正在加载图片...
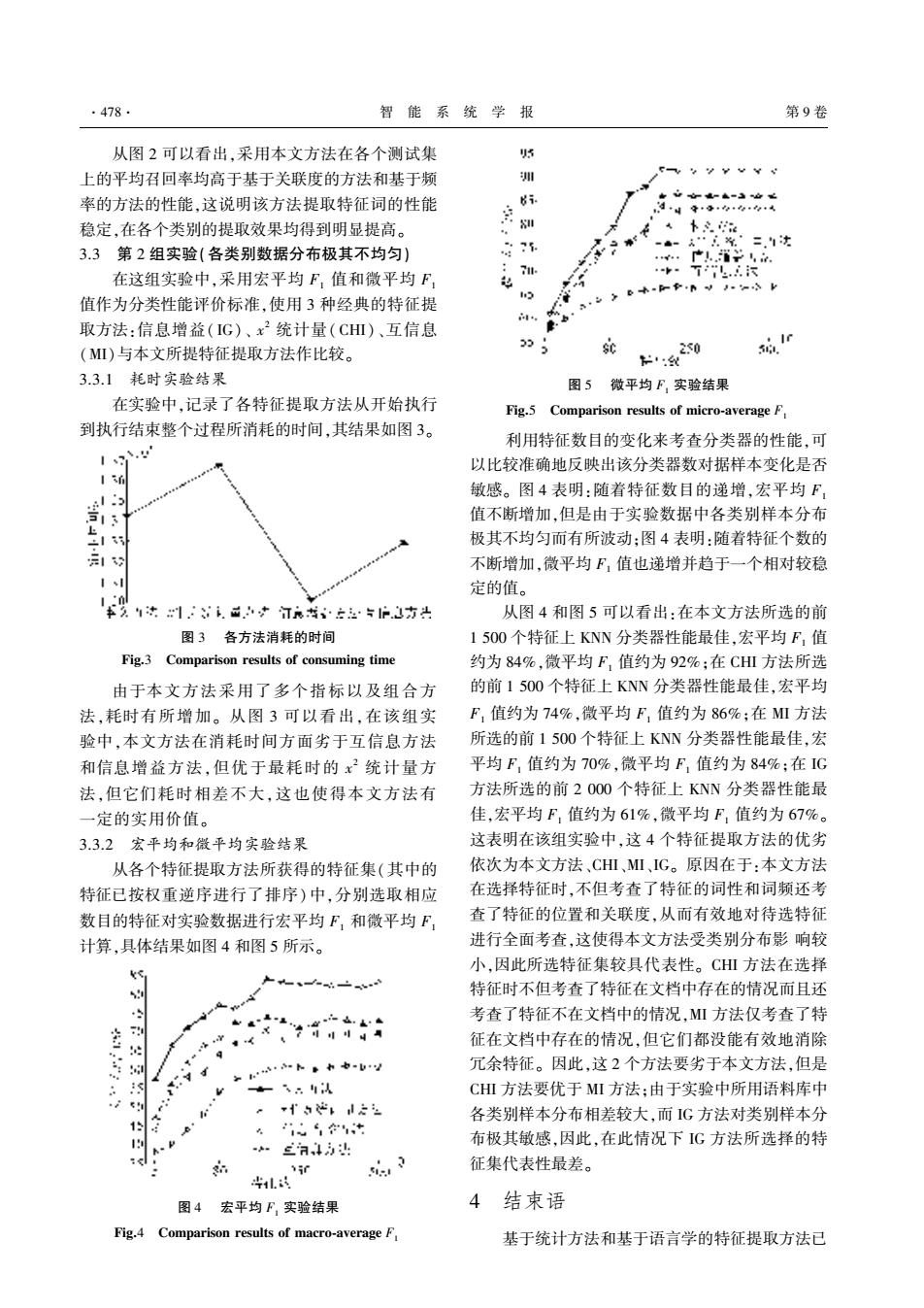
·478 智能系统学报 第9卷 从图2可以看出,采用本文方法在各个测试集 5 上的平均召回率均高于基于关联度的方法和基于频 圳 率的方法的性能,这说明该方法提取特征词的性能 8i 4年9 稳定,在各个类别的提取效果均得到明显提高。 iu 3.3第2组实验(各类别数据分布极其不均匀)》 75 --大…米·二次 e年 广学 在这组实验中,采用宏平均F,值和微平均F 7H. 值作为分类性能评价标准,使用3种经典的特征提 5 取方法:信息增益(IG)、x2统计量(CH)、互信息 6 (M)与本文所提特征提取方法作比较。 时 250 城r : 3.3.1耗时实验结果 图5微平均F,实验结果 在实验中,记录了各特征提取方法从开始执行 Fig.5 Comparison results of micro-average F 到执行结束整个过程所消耗的时间,其结果如图3。 利用特征数目的变化来考查分类器的性能,可 以比较准确地反映出该分类器数对据样本变化是否 敏感。图4表明:随着特征数目的递增,宏平均F 值不断增加,但是由于实验数据中各类别样本分布 ÷1 极其不均匀而有所波动:图4表明:随着特征个数的 不断增加,微平均F,值也递增并趋于一个相对较稳 定的值。 书之1冰1.小*汀%护心方出 从图4和图5可以看出:在本文方法所选的前 图3各方法消耗的时间 1500个特征上KNN分类器性能最佳,宏平均F,值 Fig.3 Comparison results of consuming time 约为84%,微平均F,值约为92%:在CHⅢ方法所选 由于本文方法采用了多个指标以及组合方 的前1500个特征上KNN分类器性能最佳,宏平均 法,耗时有所增加。从图3可以看出,在该组实 F,值约为74%,微平均F,值约为86%:在M方法 验中,本文方法在消耗时间方面劣于互信息方法 所选的前1500个特征上KNN分类器性能最佳,宏 和信息增益方法,但优于最耗时的x2统计量方 平均F值约为70%,微平均F,值约为84%:在1G 法,但它们耗时相差不大,这也使得本文方法有 方法所选的前2O00个特征上KNN分类器性能最 一定的实用价值。 佳,宏平均F,值约为61%,微平均F,值约为67%。 3.3.2宏平均和微平均实验结果 这表明在该组实验中,这4个特征提取方法的优劣 从各个特征提取方法所获得的特征集(其中的 依次为本文方法、CH、MI、IG。原因在于:本文方法 特征已按权重逆序进行了排序)中,分别选取相应 在选择特征时,不但考查了特征的词性和词频还考 数目的特征对实验数据进行宏平均F,和微平均F, 查了特征的位置和关联度,从而有效地对待选特征 计算,具体结果如图4和图5所示。 进行全面考查,这使得本文方法受类别分布影响较 小,因此所选特征集较具代表性。CHⅢ方法在选择 特征时不但考查了特征在文档中存在的情况而且还 考查了特征不在文档中的情况,MI方法仅考查了特 征在文档中存在的情况,但它们都没能有效地消除 a 。b以 冗余特征。因此,这2个方法要劣于本文方法,但是 CHⅢI方法要优于MI方法:由于实验中所用语料库中 -5芯, 各类别样本分布相差较大,而IG方法对类别样本分 4 10 A 三74方出 布极其敏感,因此,在此情况下G方法所选择的特 vi 征集代表性最差。 l 图4 宏平均F,实验结果 4结束语 Fig.4 Comparison results of macro-average F 基于统计方法和基于语言学的特征提取方法已从图 圆 可以看出袁采用本文方法在各个测试集 上的平均召回率均高于基于关联度的方法和基于频 率的方法的性能袁这说明该方法提取特征词的性能 稳定袁在各个类别的提取效果均得到明显提高遥 猿援猿摇 第 圆 组实验渊各类别数据分布极其不均匀冤 在这组实验中袁采用宏平均 云员 值和微平均 云员 值作为分类性能评价标准袁使用 猿 种经典的特征提 取方法院信息增益渊 陨郧冤 尧 曾圆 统计量渊 悦匀陨冤 尧互信息 渊酝陨冤与本文所提特征提取方法作比较遥 猿援猿援员摇 耗时实验结果 在实验中袁记录了各特征提取方法从开始执行 到执行结束整个过程所消耗的时间袁其结果如图 猿遥 图 猿摇 各方法消耗的时间 云蚤早援猿摇 悦燥皂责葬则蚤泽燥灶 则藻泽怎造贼泽 燥枣 糟燥灶泽怎皂蚤灶早 贼蚤皂藻 由于本文方法采用了多个指标以及组合方 法袁耗时有所增加遥 从图 猿 可以看出袁在该组实 验中袁本文方法在消耗时间方面劣于互信息方法 和信息增益方法袁但优于最耗时的 曾圆 统计量方 法袁但它们耗时相差不大袁这也使得本文方法有 一定的实用价值遥 猿援猿援圆摇 宏平均和微平均实验结果 从各个特征提取方法所获得的特征集渊其中的 特征已按权重逆序进行了排序冤 中袁分别选取相应 数目的特征对实验数据进行宏平均 云员 和微平均 云员 计算袁具体结果如图 源 和图 缘 所示遥 图 源摇 宏平均 云员 实验结果 云蚤早援源摇 悦燥皂责葬则蚤泽燥灶 则藻泽怎造贼泽 燥枣 皂葬糟则燥鄄葬增藻则葬早藻 云员 图 缘摇 微平均 云员 实验结果 云蚤早援缘摇 悦燥皂责葬则蚤泽燥灶 则藻泽怎造贼泽 燥枣 皂蚤糟则燥鄄葬增藻则葬早藻 云员 利用特征数目的变化来考查分类器的性能袁可 以比较准确地反映出该分类器数对据样本变化是否 敏感遥 图 源 表明院随着特征数目的递增袁宏平均 云员 值不断增加袁但是由于实验数据中各类别样本分布 极其不均匀而有所波动曰图 源 表明院随着特征个数的 不断增加袁微平均 云员 值也递增并趋于一个相对较稳 定的值遥 从图 源 和图 缘 可以看出院在本文方法所选的前 员 缘园园 个特征上 运晕晕 分类器性能最佳袁宏平均 云员 值 约为 愿源豫袁微平均 云员 值约为 怨圆豫曰在 悦匀陨 方法所选 的前 员 缘园园 个特征上 运晕晕 分类器性能最佳袁宏平均 云员 值约为 苑源豫袁微平均 云员 值约为 愿远豫曰在 酝陨 方法 所选的前 员 缘园园 个特征上 运晕晕 分类器性能最佳袁宏 平均 云员 值约为 苑园豫袁微平均 云员 值约为 愿源豫曰在 陨郧 方法所选的前 圆 园园园 个特征上 运晕晕 分类器性能最 佳袁宏平均 云员 值约为 远员豫袁微平均 云员 值约为 远苑豫遥 这表明在该组实验中袁这 源 个特征提取方法的优劣 依次为本文方法尧悦匀陨尧酝陨尧陨郧遥 原因在于院本文方法 在选择特征时袁不但考查了特征的词性和词频还考 查了特征的位置和关联度袁从而有效地对待选特征 进行全面考查袁这使得本文方法受类别分布影 响较 小袁因此所选特征集较具代表性遥 悦匀陨 方法在选择 特征时不但考查了特征在文档中存在的情况而且还 考查了特征不在文档中的情况袁酝陨 方法仅考查了特 征在文档中存在的情况袁但它们都没能有效地消除 冗余特征遥 因此袁这 圆 个方法要劣于本文方法袁但是 悦匀陨 方法要优于 酝陨 方法曰由于实验中所用语料库中 各类别样本分布相差较大袁而 陨郧 方法对类别样本分 布极其敏感袁因此袁在此情况下 陨郧 方法所选择的特 征集代表性最差遥 源摇 结束语 基于统计方法和基于语言学的特征提取方法已 窑源苑愿窑 智 能 系 统 学 报摇摇摇摇摇摇摇摇摇摇摇摇摇摇摇摇摇摇 第 怨 卷