正在加载图片...
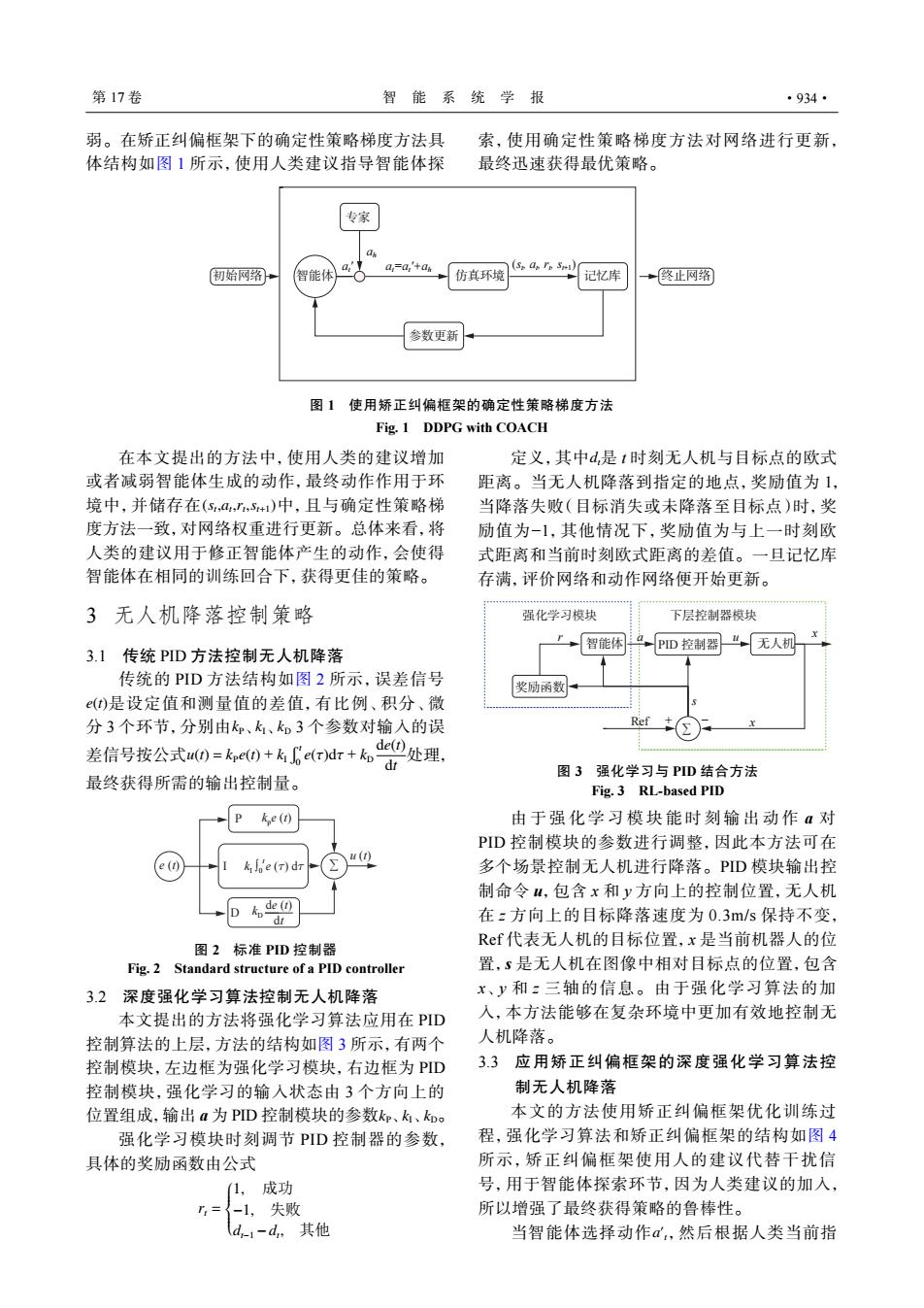
第17卷 智能系统学报 ·934· 弱。在矫正纠偏框架下的确定性策略梯度方法具 索,使用确定性策略梯度方法对网络进行更新, 体结构如图1所示,使用人类建议指导智能体探 最终迅速获得最优策略。 专家 初始网绍 智能体 a a,=a,'+a 仿其环境 记忆库 +终止网路 参数更新 图1使用矫正纠偏框架的确定性策略梯度方法 Fig.1 DDPG with COACH 在本文提出的方法中,使用人类的建议增加 定义,其中d,是1时刻无人机与目标点的欧式 或者减弱智能体生成的动作,最终动作作用于环 距离。当无人机降落到指定的地点,奖励值为1, 境中,并储存在(S,a,,+)中,且与确定性策略梯 当降落失败(目标消失或未降落至目标点)时,奖 度方法一致,对网络权重进行更新。总体来看,将 励值为-1,其他情况下,奖励值为与上一时刻欧 人类的建议用于修正智能体产生的动作,会使得 式距离和当前时刻欧式距离的差值。一旦记忆库 智能体在相同的训练回合下,获得更佳的策略。 存满,评价网络和动作网络便开始更新。 3无人机降落控制策略 强化学习模块 下层控制器模块 →智能体a,PD控制器“无人机 3.1传统PID方法控制无人机降落 传统的PID方法结构如图2所示,误差信号 奖励函数 (t)是设定值和测量值的差值,有比例、积分、微 分3个环节,分别由k、k、k如3个参数对输人的误 de①处理, 差信号按公式u)=kpe0+6e(rdr+k, 最终获得所需的输出控制量。 图3强化学习与PID结合方法 Fig.3 RL-based PID ke(r) 由于强化学习模块能时刻输出动作a对 PD控制模块的参数进行调整,因此本方法可在 () e(1) ke (T)dr 多个场景控制无人机进行降落。PD模块输出控 制命令4,包含x和y方向上的控制位置,无人机 D6巴 在z方向上的目标降落速度为0.3m/s保持不变, Ref代表无人机的目标位置,x是当前机器人的位 图2标准PD控制器 Fig.2 Standard structure of a PID controller 置,5是无人机在图像中相对目标点的位置,包含 3.2深度强化学习算法控制无人机降落 x、y和:三轴的信息。由于强化学习算法的加 本文提出的方法将强化学习算法应用在PID 入,本方法能够在复杂环境中更加有效地控制无 控制算法的上层,方法的结构如图3所示,有两个 人机降落。 控制模块,左边框为强化学习模块,右边框为PD 3.3应用矫正纠偏框架的深度强化学习算法控 控制模块,强化学习的输入状态由3个方向上的 制无人机降落 位置组成,输出a为PID控制模块的参数k、k、k。 本文的方法使用矫正纠偏框架优化训练过 强化学习模块时刻调节PD控制器的参数, 程,强化学习算法和矫正纠偏框架的结构如图4 具体的奖励函数由公式 所示,矫正纠偏框架使用人的建议代替干扰信 (1,成功 号,用于智能体探索环节,因为人类建议的加入, =了-1,失败 所以增强了最终获得策略的鲁棒性。 d-1-d,其他 当智能体选择动作α,然后根据人类当前指弱。在矫正纠偏框架下的确定性策略梯度方法具 体结构如图 1 所示,使用人类建议指导智能体探 索,使用确定性策略梯度方法对网络进行更新, 最终迅速获得最优策略。 初始网络 智能体 终止网络 专家 仿真环境 参数更新 记忆库 at ′ at=at ′+ah (st , at , rt , st+1) ah 图 1 使用矫正纠偏框架的确定性策略梯度方法 Fig. 1 DDPG with COACH (st ,at ,rt ,st+1) 在本文提出的方法中,使用人类的建议增加 或者减弱智能体生成的动作,最终动作作用于环 境中,并储存在 中,且与确定性策略梯 度方法一致,对网络权重进行更新。总体来看,将 人类的建议用于修正智能体产生的动作,会使得 智能体在相同的训练回合下,获得更佳的策略。 3 无人机降落控制策略 3.1 传统 PID 方法控制无人机降落 e(t) kP kI kD u(t) = kPe(t) + kI r t 0 e(τ)dτ + kD de(t) dt 传统的 PID 方法结构如图 2 所示,误差信号 是设定值和测量值的差值,有比例、积分、微 分 3 个环节,分别由 、 、 3 个参数对输入的误 差信号按公式 处理, 最终获得所需的输出控制量。 e (t) u (t) de (t) dt ∑ P D kD I kpe (t) kI ∫0 t e (t) dt 图 2 标准 PID 控制器 Fig. 2 Standard structure of a PID controller 3.2 深度强化学习算法控制无人机降落 kP kI kD 本文提出的方法将强化学习算法应用在 PID 控制算法的上层,方法的结构如图 3 所示,有两个 控制模块,左边框为强化学习模块,右边框为 PID 控制模块,强化学习的输入状态由 3 个方向上的 位置组成,输出 a 为 PID 控制模块的参数 、 、 。 强化学习模块时刻调节 PID 控制器的参数, 具体的奖励函数由公式 rt = 1, 成功 −1, 失败 dt−1 −dt , 其他 定义,其中 dt是 t 时刻无人机与目标点的欧式 距离。当无人机降落到指定的地点,奖励值为 1, 当降落失败(目标消失或未降落至目标点)时,奖 励值为−1,其他情况下,奖励值为与上一时刻欧 式距离和当前时刻欧式距离的差值。一旦记忆库 存满,评价网络和动作网络便开始更新。 智能体 无人机 奖励函数 ∑ Ref + − s x x r a u 强化学习模块 下层控制器模块 PID 控制器 图 3 强化学习与 PID 结合方法 Fig. 3 RL-based PID 由于强化学习模块能时刻输出动 作 a 对 PID 控制模块的参数进行调整,因此本方法可在 多个场景控制无人机进行降落。PID 模块输出控 制命令 u,包含 x 和 y 方向上的控制位置,无人机 在 z 方向上的目标降落速度为 0.3m/s 保持不变, Ref 代表无人机的目标位置,x 是当前机器人的位 置,s 是无人机在图像中相对目标点的位置,包含 x、y 和 z 三轴的信息。由于强化学习算法的加 入,本方法能够在复杂环境中更加有效地控制无 人机降落。 3.3 应用矫正纠偏框架的深度强化学习算法控 制无人机降落 本文的方法使用矫正纠偏框架优化训练过 程,强化学习算法和矫正纠偏框架的结构如图 4 所示,矫正纠偏框架使用人的建议代替干扰信 号,用于智能体探索环节,因为人类建议的加入, 所以增强了最终获得策略的鲁棒性。 a ′ 当智能体选择动作 t,然后根据人类当前指 第 17 卷 智 能 系 统 学 报 ·934·