正在加载图片...
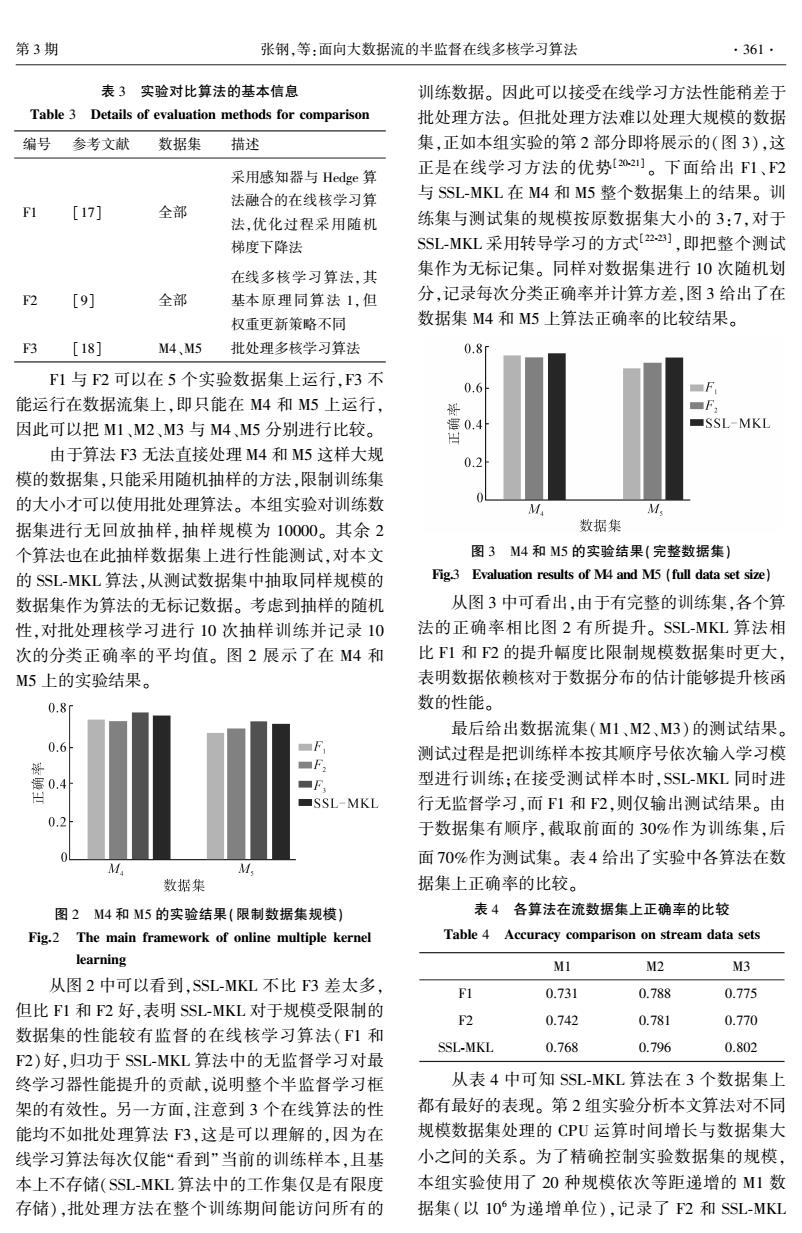
第3期 张钢,等:面向大数据流的半监督在线多核学习算法 ·361. 表3实验对比算法的基本信息 训练数据。因此可以接受在线学习方法性能稍差于 Table 3 Details of evaluation methods for comparison 批处理方法。但批处理方法难以处理大规模的数据 编号 参考文献 数据集 描述 集,正如本组实验的第2部分即将展示的(图3),这 采用感知器与Hedge算 正是在线学习方法的优势[02]。下面给出F1、2 法融合的在线核学习算 与SSL-MKL在M4和M5整个数据集上的结果。训 [17] 全部 法,优化过程采用随机 练集与测试集的规模按原数据集大小的3:7,对于 梯度下降法 SSL-MKL采用转导学习的方式[22】,即把整个测试 在线多核学习算法,其 集作为无标记集。同样对数据集进行10次随机划 F2 [9] 全部 基本原理同算法1,但 分,记录每次分类正确率并计算方差,图3给出了在 权重更新策略不同 数据集M4和M5上算法正确率的比较结果。 3 [18] M4、M5 批处理多核学习算法 0.8i F1与F2可以在5个实验数据集上运行,F3不 0.6 能运行在数据流集上,即只能在M4和M5上运行, F 因此可以把M1、M2、M3与M4、M5分别进行比较。 SSL-MKL 由于算法F3无法直接处理M4和M5这样大规 0.2 模的数据集,只能采用随机抽样的方法,限制训练集 的大小才可以使用批处理算法。本组实验对训练数 M M 据集进行无回放抽样,抽样规模为10000。其余2 数据集 个算法也在此抽样数据集上进行性能测试,对本文 图3M4和M5的实验结果(完整数据集) 的SSL-MKL算法,从测试数据集中抽取同样规模的 Fig.3 Evaluation results of M4 and M5(full data set size) 数据集作为算法的无标记数据。考虑到抽样的随机 从图3中可看出,由于有完整的训练集,各个算 性,对批处理核学习进行10次抽样训练并记录10 法的正确率相比图2有所提升。SSL-MKL算法相 次的分类正确率的平均值。图2展示了在M4和 比F1和F2的提升幅度比限制规模数据集时更大, M5上的实验结果。 表明数据依赖核对于数据分布的估计能够提升核函 0.8f 数的性能。 最后给出数据流集(M1、M2、M3)的测试结果。 0.6 F 测试过程是把训练样本按其顺序号依次输入学习模 解 ■F2 0.4 ■F 型进行训练:在接受测试样本时,SSL-MKL同时进 ■SSL-MKL 行无监督学习,而1和F2,则仅输出测试结果。由 0.2 于数据集有顺序,截取前面的30%作为训练集,后 面70%作为测试集。表4给出了实验中各算法在数 M M 数据集 据集上正确率的比较。 图2M4和M5的实验结果(限制数据集规模) 表4各算法在流数据集上正确率的比较 Fig.2 The main framework of online multiple kernel Table 4 Accuracy comparison on stream data sets learning M1 M2 M3 从图2中可以看到,SSL-MKL不比F3差太多, F1 0.731 0.788 0.775 但比F1和F2好,表明SSL-MKL对于规模受限制的 F2 0.742 0.781 0.770 数据集的性能较有监督的在线核学习算法(F1和 SSL-MKL 0.768 0.796 0.802 F2)好,归功于SSL-MKL算法中的无监督学习对最 终学习器性能提升的贡献,说明整个半监督学习框 从表4中可知SSL-MKL算法在3个数据集上 架的有效性。另一方面,注意到3个在线算法的性 都有最好的表现。第2组实验分析本文算法对不同 能均不如批处理算法F3,这是可以理解的,因为在 规模数据集处理的CPU运算时间增长与数据集大 线学习算法每次仅能“看到”当前的训练样本,且基 小之间的关系。为了精确控制实验数据集的规模, 本上不存储(SSL-MKL算法中的工作集仅是有限度 本组实验使用了20种规模依次等距递增的M1数 存储),批处理方法在整个训练期间能访问所有的 据集(以10为递增单位),记录了F2和SSL-MKL表 3 实验对比算法的基本信息 Table 3 Details of evaluation methods for comparison 编号 参考文献 数据集 描述 F1 [17] 全部 采用感知器与 Hedge 算 法融合的在线核学习算 法,优化过程采用随机 梯度下降法 F2 [9] 全部 在线多核学习算法,其 基本原理同算法 1,但 权重更新策略不同 F3 [18] M4、M5 批处理多核学习算法 F1 与 F2 可以在 5 个实验数据集上运行,F3 不 能运行在数据流集上,即只能在 M4 和 M5 上运行, 因此可以把 M1、M2、M3 与 M4、M5 分别进行比较。 由于算法 F3 无法直接处理 M4 和 M5 这样大规 模的数据集,只能采用随机抽样的方法,限制训练集 的大小才可以使用批处理算法。 本组实验对训练数 据集进行无回放抽样,抽样规模为 10000。 其余 2 个算法也在此抽样数据集上进行性能测试,对本文 的 SSL⁃MKL 算法,从测试数据集中抽取同样规模的 数据集作为算法的无标记数据。 考虑到抽样的随机 性,对批处理核学习进行 10 次抽样训练并记录 10 次的分类正确率的平均值。 图 2 展示了在 M4 和 M5 上的实验结果。 图 2 M4 和 M5 的实验结果(限制数据集规模) Fig.2 The main framework of online multiple kernel learning 从图 2 中可以看到,SSL⁃MKL 不比 F3 差太多, 但比 F1 和 F2 好,表明 SSL⁃MKL 对于规模受限制的 数据集的性能较有监督的在线核学习算法( F1 和 F2)好,归功于 SSL⁃MKL 算法中的无监督学习对最 终学习器性能提升的贡献,说明整个半监督学习框 架的有效性。 另一方面,注意到 3 个在线算法的性 能均不如批处理算法 F3,这是可以理解的,因为在 线学习算法每次仅能“看到”当前的训练样本,且基 本上不存储(SSL⁃MKL 算法中的工作集仅是有限度 存储),批处理方法在整个训练期间能访问所有的 训练数据。 因此可以接受在线学习方法性能稍差于 批处理方法。 但批处理方法难以处理大规模的数据 集,正如本组实验的第 2 部分即将展示的(图 3),这 正是在线学习方法的优势[20⁃21] 。 下面给出 F1、F2 与 SSL⁃MKL 在 M4 和 M5 整个数据集上的结果。 训 练集与测试集的规模按原数据集大小的 3:7,对于 SSL⁃MKL 采用转导学习的方式[22⁃23] ,即把整个测试 集作为无标记集。 同样对数据集进行 10 次随机划 分,记录每次分类正确率并计算方差,图 3 给出了在 数据集 M4 和 M5 上算法正确率的比较结果。 图 3 M4 和 M5 的实验结果(完整数据集) Fig.3 Evaluation results of M4 and M5 (full data set size) 从图 3 中可看出,由于有完整的训练集,各个算 法的正确率相比图 2 有所提升。 SSL⁃MKL 算法相 比 F1 和 F2 的提升幅度比限制规模数据集时更大, 表明数据依赖核对于数据分布的估计能够提升核函 数的性能。 最后给出数据流集(M1、M2、M3)的测试结果。 测试过程是把训练样本按其顺序号依次输入学习模 型进行训练;在接受测试样本时,SSL⁃MKL 同时进 行无监督学习,而 F1 和 F2,则仅输出测试结果。 由 于数据集有顺序,截取前面的 30%作为训练集,后 面 70%作为测试集。 表 4 给出了实验中各算法在数 据集上正确率的比较。 表 4 各算法在流数据集上正确率的比较 Table 4 Accuracy comparison on stream data sets M1 M2 M3 F1 0.731 0.788 0.775 F2 0.742 0.781 0.770 SSL⁃MKL 0.768 0.796 0.802 从表 4 中可知 SSL⁃MKL 算法在 3 个数据集上 都有最好的表现。 第 2 组实验分析本文算法对不同 规模数据集处理的 CPU 运算时间增长与数据集大 小之间的关系。 为了精确控制实验数据集的规模, 本组实验使用了 20 种规模依次等距递增的 M1 数 据集(以 10 6 为递增单位),记录了 F2 和 SSL⁃MKL 第 3 期 张钢,等:面向大数据流的半监督在线多核学习算法 ·361·