正在加载图片...
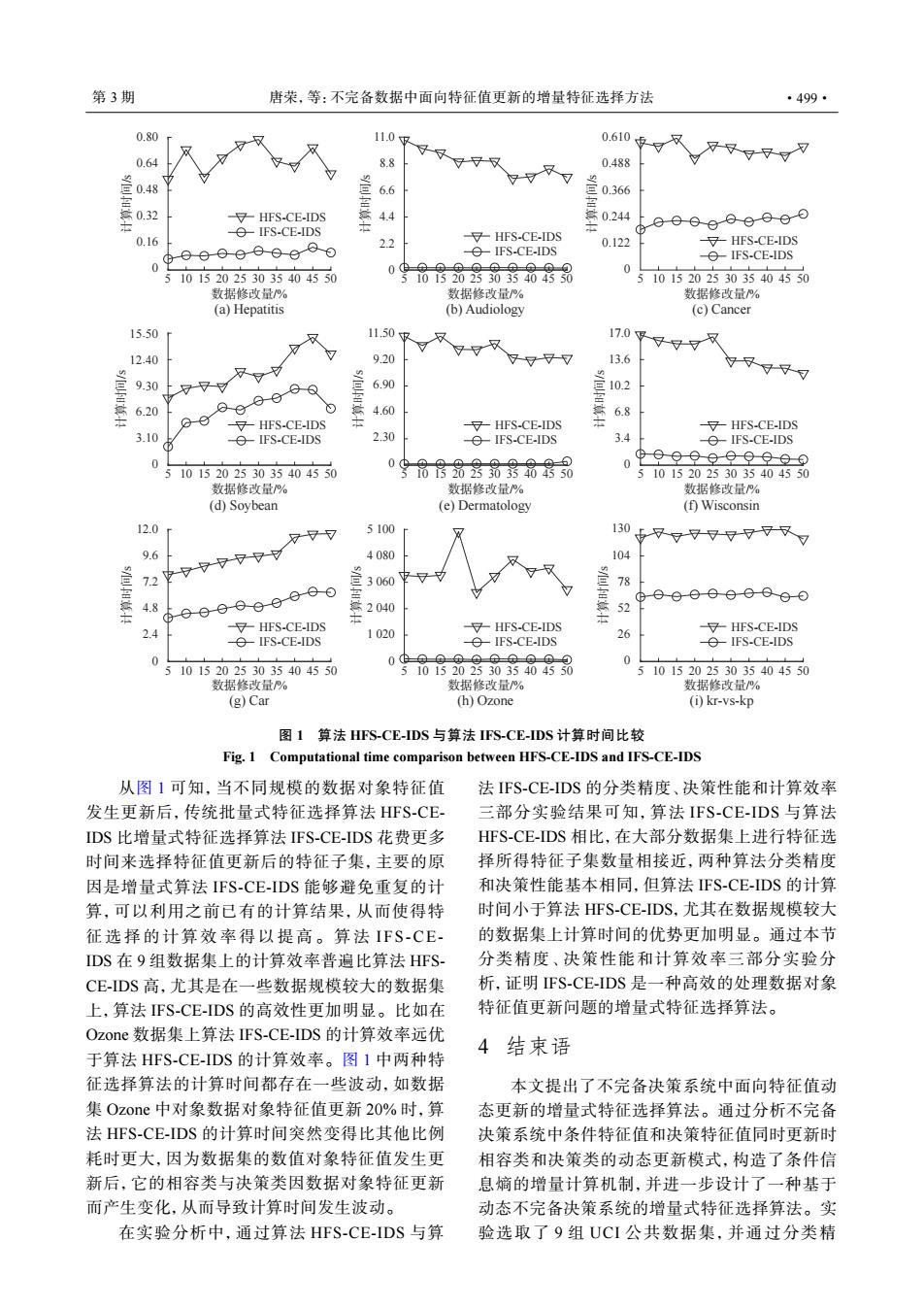
第3期 唐荣,等:不完备数据中面向特征值更新的增量特征选择方法 ·499· 0.80 110 0.610F 0.64 88 0.488 048 6.6 量0366 -HFS-CE-IDS 4.4 -eIFS-CE-IDS 0.16 22 HFS-CE-IDS 0.122 ∀-HFS-CE-IDS eIFS-CE-IDS -e-IFS-CE-IDS 0 0 5101520253035404550 5101520253035404550 5101520253035404550 数据修改量/% 数据修改量% 数据修改量% (a)Hepatitis (b)Audiology (c)Cancer 15.50r 11.50g 17.0g 12.40 9.20 又∀∀∀ 13.6 9.30 行 6.90 10.2 6.20 4.60 001 6.8 HFS-CE-IDS HFS-CE-IDS -∀HFS-CE-IDS 3.10 IFS-CE-IDS 2.30 -eIFS-CE-IDS 3.4 -eIFS-CE-IDS 0 5101520253035404550 09吊骨分号品品品书司 0 0009-9999-⊙0 5101520253035404550 数据修改量/% 数据修改量% 数据修改量% (d)Soybean (e)Dermatology (f)Wisconsin 12.0 5100 人 130 9.6 4080 104 7.2 3060 78 b6-00000006 4.8 2.4 ∀-HFS-CEDS 1020 ∀-HFS-CE-IDS HFS-CE-IDS -eIFS-CE-IDS eIFS-CE-IDS 26 eIFS-CE-IDS 0 0 5101520253035404550 5101520253035404550 101520253035404550 数据修改量% 数据修改量/% 数据修改量/% (g)Car (h)Ozone (0)kr-vs-kp 图1算法HFS-CE-IDS与算法FS-CE-IDS计算时间比较 Fig.1 Computational time comparison between HFS-CE-IDS and IFS-CE-IDS 从图1可知,当不同规模的数据对象特征值 法IFS-CE-IDS的分类精度、决策性能和计算效率 发生更新后,传统批量式特征选择算法HFS-CE- 三部分实验结果可知,算法IFS-CE-IDS与算法 IDS比增量式特征选择算法IFS-CE-IDS花费更多 HFS-CE-DS相比,在大部分数据集上进行特征选 时间来选择特征值更新后的特征子集,主要的原 择所得特征子集数量相接近,两种算法分类精度 因是增量式算法IFS-CE-IDS能够避免重复的计 和决策性能基本相同,但算法FS-CE-DS的计算 算,可以利用之前已有的计算结果,从而使得特 时间小于算法HFS-CE-IDS,尤其在数据规模较大 征选择的计算效率得以提高。算法IFS-CE- 的数据集上计算时间的优势更加明显。通过本节 IDS在9组数据集上的计算效率普遍比算法HFS- 分类精度、决策性能和计算效率三部分实验分 CE-DS高,尤其是在一些数据规模较大的数据集 析,证明FS-CE-IDS是一种高效的处理数据对象 上,算法FS-CE-DS的高效性更加明显。比如在 特征值更新问题的增量式特征选择算法。 Ozone数据集上算法IFS-CE-IDS的计算效率远优 4结束语 于算法HFS-CE-IDS的计算效率。图1中两种特 征选择算法的计算时间都存在一些波动,如数据 本文提出了不完备决策系统中面向特征值动 集Ozone中对象数据对象特征值更新20%时,算 态更新的增量式特征选择算法。通过分析不完备 法HFS-CE-IDS的计算时间突然变得比其他比例 决策系统中条件特征值和决策特征值同时更新时 耗时更大,因为数据集的数值对象特征值发生更 相容类和决策类的动态更新模式,构造了条件信 新后,它的相容类与决策类因数据对象特征更新 息嫡的增量计算机制,并进一步设计了一种基于 而产生变化,从而导致计算时间发生波动。 动态不完备决策系统的增量式特征选择算法。实 在实验分析中,通过算法HFS-CE-IDS与算 验选取了9组UCI公共数据集,并通过分类精5 10 15 20 25 30 35 40 45 50 0 0.16 0.32 0.48 0.64 0.80 0 2.2 4.4 6.6 8.8 11.0 0 0.122 0.244 0.366 0.488 0.610 0 3.10 6.20 9.30 12.40 15.50 0 2.30 4.60 6.90 9.20 11.50 HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS HFS-CE-IDS IFS-CE-IDS (f) Wisconsin 0 3.4 6.8 10.2 13.6 17.0 (g) Car 0 2.4 4.8 7.2 9.6 12.0 (h) Ozone 0 1 020 2 040 3 060 4 080 5 100 (i) kr-vs-kp 0 26 52 78 104 130 计算时间/s 计算时间/s 计算时间/s 计算时间/s 计算时间/s 计算时间/s 计算时间/s 计算时间/s 计算时间/s 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% 5 10 15 20 25 30 35 40 45 50 数据修改量/% (a) Hepatitis (b) Audiology (c) Cancer (d) Soybean (e) Dermatology 图 1 算法 HFS-CE-IDS 与算法 IFS-CE-IDS 计算时间比较 Fig. 1 Computational time comparison between HFS-CE-IDS and IFS-CE-IDS 从图 1 可知,当不同规模的数据对象特征值 发生更新后,传统批量式特征选择算法 HFS-CEIDS 比增量式特征选择算法 IFS-CE-IDS 花费更多 时间来选择特征值更新后的特征子集,主要的原 因是增量式算法 IFS-CE-IDS 能够避免重复的计 算,可以利用之前已有的计算结果,从而使得特 征选择的计算效率得以提高。算 法 IFS-CEIDS 在 9 组数据集上的计算效率普遍比算法 HFSCE-IDS 高,尤其是在一些数据规模较大的数据集 上,算法 IFS-CE-IDS 的高效性更加明显。比如在 Ozone 数据集上算法 IFS-CE-IDS 的计算效率远优 于算法 HFS-CE-IDS 的计算效率。图 1 中两种特 征选择算法的计算时间都存在一些波动,如数据 集 Ozone 中对象数据对象特征值更新 20% 时,算 法 HFS-CE-IDS 的计算时间突然变得比其他比例 耗时更大,因为数据集的数值对象特征值发生更 新后,它的相容类与决策类因数据对象特征更新 而产生变化,从而导致计算时间发生波动。 在实验分析中,通过算法 HFS-CE-IDS 与算 法 IFS-CE-IDS 的分类精度、决策性能和计算效率 三部分实验结果可知,算法 IFS-CE-IDS 与算法 HFS-CE-IDS 相比,在大部分数据集上进行特征选 择所得特征子集数量相接近,两种算法分类精度 和决策性能基本相同,但算法 IFS-CE-IDS 的计算 时间小于算法 HFS-CE-IDS,尤其在数据规模较大 的数据集上计算时间的优势更加明显。通过本节 分类精度、决策性能和计算效率三部分实验分 析,证明 IFS-CE-IDS 是一种高效的处理数据对象 特征值更新问题的增量式特征选择算法。 4 结束语 本文提出了不完备决策系统中面向特征值动 态更新的增量式特征选择算法。通过分析不完备 决策系统中条件特征值和决策特征值同时更新时 相容类和决策类的动态更新模式,构造了条件信 息熵的增量计算机制,并进一步设计了一种基于 动态不完备决策系统的增量式特征选择算法。实 验选取了 9 组 UCI 公共数据集,并通过分类精 第 3 期 唐荣,等:不完备数据中面向特征值更新的增量特征选择方法 ·499·