正在加载图片...
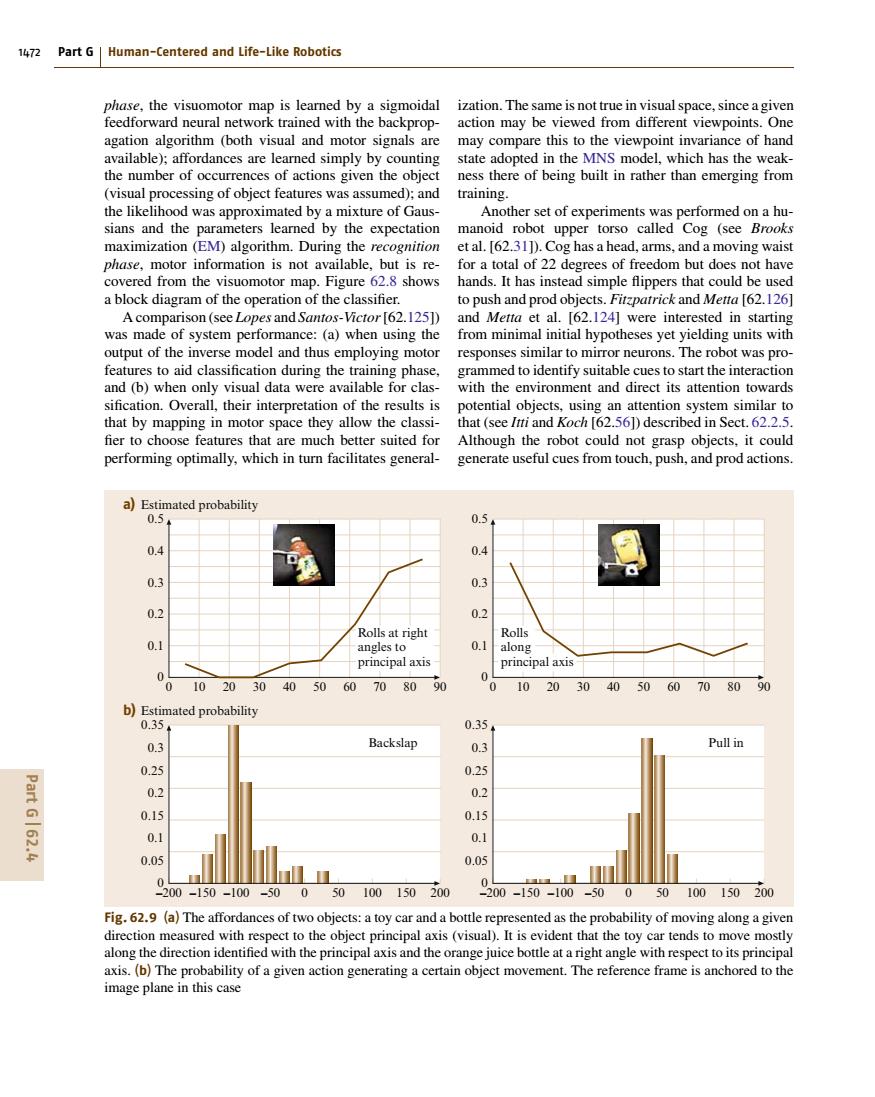
1472 Part G Human-Centered and Life-Like Robotics phase.the visuomotor map is learned by a sigmoidal ization.The same is not true in visual space,since a given feedforward neural network trained with the backprop- action may be viewed from different viewpoints.One agation algorithm (both visual and motor signals are may compare this to the viewpoint invariance of hand available);affordances are learned simply by counting state adopted in the MNS model,which has the weak- the number of occurrences of actions given the object ness there of being built in rather than emerging from (visual processing of object features was assumed);and training. the likelihood was approximated by a mixture of Gaus- Another set of experiments was performed on a hu- sians and the parameters learned by the expectation manoid robot upper torso called Cog (see Brooks maximization (EM)algorithm.During the recognition et al.[62.311).Cog has a head,arms,and a moving waist phase,motor information is not available,but is re-for a total of 22 degrees of freedom but does not have covered from the visuomotor map.Figure 62.8 shows hands.It has instead simple flippers that could be used a block diagram of the operation of the classifier. to push and prod objects.Fitzpatrick and Metta [62.126] A comparison(see Lopes and Santos-Victor[62.125])and Metta et al.[62.124]were interested in starting was made of system performance:(a)when using the from minimal initial hypotheses yet yielding units with output of the inverse model and thus employing motor responses similar to mirror neurons.The robot was pro- features to aid classification during the training phase,grammed to identify suitable cues to start the interaction and (b)when only visual data were available for clas-with the environment and direct its attention towards sification.Overall,their interpretation of the results is potential objects,using an attention system similar to that by mapping in motor space they allow the classi-that(see Itti and Koch [62.561)described in Sect.62.2.5. fier to choose features that are much better suited for Although the robot could not grasp objects,it could performing optimally,which in turn facilitates general- generate useful cues from touch,push,and prod actions. a)Estimated probability 0.5 0.5 0.4 04 0.3 0.3 0.2 0.2 Rolls at right Rolls 0.1 angles to 0.1 along principal axis principal axis 0 0 0 10203040506070 8090 0 102030405060708090 b)Estimated probability 0.35. 0.35+ 0.3 Backslap 0.3 Pull in 0.25 0.25 Part G62.4 0.2 0.2 0.15 0.15 0.1 0.1 0.05 0.05 -200-150-100-50050100150200 -200-150-100-500 50100150200 Fig.62.9 (a)The affordances of two objects:a toy car and a bottle represented as the probability of moving along a given direction measured with respect to the object principal axis(visual).It is evident that the toy car tends to move mostly along the direction identified with the principal axis and the orange juice bottle at a right angle with respect to its principal axis.(b)The probability of a given action generating a certain object movement.The reference frame is anchored to the image plane in this case1472 Part G Human-Centered and Life-Like Robotics phase, the visuomotor map is learned by a sigmoidal feedforward neural network trained with the backpropagation algorithm (both visual and motor signals are available); affordances are learned simply by counting the number of occurrences of actions given the object (visual processing of object features was assumed); and the likelihood was approximated by a mixture of Gaussians and the parameters learned by the expectation maximization (EM) algorithm. During the recognition phase, motor information is not available, but is recovered from the visuomotor map. Figure 62.8 shows a block diagram of the operation of the classifier. A comparison (see Lopes and Santos-Victor[62.125]) was made of system performance: (a) when using the output of the inverse model and thus employing motor features to aid classification during the training phase, and (b) when only visual data were available for classification. Overall, their interpretation of the results is that by mapping in motor space they allow the classi- fier to choose features that are much better suited for performing optimally, which in turn facilitates general- 0 10 20 30 40 50 60 70 80 90 a) Estimated probability Rolls at right angles to principal axis Rolls along principal axis 0.5 0.4 0.3 0.2 0.1 0 0 10 20 30 40 50 60 70 80 90 0.5 0.4 0.3 0.2 0.1 0 –200 –150 –100 –50 0 50 100 150 200 b) Estimated probability Backslap 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 –200 –150 –100 –50 0 50 100 150 200 Pull in 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 Fig. 62.9 (a) The affordances of two objects: a toy car and a bottle represented as the probability of moving along a given direction measured with respect to the object principal axis (visual). It is evident that the toy car tends to move mostly along the direction identified with the principal axis and the orange juice bottle at a right angle with respect to its principal axis. (b) The probability of a given action generating a certain object movement. The reference frame is anchored to the image plane in this case ization. The same is not true in visual space, since a given action may be viewed from different viewpoints. One may compare this to the viewpoint invariance of hand state adopted in the MNS model, which has the weakness there of being built in rather than emerging from training. Another set of experiments was performed on a humanoid robot upper torso called Cog (see Brooks et al. [62.31]). Cog has a head, arms, and a moving waist for a total of 22 degrees of freedom but does not have hands. It has instead simple flippers that could be used to push and prod objects. Fitzpatrick and Metta [62.126] and Metta et al. [62.124] were interested in starting from minimal initial hypotheses yet yielding units with responses similar to mirror neurons. The robot was programmed to identify suitable cues to start the interaction with the environment and direct its attention towards potential objects, using an attention system similar to that (see Itti and Koch [62.56]) described in Sect. 62.2.5. Although the robot could not grasp objects, it could generate useful cues from touch, push, and prod actions. Part G 62.4