正在加载图片...
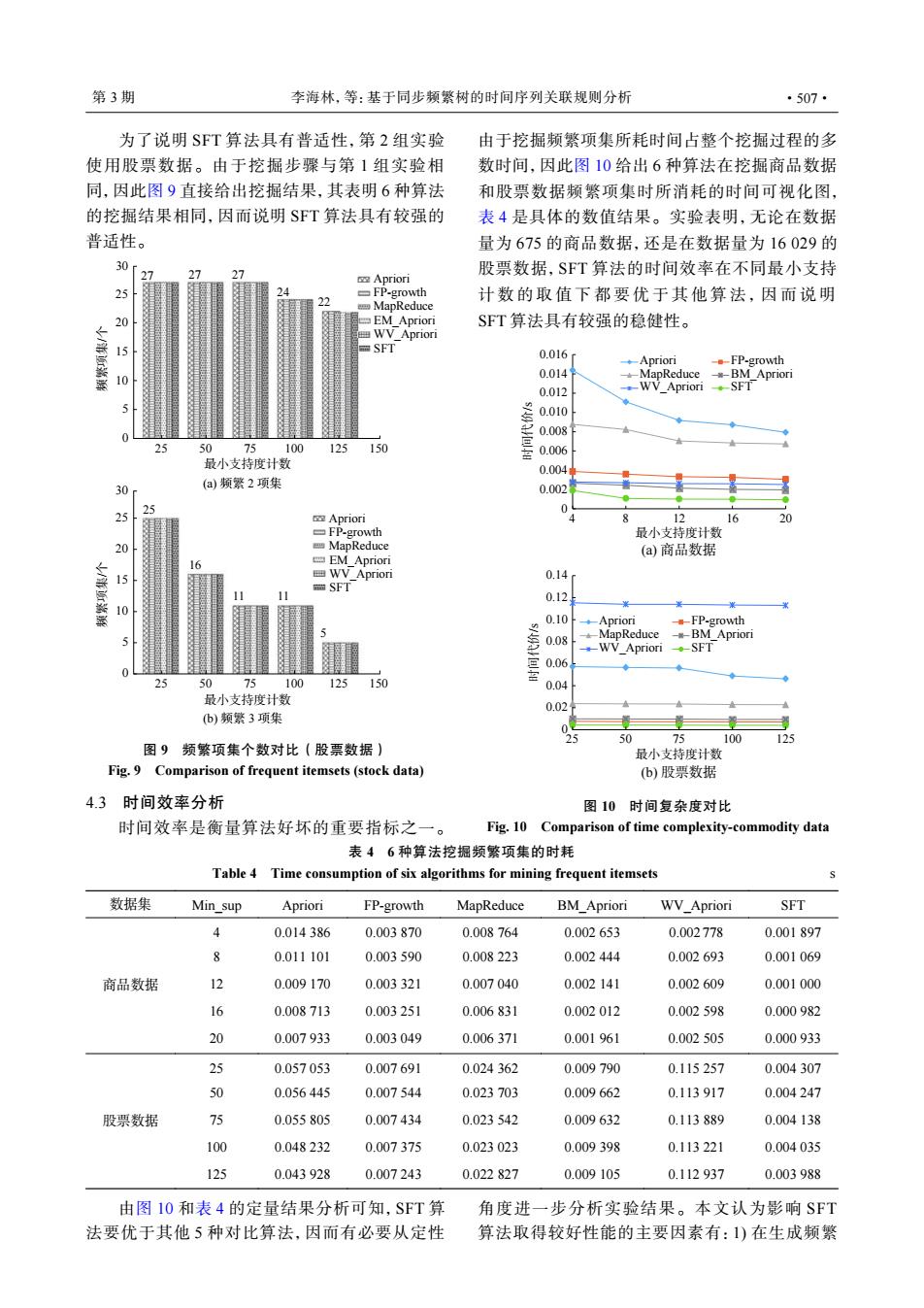
第3期 李海林,等:基于同步频繁树的时间序列关联规则分析 ·507· 为了说明SFT算法具有普适性,第2组实验 由于挖掘频繁项集所耗时间占整个挖掘过程的多 使用股票数据。由于挖掘步骤与第1组实验相 数时间,因此图10给出6种算法在挖掘商品数据 同,因此图9直接给出挖掘结果,其表明6种算法 和股票数据频繁项集时所消耗的时间可视化图, 的挖掘结果相同,因而说明SFT算法具有较强的 表4是具体的数值结果。实验表明,无论在数据 普适性。 量为675的商品数据,还是在数据量为16029的 30 7 股票数据,SFT算法的时间效率在不同最小支持 Apriori FP-growth 计数的取值下都要优于其他算法,因而说明 MapReduce EM Apriori SFT算法具有较强的稳健性。 WV Apriori 15 SFT 0.016 ◆Apriori 。FP-growth 10 0.014 M apReduce *-BM Apriori 0.012 0.010 0.008 50 75 100 125 150 0.006 最小支持度计数 0.004 30 (a)频繁2项集 0.002 Apriori 12 16 FP-growth 最小支持度计数 20 MapReduce (a)商品数据 16 EM Apriori WV Apriori 0.14 SFT 0.12 0.10 ◆-ADr10r1 -FP-growth 0.08 MapReduce BM Apriori WV Apriori ◆SFT 0.06 25 0 75 100 125 ◆ 150 0.04 最小支持度计数 0.02 (b)频繁3项集 25 50 100 125 图9频繁项集个数对比(股票数据) 最小支持度计数 Fig.9 Comparison of frequent itemsets(stock data) (b)股票数据 4.3时间效率分析 图10时间复杂度对比 时间效率是衡量算法好坏的重要指标之一。 Fig.10 Comparison of time complexity-commodity data 表46种算法挖掘频繁项集的时耗 Table 4 Time consumption of six algorithms for mining frequent itemsets 数据集 Min sup Apriori FP-growth MapReduce BM_Apriori WV_Apriori SFT 0.014386 0.003870 0.008764 0.002653 0.002778 0.001897 8 0.011101 0.003590 0.008223 0.002444 0.002693 0.001069 商品数据 12 0.009170 0.003321 0.007040 0.002141 0.002609 0.001000 16 0.008713 0.003251 0.006831 0.002012 0.002598 0.000982 20 0.007933 0.003049 0.006371 0.001961 0.002505 0.000933 25 0.057053 0.007691 0.024362 0.009790 0.115257 0.004307 50 0.056445 0.007544 0.023703 0.009662 0.113917 0.004247 股票数据 75 0.055805 0.007434 0.023542 0.009632 0.113889 0.004138 100 0.048232 0.007375 0.023023 0.009398 0.113221 0.004035 125 0.043928 0.007243 0.022827 0.009105 0.112937 0.003988 由图10和表4的定量结果分析可知,SFT算 角度进一步分析实验结果。本文认为影响SFT 法要优于其他5种对比算法,因而有必要从定性 算法取得较好性能的主要因素有:1)在生成频繁为了说明 SFT 算法具有普适性,第 2 组实验 使用股票数据。由于挖掘步骤与第 1 组实验相 同,因此图 9 直接给出挖掘结果,其表明 6 种算法 的挖掘结果相同,因而说明 SFT 算法具有较强的 普适性。 25 30 20 15 10 5 0 25 50 75 100 125 最小支持度计数 频繁项集/个 27 27 27 24 22 (a) 频繁 2 项集 25 30 20 15 10 5 0 25 50 75 100 125 150 150 最小支持度计数 频繁项集/个 25 16 11 11 5 (b) 频繁 3 项集 Apriori FP-growth MapReduce EM_Apriori WV_Apriori SFT Apriori FP-growth MapReduce EM_Apriori WV_Apriori SFT 图 9 频繁项集个数对比(股票数据) Fig. 9 Comparison of frequent itemsets (stock data) 4.3 时间效率分析 时间效率是衡量算法好坏的重要指标之一。 由于挖掘频繁项集所耗时间占整个挖掘过程的多 数时间,因此图 10 给出 6 种算法在挖掘商品数据 和股票数据频繁项集时所消耗的时间可视化图, 表 4 是具体的数值结果。实验表明,无论在数据 量为 675 的商品数据,还是在数据量为 16 029 的 股票数据,SFT 算法的时间效率在不同最小支持 计数的取值下都要优于其他算法,因而说 明 SFT 算法具有较强的稳健性。 0.014 0.016 0.012 0.010 0.008 0.006 0.004 0.002 0 4 8 12 16 20 最小支持度计数 时间代价/s (a) 商品数据 0.14 0.12 0.10 0.08 0.06 0.04 0.02 0 25 50 75 100 125 最小支持度计数 时间代价/s (b) 股票数据 Apriori FP-growth MapReduce BM_Apriori WV_Apriori SFT Apriori FP-growth MapReduce BM_Apriori WV_Apriori SFT 图 10 时间复杂度对比 Fig. 10 Comparison of time complexity-commodity data 表 4 6 种算法挖掘频繁项集的时耗 Table 4 Time consumption of six algorithms for mining frequent itemsets s 数据集 Min_sup Apriori FP-growth MapReduce BM_Apriori WV_Apriori SFT 商品数据 4 0.014 386 0.003 870 0.008 764 0.002 653 0.002778 0.001 897 8 0.011 101 0.003 590 0.008 223 0.002 444 0.002 693 0.001 069 12 0.009 170 0.003 321 0.007 040 0.002 141 0.002 609 0.001 000 16 0.008 713 0.003 251 0.006 831 0.002 012 0.002 598 0.000 982 20 0.007 933 0.003 049 0.006 371 0.001 961 0.002 505 0.000 933 股票数据 25 0.057 053 0.007 691 0.024 362 0.009 790 0.115 257 0.004 307 50 0.056 445 0.007 544 0.023 703 0.009 662 0.113 917 0.004 247 75 0.055 805 0.007 434 0.023 542 0.009 632 0.113 889 0.004 138 100 0.048 232 0.007 375 0.023 023 0.009 398 0.113 221 0.004 035 125 0.043 928 0.007 243 0.022 827 0.009 105 0.112 937 0.003 988 由图 10 和表 4 的定量结果分析可知,SFT 算 法要优于其他 5 种对比算法,因而有必要从定性 角度进一步分析实验结果。本文认为影响 SFT 算法取得较好性能的主要因素有:1) 在生成频繁 第 3 期 李海林,等:基于同步频繁树的时间序列关联规则分析 ·507·