正在加载图片...
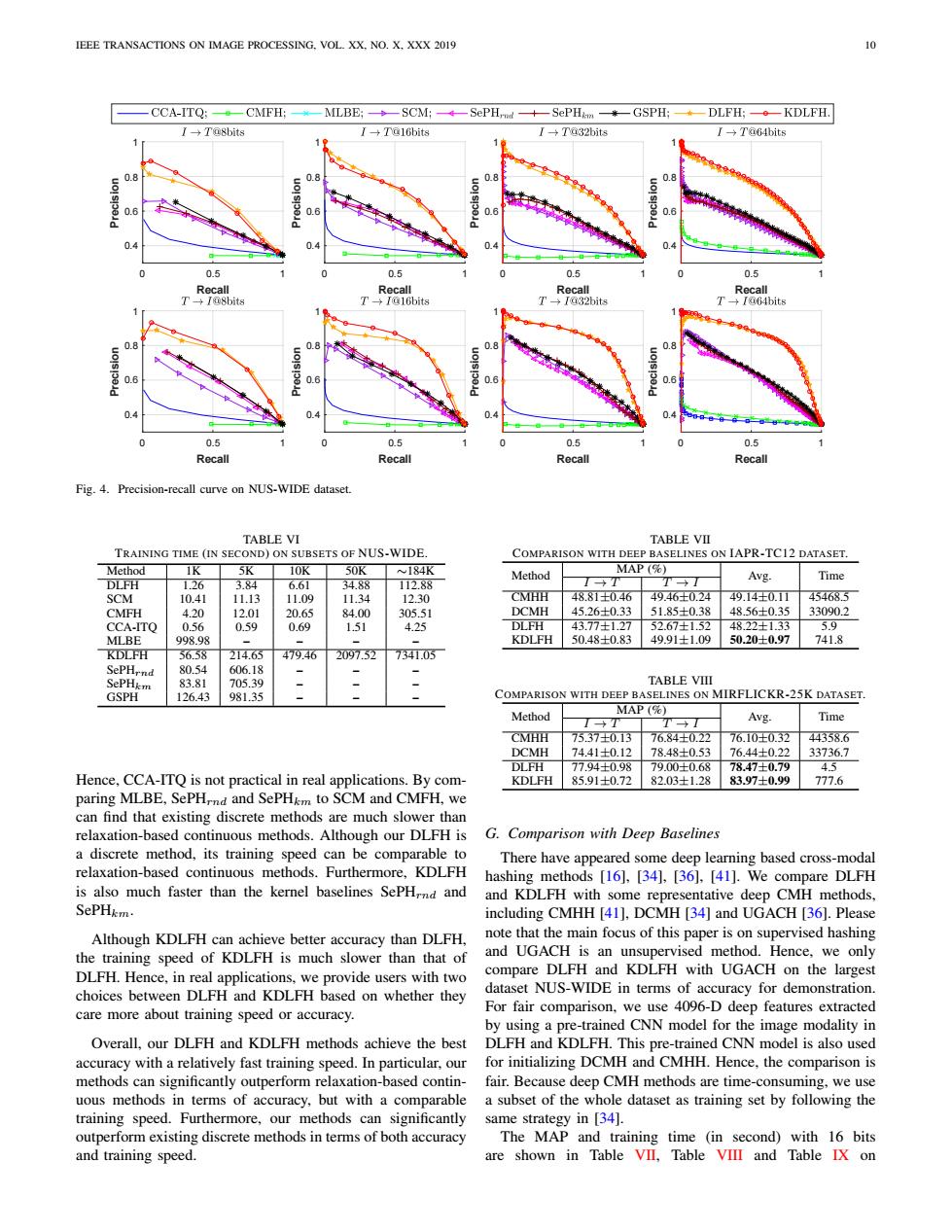
EEE TRANSACTIONS ON IMAGE PROCESSING.VOL.XX,NO.X.XXX 2019 10 CCA-ITQ:一CMFH:-MLBE;-SCM;4—SePHrnd+—SePHimn*GSPH;◆-DLFH;。-KDLFH →T@8bits →T@16bits ÷T@32bits I→Ta64bits 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.4 0.4 0.5 0.5 0.5 0.5 Recall Recall Recal Recall →I@8bits →Ia64bits 0.8 0.8 0.8 0.6 0.6 0.6 0.5 0.5 0.5 0.5 Recall Recall Recal Recall Fig.4.Precision-recall curve on NUS-WIDE dataset. TABLE VI TABLE VII TRAINING TIME (IN SECOND)ON SUBSETS OF NUS-WIDE. COMPARISON WITH DEEP BASELINES ON IAPR-TC12 DATASET. Method 1K 5K 10K 50K 184K MAP ( Method Avg. Time DLFH 1.26 3.84 6.61 34.88 112.88 →T SCM 10.41 11.13 11.09 11.34 12.30 CMHH 48.81士0.46 49.46士0.24 49.14士0.11 45468.5 CMFH 4.20 12.01 20.65 84.00 305.51 DCMH 45.26士0.33 51.85士0.38 48.56±0.35 33090.2 CCA-ITO 0.56 0.59 0.69 1.51 4.25 DLFH 43.77±1.27 52.67±1.52 48.22±1.33 5.9 MLBE 998.98 一 KDLFH 50.48士0.83 49.91±1.09 50.20±0.97 741.8 KDLFH 56.58 214.65 479.46 2097.52 7341.05 SePHrnd 80.54 606.18 SePHkm 83.81 705.39 TABLE VIII GSPH 126.43 981.35 COMPARISON WITH DEEP BASELINES ON MIRFLICKR-25K DATASET. Method MAP (% Avg. Time → → CMHH 7537士0.1 76.84土0.22 76.10士0.32 44358.6 DCMH 74.41±0.12 78.48±0.53 76.44士0.22 33736.7 DLFH 77.94±0.98 79.00±0.68 78.47±0.79 45 Hence,CCA-ITQ is not practical in real applications.By com- KDLFH 85.91±0.72 82.03±1.28 8397士0.99 777.6 paring MLBE,SePHrnd and SePHkm to SCM and CMFH,we can find that existing discrete methods are much slower than relaxation-based continuous methods.Although our DLFH is G. Comparison with Deep Baselines a discrete method,its training speed can be comparable to There have appeared some deep learning based cross-modal relaxation-based continuous methods.Furthermore,KDLFH hashing methods [16],[34],[36],[41].We compare DLFH is also much faster than the kernel baselines SePHrnd and and KDLFH with some representative deep CMH methods, SePHkm. including CMHH [41],DCMH [34]and UGACH [36].Please Although KDLFH can achieve better accuracy than DLFH, note that the main focus of this paper is on supervised hashing the training speed of KDLFH is much slower than that of and UGACH is an unsupervised method.Hence,we only DLFH.Hence,in real applications,we provide users with two compare DLFH and KDLFH with UGACH on the largest choices between DLFH and KDLFH based on whether they dataset NUS-WIDE in terms of accuracy for demonstration. care more about training speed or accuracy. For fair comparison,we use 4096-D deep features extracted by using a pre-trained CNN model for the image modality in Overall.our DLFH and KDLFH methods achieve the best DLFH and KDLFH.This pre-trained CNN model is also used accuracy with a relatively fast training speed.In particular,our for initializing DCMH and CMHH.Hence,the comparison is methods can significantly outperform relaxation-based contin- fair.Because deep CMH methods are time-consuming,we use uous methods in terms of accuracy,but with a comparable a subset of the whole dataset as training set by following the training speed.Furthermore,our methods can significantly same strategy in [34]. outperform existing discrete methods in terms of both accuracy The MAP and training time (in second)with 16 bits and training speed. are shown in Table VII,Table VIII and Table IX onIEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. XX, NO. X, XXX 2019 10 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Recall 0 0.5 1 Pre cisio n 0.4 0.6 0.8 1 Fig. 4. Precision-recall curve on NUS-WIDE dataset. TABLE VI TRAINING TIME (IN SECOND) ON SUBSETS OF NUS-WIDE. Method 1K 5K 10K 50K ∼184K DLFH 1.26 3.84 6.61 34.88 112.88 SCM 10.41 11.13 11.09 11.34 12.30 CMFH 4.20 12.01 20.65 84.00 305.51 CCA-ITQ 0.56 0.59 0.69 1.51 4.25 MLBE 998.98 – – – – KDLFH 56.58 214.65 479.46 2097.52 7341.05 SePHrnd 80.54 606.18 – – – SePHkm 83.81 705.39 – – – GSPH 126.43 981.35 – – – Hence, CCA-ITQ is not practical in real applications. By comparing MLBE, SePHrnd and SePHkm to SCM and CMFH, we can find that existing discrete methods are much slower than relaxation-based continuous methods. Although our DLFH is a discrete method, its training speed can be comparable to relaxation-based continuous methods. Furthermore, KDLFH is also much faster than the kernel baselines SePHrnd and SePHkm. Although KDLFH can achieve better accuracy than DLFH, the training speed of KDLFH is much slower than that of DLFH. Hence, in real applications, we provide users with two choices between DLFH and KDLFH based on whether they care more about training speed or accuracy. Overall, our DLFH and KDLFH methods achieve the best accuracy with a relatively fast training speed. In particular, our methods can significantly outperform relaxation-based continuous methods in terms of accuracy, but with a comparable training speed. Furthermore, our methods can significantly outperform existing discrete methods in terms of both accuracy and training speed. TABLE VII COMPARISON WITH DEEP BASELINES ON IAPR-TC12 DATASET. Method MAP (%) Avg. Time I → T T → I CMHH 48.81±0.46 49.46±0.24 49.14±0.11 45468.5 DCMH 45.26±0.33 51.85±0.38 48.56±0.35 33090.2 DLFH 43.77±1.27 52.67±1.52 48.22±1.33 5.9 KDLFH 50.48±0.83 49.91±1.09 50.20±0.97 741.8 TABLE VIII COMPARISON WITH DEEP BASELINES ON MIRFLICKR-25K DATASET. Method MAP (%) Avg. Time I → T T → I CMHH 75.37±0.13 76.84±0.22 76.10±0.32 44358.6 DCMH 74.41±0.12 78.48±0.53 76.44±0.22 33736.7 DLFH 77.94±0.98 79.00±0.68 78.47±0.79 4.5 KDLFH 85.91±0.72 82.03±1.28 83.97±0.99 777.6 G. Comparison with Deep Baselines There have appeared some deep learning based cross-modal hashing methods [16], [34], [36], [41]. We compare DLFH and KDLFH with some representative deep CMH methods, including CMHH [41], DCMH [34] and UGACH [36]. Please note that the main focus of this paper is on supervised hashing and UGACH is an unsupervised method. Hence, we only compare DLFH and KDLFH with UGACH on the largest dataset NUS-WIDE in terms of accuracy for demonstration. For fair comparison, we use 4096-D deep features extracted by using a pre-trained CNN model for the image modality in DLFH and KDLFH. This pre-trained CNN model is also used for initializing DCMH and CMHH. Hence, the comparison is fair. Because deep CMH methods are time-consuming, we use a subset of the whole dataset as training set by following the same strategy in [34]. The MAP and training time (in second) with 16 bits are shown in Table VII, Table VIII and Table IX on