比如聚类、找同义词、词性分析等。 如果 换个思路,把词当做特征,那么 Word2Vec 就可以把 特征映射到 K 维向量空间,可以为文本数据寻求更 加深层次的特征表示,本文将 K 值选定为 200 维。 本文主要利用该工具来实现指称项与目标实体 间的相似度计算,为了提高实验在旅游领域的准确 率,在选取训练语料时有针对性地选取旅游领域文 本,这样就最大程度避免其他领域文本对词向量模 型的精准度产生影响,本文一方面采用维基百科的 旅游分类下的文本来作为训练词向量模型的语料, 同时还加入了在各大旅游网站爬取的新闻语料。 训 练完成后的模型能够比较准确地计算两个旅游领域 词汇的相似度,效果比较理想。 如表 2 所示为利用 该工具计算出的背景文本中关键词“香格里拉” 与 知识库中目标实体文本的 7 个关键词之间的相似 度,从图中可以发现其与“景点”、“旅游”等词语的 相似度要明显高于“民族”、“比重”,这与现实世界 中它们之间的语义关联程度相一致。 通过词向量计 算处理,进一步加强了实体词的领域相关性,有助于 第 3 期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·369·