正在加载图片...
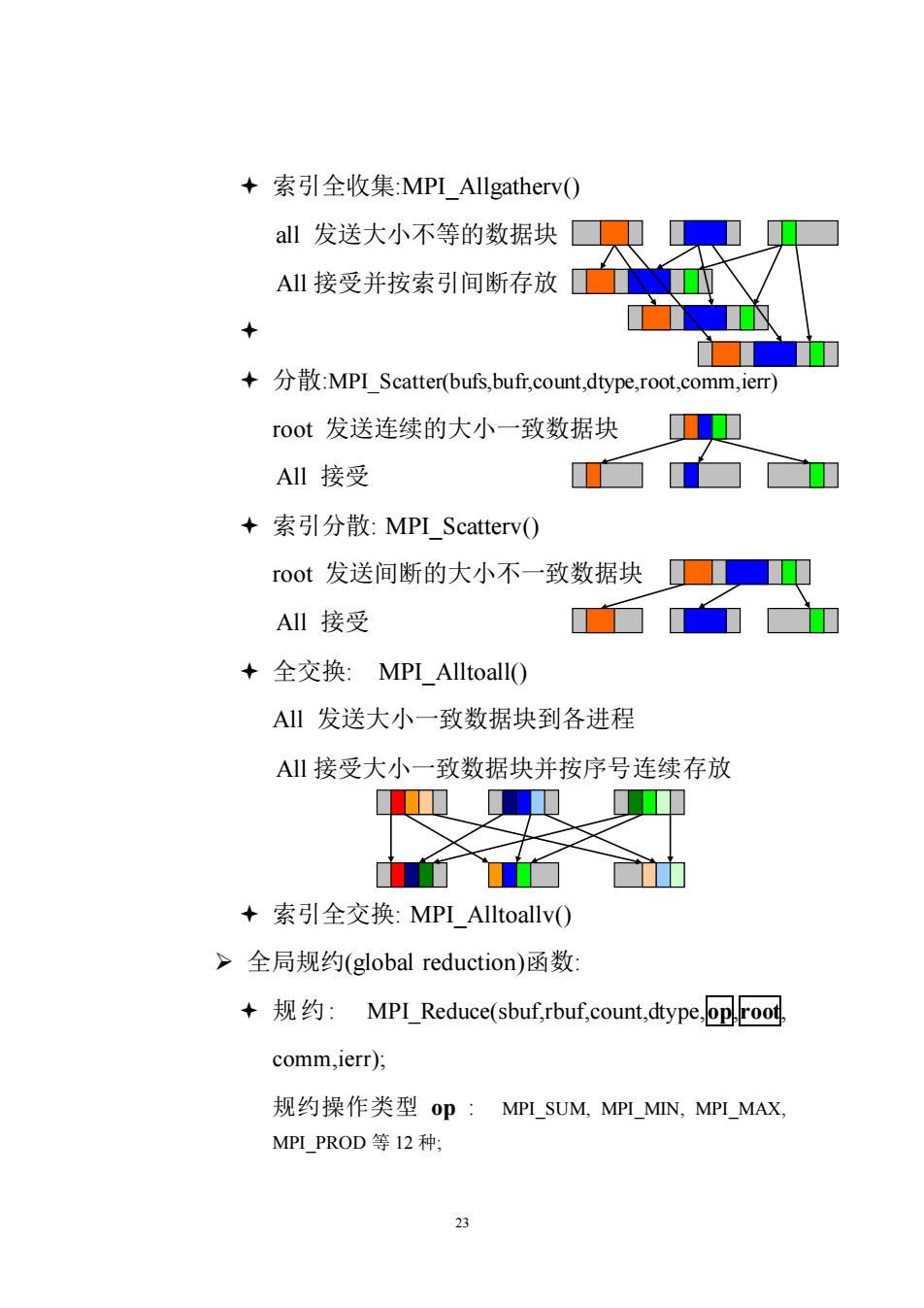
+索引全收集:MPI Allgatherv() all发送大小不等的数据块■口 A1接受并按索引间断存放 +分散:MPI Scatter(bufs,buf,count,dtype,root,comm,ier) root发送连续的大小一致数据块 AIl接受 +索引分散:MPI Scatterv() root发送间断的大小不一致数据块☐■ AI1接受 +全交换:MPI AlltoallO AI发送大小一致数据块到各进程 A1接受大小一致数据块并按序号连续存放 T T +索引全交换:MPI Alltoallv() >全局规约(global reduction)函数 +规约:MPI Reduce(sbuf,rbuf,count,dype,oproot. comm,ierr); 规约操作类型Op:MPI_SUM,MPI_MIN,MPI_MAX, MPI_PROD等I2种; 23 索引全收集:MPI_Allgatherv() all 发送大小不等的数据块 All 接受并按索引间断存放 分散:MPI_Scatter(bufs,bufr,count,dtype,root,comm,ierr) root 发送连续的大小一致数据块 All 接受 索引分散: MPI_Scatterv() root 发送间断的大小不一致数据块 All 接受 全交换: MPI_Alltoall() All 发送大小一致数据块到各进程 All 接受大小一致数据块并按序号连续存放 索引全交换: MPI_Alltoallv() ➢ 全局规约(global reduction)函数: 规约: MPI_Reduce(sbuf,rbuf,count,dtype,op,root, comm,ierr); 规约操作类型 op : MPI_SUM, MPI_MIN, MPI_MAX, MPI_PROD 等 12 种;