正在加载图片...
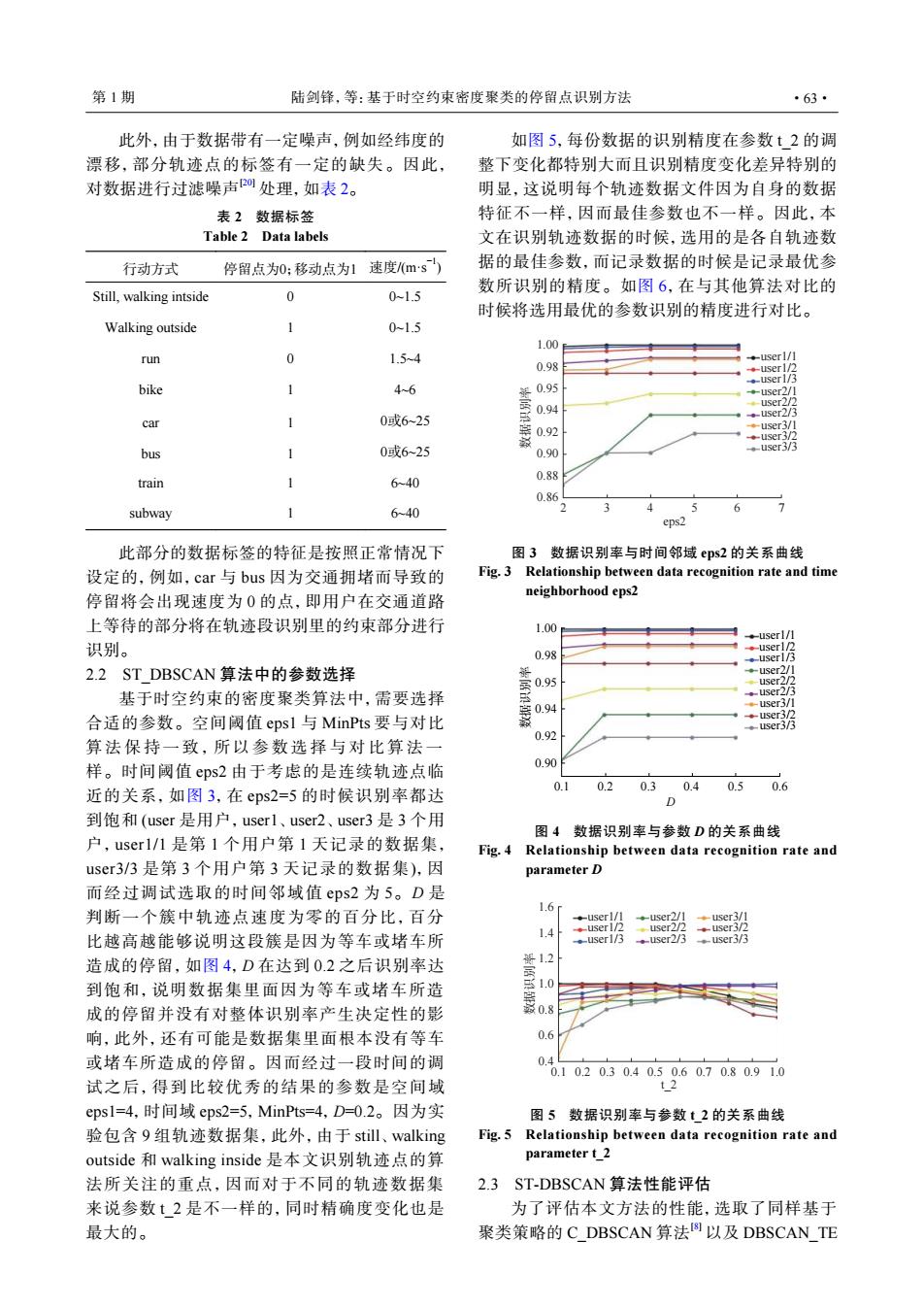
第1期 陆剑锋,等:基于时空约束密度聚类的停留点识别方法 ·63· 此外,由于数据带有一定噪声,例如经纬度的 如图5,每份数据的识别精度在参数t2的调 漂移,部分轨迹点的标签有一定的缺失。因此, 整下变化都特别大而且识别精度变化差异特别的 对数据进行过滤噪声0处理,如表2。 明显,这说明每个轨迹数据文件因为自身的数据 表2数据标签 特征不一样,因而最佳参数也不一样。因此,本 Table 2 Data labels 文在识别轨迹数据的时候,选用的是各自轨迹数 行动方式 停留点为0:移动点为1速度/ms) 据的最佳参数,而记录数据的时候是记录最优参 数所识别的精度。如图6,在与其他算法对比的 Still,walking intside 0 01.5 时候将选用最优的参数识别的精度进行对比。 Walking outside 0-1.5 1.00 run 0 1.5-4 0.98 1 bike 1 4-6 ¥0.95 -user2/1 car 0或6-25 -user2/ ◆user3/1 bus 0或6-25 0.90 潮 train 1 6-40 0.88 0.86 4 7 subway 6-40 5 6 eps2 此部分的数据标签的特征是按照正常情况下 图3数据识别率与时间邻域eps2的关系曲线 设定的,例如,car与bus因为交通拥堵而导致的 Fig.3 Relationship between data recognition rate and time neighborhood eps2 停留将会出现速度为0的点,即用户在交通道路 上等待的部分将在轨迹段识别里的约束部分进行 1.00 识别。 0.98 -user 2.2 ST DBSCAN算法中的参数选择 ◆-user∠ 基于时空约束的密度聚类算法中,需要选择 user 0.94 -user3/1 合适的参数。空间阈值epsl与MinPts要与对比 userj/ user3/3 0.92 算法保持一致,所以参数选择与对比算法一 样。时间阈值eps2由于考虑的是连续轨迹点临 0.90 0.2 0.30.40.50.6 近的关系,如图3,在eps2=5的时候识别率都达 01 0 到饱和(user是用户,user1、user2、user3是3个用 图4数据识别率与参数D的关系曲线 户,user1/1是第1个用户第1天记录的数据集, Fig.4 Relationship between data recognition rate and user3/3是第3个用户第3天记录的数据集),因 parameter D 而经过调试选取的时间邻域值eps2为5。D是 1.6 判断一个簇中轨迹点速度为零的百分比,百分 ◆-user1/.1 ◆-User2/1+user3/1 user2/2 user3/2 比越高越能够说明这段簇是因为等车或堵车所 1.4 -user1/3 user2/3 -user3/3 造成的停留,如图4,D在达到0.2之后识别率达 1.2 到饱和,说明数据集里面因为等车或堵车所造 1.0 成的停留并没有对整体识别率产生决定性的影 0.8 响,此外,还有可能是数据集里面根本没有等车 0.6 或堵车所造成的停留。因而经过一段时间的调 0. 0.10.20.30.40.50.60.70.80.91.0 试之后,得到比较优秀的结果的参数是空间域 t 2 epsl=4,时间域eps2=5,MinPts=4,D=0.2。因为实 图5数据识别率与参数t2的关系曲线 验包含9组轨迹数据集,此外,由于still、walking Fig.5 Relationship between data recognition rate and outside和walking inside是本文识别轨迹点的算 parameter t_2 法所关注的重点,因而对于不同的轨迹数据集 2.3 ST-DBSCAN算法性能评估 来说参数t2是不一样的,同时精确度变化也是 为了评估本文方法的性能,选取了同样基于 最大的。 聚类策略的C DBSCAN算法阁以及DBSCAN TE此外,由于数据带有一定噪声,例如经纬度的 漂移,部分轨迹点的标签有一定的缺失。因此, 对数据进行过滤噪声[20] 处理,如表 2。 表 2 数据标签 Table 2 Data labels 行动方式 停留点为0;移动点为1 速度/(m·s−1) Still, walking intside 0 0~1.5 Walking outside 1 0~1.5 run 0 1.5~4 bike 1 4~6 car 1 0或6~25 bus 1 0或6~25 train 1 6~40 subway 1 6~40 此部分的数据标签的特征是按照正常情况下 设定的,例如,car 与 bus 因为交通拥堵而导致的 停留将会出现速度为 0 的点,即用户在交通道路 上等待的部分将在轨迹段识别里的约束部分进行 识别。 2.2 ST_DBSCAN 算法中的参数选择 基于时空约束的密度聚类算法中,需要选择 合适的参数。空间阈值 eps1 与 MinPts 要与对比 算法保持一致,所以参数选择与对比算法一 样。时间阈值 eps2 由于考虑的是连续轨迹点临 近的关系,如图 3,在 eps2=5 的时候识别率都达 到饱和 (user 是用户,user1、user2、user3 是 3 个用 户 ,user1/1 是第 1 个用户第 1 天记录的数据集, user3/3 是第 3 个用户第 3 天记录的数据集),因 而经过调试选取的时间邻域值 eps2 为 5。D 是 判断一个簇中轨迹点速度为零的百分比,百分 比越高越能够说明这段簇是因为等车或堵车所 造成的停留,如图 4,D 在达到 0.2 之后识别率达 到饱和,说明数据集里面因为等车或堵车所造 成的停留并没有对整体识别率产生决定性的影 响,此外,还有可能是数据集里面根本没有等车 或堵车所造成的停留。因而经过一段时间的调 试之后,得到比较优秀的结果的参数是空间域 eps1=4,时间域 eps2=5,MinPts=4,D=0.2。因为实 验包含 9 组轨迹数据集,此外,由于 still、walking outside 和 walking inside 是本文识别轨迹点的算 法所关注的重点,因而对于不同的轨迹数据集 来说参数 t_2 是不一样的,同时精确度变化也是 最大的。 如图 5,每份数据的识别精度在参数 t_2 的调 整下变化都特别大而且识别精度变化差异特别的 明显,这说明每个轨迹数据文件因为自身的数据 特征不一样,因而最佳参数也不一样。因此,本 文在识别轨迹数据的时候,选用的是各自轨迹数 据的最佳参数,而记录数据的时候是记录最优参 数所识别的精度。如图 6,在与其他算法对比的 时候将选用最优的参数识别的精度进行对比。 1.00 0.98 0.95 0.94 0.92 0.90 0.88 0.86 2 3 4 eps2 5 6 7 user2/1 user2/2 user2/3 user1/1 user1/2 user1/3 user3/1 user3/2 数据识别率 user3/3 图 3 数据识别率与时间邻域 eps2 的关系曲线 Fig. 3 Relationship between data recognition rate and time neighborhood eps2 1.00 0.98 0.95 0.94 0.92 0.90 0.1 0.2 0.3 0.4 0.5 0.6 user2/1 user2/2 user2/3 user1/1 user1/2 user1/3 user3/1 user3/2 数据识别率 user3/3 D 图 4 数据识别率与参数 D 的关系曲线 Fig. 4 Relationship between data recognition rate and parameter D 1.6 1.4 1.2 1.0 0.8 0.6 0.4 0.1 0.2 0.3 0.4 0.5 0.6 t_2 0.7 0.8 0.9 1.0 user2/1 user2/2 user2/3 user1/1 user1/2 user1/3 user3/1 user3/2 user3/3 数据识别率 图 5 数据识别率与参数 t_2 的关系曲线 Fig. 5 Relationship between data recognition rate and parameter t_2 2.3 ST-DBSCAN 算法性能评估 为了评估本文方法的性能,选取了同样基于 聚类策略的 C_DBSCAN 算法[8] 以及 DBSCAN_TE 第 1 期 陆剑锋,等:基于时空约束密度聚类的停留点识别方法 ·63·