正在加载图片...
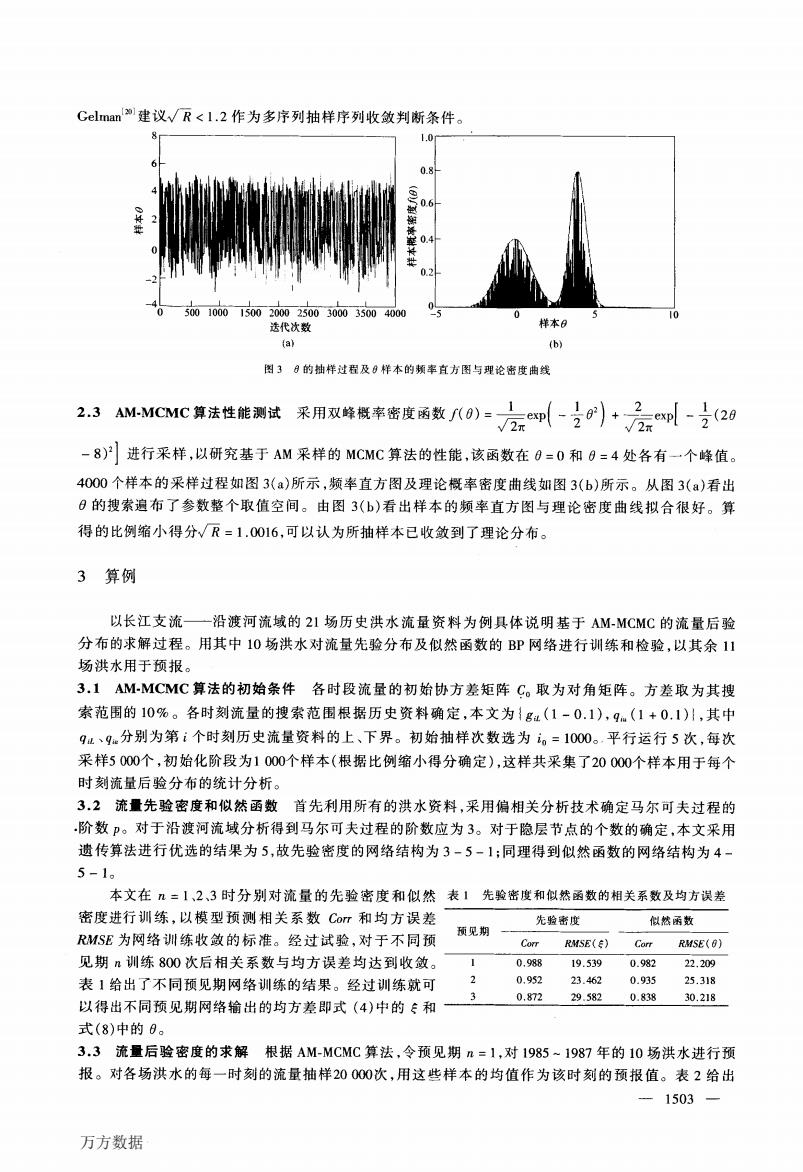
Gelman建议√R<l.2作为多序列抽样序列收敛判断条件。 1.0 0.2 0.2 5001000150020002500300035004000 0 选代次数 样本8 (a) (b) 图3日的轴样过程及8样本的频率直方图与理论密度曲线 2.3 AM-MCMC算法性能测试采用双峰概率密度函数/八0)=方即-0)小+云-之20 2元 -8)2进行采样,以研究基于AM采样的MCMC算法的性能,该函数在0=0和0=4处各有一个峰值。 4000个样本的采样过程如图3(a)所示,频率直方图及理论概率密度曲线如图3(b)所示。从图3(a)看出 日的搜索遍布了参数整个取值空间。由图3(b)看出样本的频率直方图与理论密度曲线拟合很好。算 得的比例缩小得分√R=1.0016,可以认为所抽样本已收敛到了理论分布。 3算例 以长江支流一沿渡河流域的21场历史洪水流量资料为例具体说明基于AM-MCMC的流量后验 分布的求解过程。用其中10场洪水对流量先验分布及似然函数的BP网络进行训练和检验,以其余11 场洪水用于预报。 3.1AM-MCMC算法的初始条件各时段流量的初始协方差矩阵C。取为对角矩阵。方差取为其搜 索范围的10%。各时刻流量的搜索范围根据历史资料确定,本文为{g1(1-0.1),q(1+0.1)川,其中 9L、9分别为第i个时刻历史流量资料的上、下界。初始抽样次数选为i。=1000。平行运行5次,每次 采样5000个,初始化阶段为1000个样本(根据比例缩小得分确定),这样共采集了20000个样本用于每个 时刻流量后验分布的统计分析。 3.2流量先验密度和似然函数首先利用所有的洪水资料,采用偏相关分析技术确定马尔可夫过程的 阶数。对于沿渡河流域分析得到马尔可夫过程的阶数应为3。对于隐层节点的个数的确定,本文采用 遗传算法进行优选的结果为5,故先验密度的网络结构为3-5-1:同理得到似然函数的网络结构为4- 5-1。 本文在n=1、2、3时分别对流量的先验密度和似然表1先验密度和似然函数的相关系数及均方误差 密度进行训练,以模型预测相关系数Com和均方误差 先验密度 似然函数 预见期 RMSE为网络训练收敛的标准。经过试验,对于不同预 Corr RMSE() Corr RMSE(0) 见期n训练800次后相关系数与均方误差均达到收敛。 0,988 19.539 0.982 22.209 表1给出了不同预见期网络训练的结果。经过训练就可 2 0.952 23.462 0.935 25.318 3 0.872 29.5820.838 30.218 以得出不同预见期网络输出的均方差即式(4)中的:和 式(8)中的0。 3.3流量后验密度的求解根据AM-MCMC算法,令预见期n=1,对1985~1987年的10场洪水进行预 报。对各场洪水的每一时刻的流量抽样20000次,用这些样本的均值作为该时刻的预报值。表2给出 -1503— 万方数据万方数据