正在加载图片...
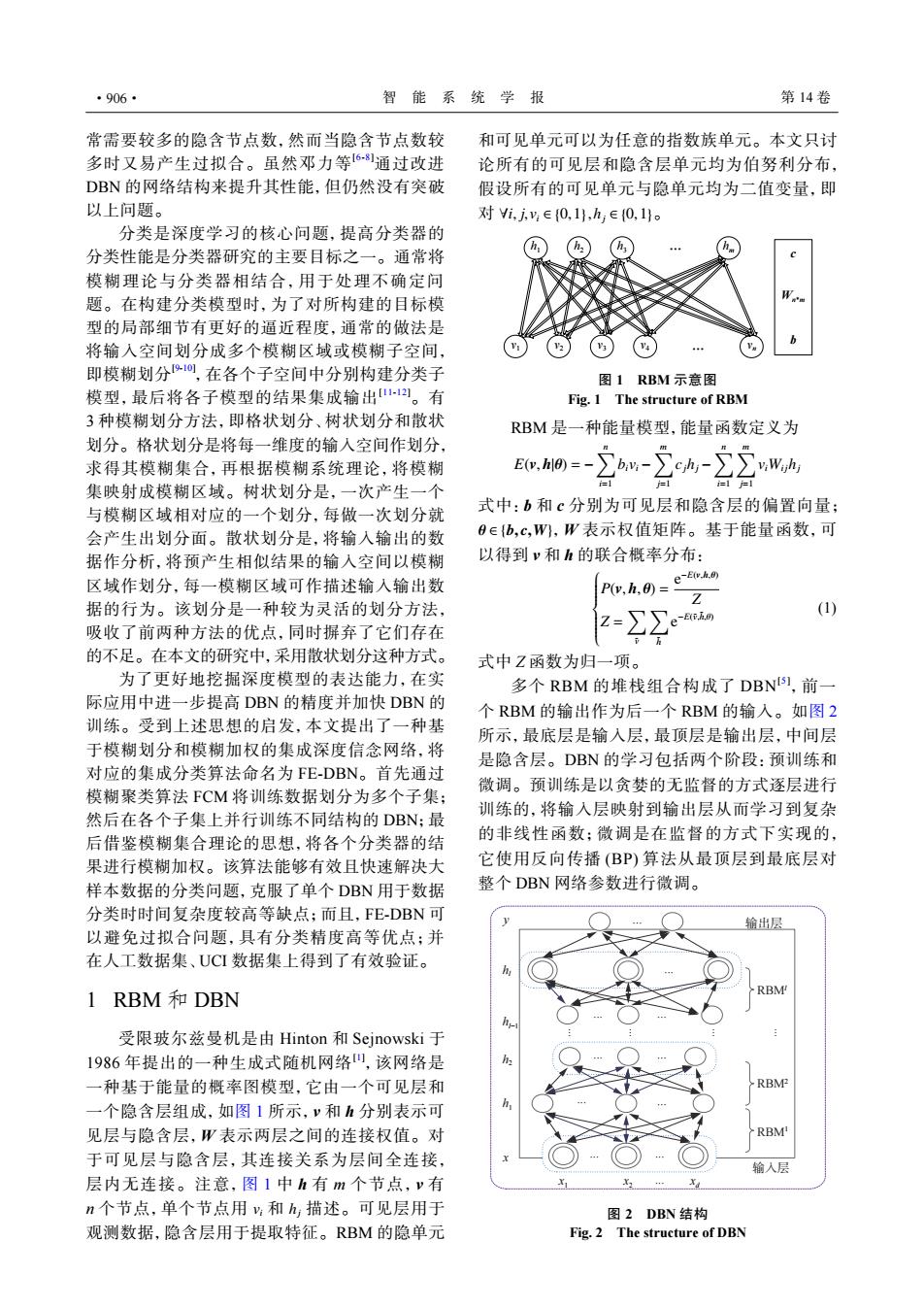
·906· 智能系统学报 第14卷 常需要较多的隐含节点数,然而当隐含节点数较 和可见单元可以为任意的指数族单元。本文只讨 多时又易产生过拟合。虽然邓力等6别通过改进 论所有的可见层和隐含层单元均为伯努利分布 DBN的网络结构来提升其性能,但仍然没有突破 假设所有的可见单元与隐单元均为二值变量,即 以上问题。 对i,j,y∈{0,1,h∈0,1o 分类是深度学习的核心问题,提高分类器的 分类性能是分类器研究的主要目标之一。通常将 模糊理论与分类器相结合,用于处理不确定问 题。在构建分类模型时,为了对所构建的目标模 型的局部细节有更好的逼近程度,通常的做法是 将输入空间划分成多个模糊区域或模糊子空间, 即模糊划分,在各个子空间中分别构建分类子 图1RBM示意图 模型,最后将各子模型的结果集成输出12。有 Fig.1 The structure of RBM 3种模糊划分方法,即格状划分、树状划分和散状 RBM是一种能量模型,能量函数定义为 划分。格状划分是将每一维度的输入空间作划分, 求得其模糊集合,再根据模糊系统理论,将模糊 m0=一-2m-2h-22wh 集映射成模糊区域。树状划分是,一次产生一个 与模糊区域相对应的一个划分,每做一次划分就 式中:b和c分别为可见层和隐含层的偏置向量; 会产生出划分面。散状划分是,将输入输出的数 0∈{b,c,W,W表示权值矩阵。基于能量函数,可 据作分析,将预产生相似结果的输入空间以模糊 以得到y和h的联合概率分布: 区域作划分,每一模糊区域可作描述输人输出数 P(y,h,)=e-tro Z 据的行为。该划分是一种较为灵活的划分方法, 吸收了前两种方法的优点,同时摒弃了它们存在 2-22 (1) 的不足。在本文的研究中,采用散状划分这种方式。 式中Z函数为归一项。 为了更好地挖掘深度模型的表达能力,在实 多个RBM的堆栈组合构成了DBNI,前一 际应用中进一步提高DBN的精度并加快DBN的 个RBM的输出作为后一个RBM的输入。如图2 训练。受到上述思想的启发,本文提出了一种基 所示,最底层是输入层,最顶层是输出层,中间层 于模糊划分和模糊加权的集成深度信念网络,将 是隐含层。DBN的学习包括两个阶段:预训练和 对应的集成分类算法命名为FE-DBN。首先通过 微调。预训练是以贪婪的无监督的方式逐层进行 模糊聚类算法FCM将训练数据划分为多个子集; 然后在各个子集上并行训练不同结构的DBN:最 训练的,将输入层映射到输出层从而学习到复杂 后借鉴模糊集合理论的思想,将各个分类器的结 的非线性函数;微调是在监督的方式下实现的, 果进行模糊加权。该算法能够有效且快速解决大 它使用反向传播(BP)算法从最顶层到最底层对 样本数据的分类问题,克服了单个DBN用于数据 整个DBN网络参数进行微调。 分类时时间复杂度较高等缺点;而且,FE-DBN可 输出层 以避免过拟合问题,具有分类精度高等优点;并 在人工数据集、UCI数据集上得到了有效验证。 BM 1RBM和DBN h 受限玻尔兹曼机是由Hinton和Sejnowski于 1986年提出的一种生成式随机网络口,该网络是 一种基于能量的概率图模型,它由一个可见层和 RBM 一个隐含层组成,如图1所示,v和h分别表示可 h 见层与隐含层,W表示两层之间的连接权值。对 RBM 于可见层与隐含层,其连接关系为层间全连接, 输入层 层内无连接。注意,图1中h有m个节点,v有 n个节点,单个节点用y:和h描述。可见层用于 图2DBN结构 观测数据,隐含层用于提取特征。RBM的隐单元 Fig.2 The structure of DBN常需要较多的隐含节点数,然而当隐含节点数较 多时又易产生过拟合。虽然邓力等[6-8]通过改进 DBN 的网络结构来提升其性能,但仍然没有突破 以上问题。 分类是深度学习的核心问题,提高分类器的 分类性能是分类器研究的主要目标之一。通常将 模糊理论与分类器相结合,用于处理不确定问 题。在构建分类模型时,为了对所构建的目标模 型的局部细节有更好的逼近程度,通常的做法是 将输入空间划分成多个模糊区域或模糊子空间, 即模糊划分[9-10] ,在各个子空间中分别构建分类子 模型,最后将各子模型的结果集成输出[11-12]。有 3 种模糊划分方法,即格状划分、树状划分和散状 划分。格状划分是将每一维度的输入空间作划分, 求得其模糊集合,再根据模糊系统理论,将模糊 集映射成模糊区域。树状划分是,一次产生一个 与模糊区域相对应的一个划分,每做一次划分就 会产生出划分面。散状划分是,将输入输出的数 据作分析,将预产生相似结果的输入空间以模糊 区域作划分,每一模糊区域可作描述输入输出数 据的行为。该划分是一种较为灵活的划分方法, 吸收了前两种方法的优点,同时摒弃了它们存在 的不足。在本文的研究中,采用散状划分这种方式。 为了更好地挖掘深度模型的表达能力,在实 际应用中进一步提高 DBN 的精度并加快 DBN 的 训练。受到上述思想的启发,本文提出了一种基 于模糊划分和模糊加权的集成深度信念网络,将 对应的集成分类算法命名为 FE-DBN。首先通过 模糊聚类算法 FCM 将训练数据划分为多个子集; 然后在各个子集上并行训练不同结构的 DBN;最 后借鉴模糊集合理论的思想,将各个分类器的结 果进行模糊加权。该算法能够有效且快速解决大 样本数据的分类问题,克服了单个 DBN 用于数据 分类时时间复杂度较高等缺点;而且,FE-DBN 可 以避免过拟合问题,具有分类精度高等优点;并 在人工数据集、UCI 数据集上得到了有效验证。 1 RBM 和 DBN vi hj 受限玻尔兹曼机是由 Hinton 和 Sejnowski 于 1986 年提出的一种生成式随机网络[1] ,该网络是 一种基于能量的概率图模型,它由一个可见层和 一个隐含层组成,如图 1 所示,v 和 h 分别表示可 见层与隐含层,W 表示两层之间的连接权值。对 于可见层与隐含层,其连接关系为层间全连接, 层内无连接。注意,图 1 中 h 有 m 个节点,v 有 n 个节点,单个节点用 和 描述。可见层用于 观测数据,隐含层用于提取特征。RBM 的隐单元 ∀i, j, vi ∈ {0,1},hj ∈ {0,1} 和可见单元可以为任意的指数族单元。本文只讨 论所有的可见层和隐含层单元均为伯努利分布, 假设所有的可见单元与隐单元均为二值变量,即 对 。 h1 v1 v2 v3 v4 vn h2 h3 … hm … Wn*m c b 图 1 RBM 示意图 Fig. 1 The structure of RBM RBM 是一种能量模型,能量函数定义为 E(v, h|θ) = − ∑n i=1 bivi − ∑m j=1 cjhj − ∑n i=1 ∑m j=1 viWi jhj θ ∈ {b, c,W} 式中:b 和 c 分别为可见层和隐含层的偏置向量; ,W 表示权值矩阵。基于能量函数,可 以得到 v 和 h 的联合概率分布: P(v, h,θ) = e −E(v,h,θ) Z Z = ∑ v˜ ∑ h˜ e −E(˜v,h˜,θ) (1) 式中 Z 函数为归一项。 多个 RBM 的堆栈组合构成了 DBN[5] ,前一 个 RBM 的输出作为后一个 RBM 的输入。如图 2 所示,最底层是输入层,最顶层是输出层,中间层 是隐含层。DBN 的学习包括两个阶段:预训练和 微调。预训练是以贪婪的无监督的方式逐层进行 训练的,将输入层映射到输出层从而学习到复杂 的非线性函数;微调是在监督的方式下实现的, 它使用反向传播 (BP) 算法从最顶层到最底层对 整个 DBN 网络参数进行微调。 y hl h2 h1 x x1 x2 xd hl−1 ... 输出层 ... ... ... ... ... ... ... ... ... ... ... ... ... ... RBMl RBM2 RBM1 输入层 图 2 DBN 结构 Fig. 2 The structure of DBN ·906· 智 能 系 统 学 报 第 14 卷