正在加载图片...
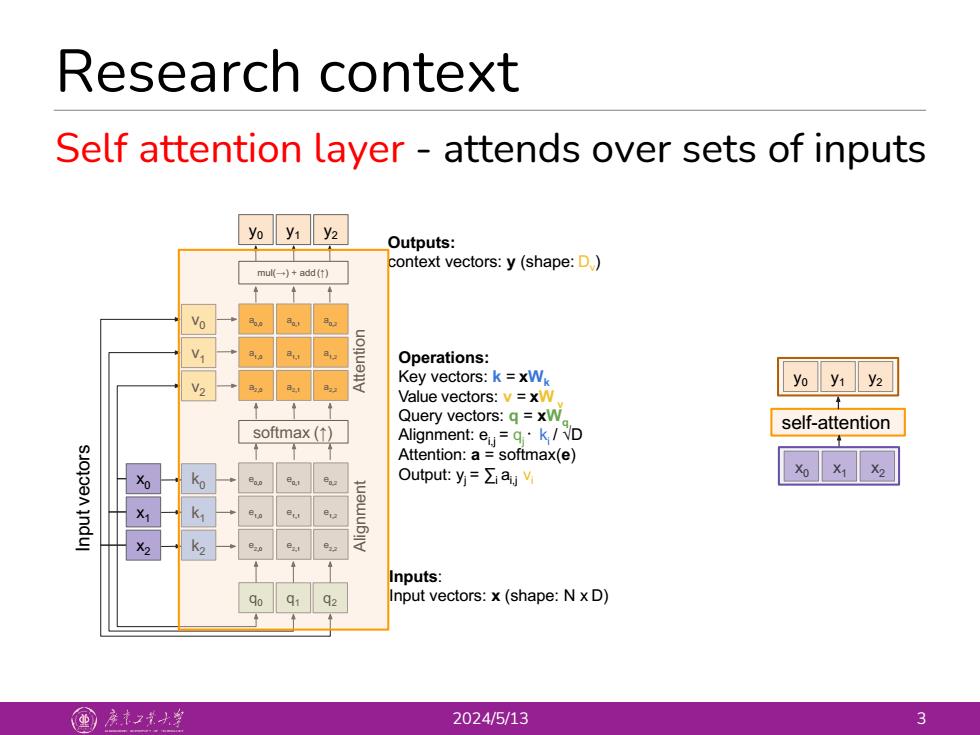
Research context Self attention layer-attends over sets of inputs yo y1 y2 Outputs: context vectors:y(shape:D) mu一)+add(t) Vo Operations: V2 Key vectors:k =xW yo y1 y2 Value vectors:v=xW Query vectors:q=xW self-attention softmax(↑) Alignment:e=g·k/D Attention:a softmax(e) sJojoen indul Ko Output::y=∑a, K> Inputs: Input vectors:x(shape:N x D) 国产之大丝 2024/5/13 3 Research context 2024/5/13 3 mul(→) + add (↑) Self attention layer - attends over sets of inputs Alignment q0 Attention Inputs: Input vectors: x (shape: N x D) softmax (↑) y1 Outputs: context vectors: y (shape: Dv) Operations: Key vectors: k = xWk Value vectors: v = xW v Query vectors: q = xWq Alignment: ei,j = qj ᐧ ki / √D Attention: a = softmax(e) Output: yj = ∑i ai,j vi x2 x1 x0 e2,0 e1,0 e0,0 a2,0 a1,0 a0,0 e2,1 e1,1 e0,1 e2,2 e1,2 e0,2 a2,1 a1,1 a0,1 a2,2 a1,2 a0,2 q1 q2 y0 y2 Input vectors k2 k1 k0 v2 v1 v0 self-attention x0 x1 x2 y0 y1 y2