正在加载图片...
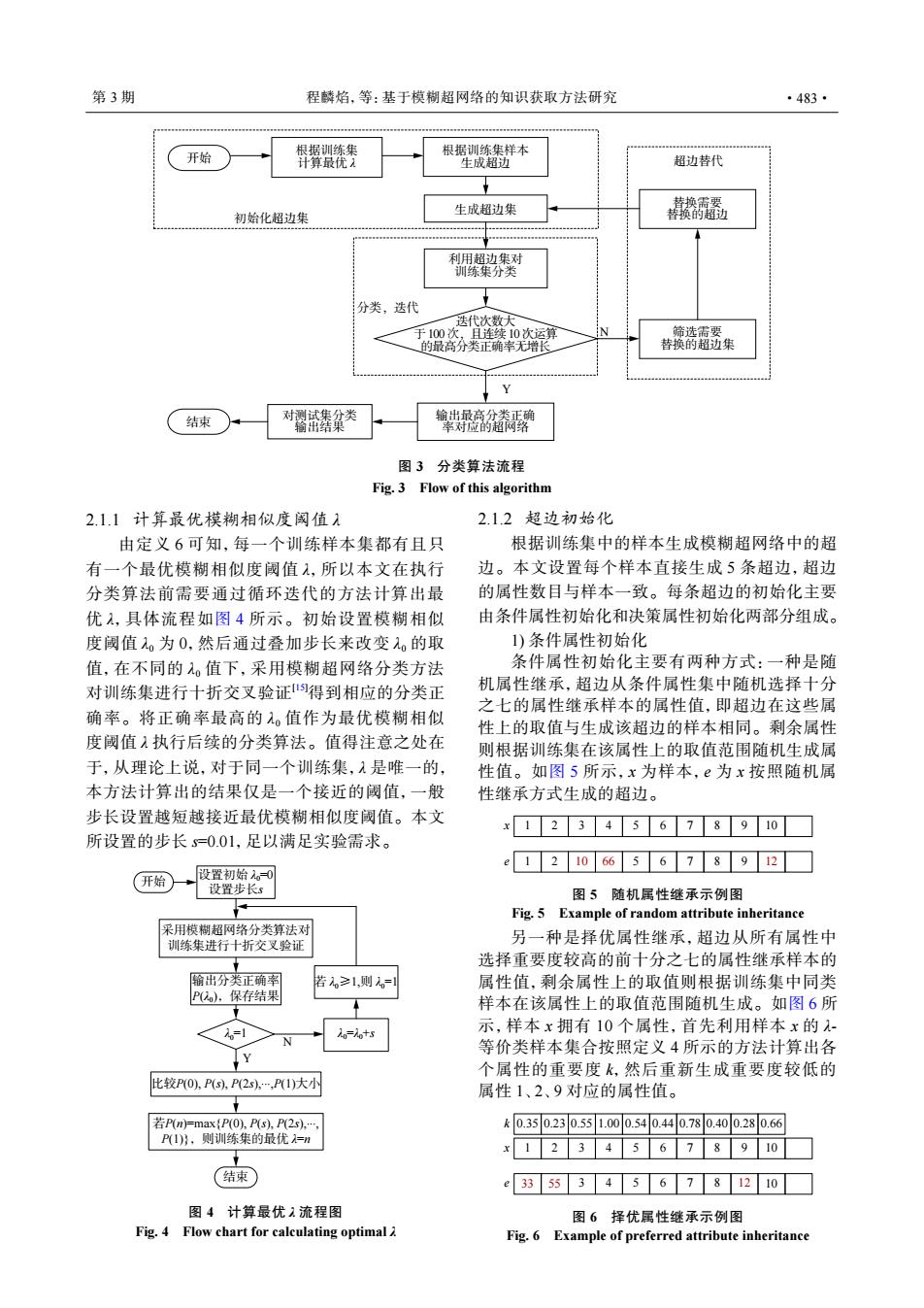
第3期 程麟焰,等:基于模糊超网络的知识获取方法研究 ·483· 开始 根据训练集 根据训练集样本 计算最优入 生成超边 超边替代 生成超边集 初始化超边集 騷 分类,迭代 选代次数大 于100次,且连续10次运算 筛选需要 的最高分类正确率无增 替换的超边集 Y 结束 对攀类 换路 图3分类算法流程 Fig.3 Flow of this algorithm 2.1.1计算最优模糊相似度阈值1 2.1.2超边初始化 由定义6可知,每一个训练样本集都有且只 根据训练集中的样本生成模糊超网络中的超 有一个最优模糊相似度阈值入,所以本文在执行 边。本文设置每个样本直接生成5条超边,超边 分类算法前需要通过循环迭代的方法计算出最 的属性数目与样本一致。每条超边的初始化主要 优1,具体流程如图4所示。初始设置模糊相似 由条件属性初始化和决策属性初始化两部分组成。 度阈值1。为0,然后通过叠加步长来改变1。的取 1)条件属性初始化 值,在不同的值下,采用模糊超网络分类方法 条件属性初始化主要有两种方式:一种是随 对训练集进行十折交叉验证得到相应的分类正 机属性继承,超边从条件属性集中随机选择十分 之七的属性继承样本的属性值,即超边在这些属 确率。将正确率最高的。值作为最优模糊相似 性上的取值与生成该超边的样本相同。剩余属性 度阈值1执行后续的分类算法。值得注意之处在 则根据训练集在该属性上的取值范围随机生成属 于,从理论上说,对于同一个训练集,入是唯一的, 性值。如图5所示,x为样本,e为x按照随机属 本方法计算出的结果仅是一个接近的阈值,一般 性继承方式生成的超边。 步长设置越短越接近最优模糊相似度阈值。本文 x12345678910☐ 所设置的步长=0.01,足以满足实验需求。 1210665678912 开始 设置初始。0 设置步长s 图5随机属性继承示例图 Fig.5 Example of random attribute inheritance 采用模糊超网络分类算法对 训练集进行十折交叉验证 另一种是择优属性继承,超边从所有属性中 选择重要度较高的前十分之七的属性继承样本的 输出分类正确率 若≥1,则。 属性值,剩余属性上的取值则根据训练集中同类 P(),保存结果 样本在该属性上的取值范围随机生成。如图6所 少 Lo-lo+s 示,样本x拥有10个属性,首先利用样本x的- 等价类样本集合按照定义4所示的方法计算出各 个属性的重要度k,然后重新生成重要度较低的 比较PO,Ps,P2s.,PI)大小N 属性1、2、9对应的属性值。 P(n)=max(P(0),P(s),P(2s)., k0.350.230.551.000.540.40.780.400.280.66 P(1)以,则训练集的最优n x12345678910 (结束 e3355345678210 图4计算最优1流程图 图6择优属性继承示例图 Fig.4 Flow chart for calculating optimal Fig.6 Example of preferred attribute inheritance开始 根据训练集样本 生成超边 生成超边集 利用超边集对 训练集分类 筛选需要 替换的超边集 替换需要 替换的超边 输出最高分类正确 率对应的超网络 对测试集分类 结束 输出结果 根据训练集 计算最优 λ N Y 初始化超边集 分类,迭代 超边替代 迭代次数大 于 100 次,且连续 10 次运算 的最高分类正确率无增长 图 3 分类算法流程 Fig. 3 Flow of this algorithm 2.1.1 计算最优模糊相似度阈值 λ 由定义 6 可知,每一个训练样本集都有且只 有一个最优模糊相似度阈值 λ,所以本文在执行 分类算法前需要通过循环迭代的方法计算出最 优 λ,具体流程如图 4 所示。初始设置模糊相似 度阈值 λ0 为 0,然后通过叠加步长来改变 λ0 的取 值,在不同的 λ0 值下,采用模糊超网络分类方法 对训练集进行十折交叉验证[15]得到相应的分类正 确率。将正确率最高的 λ0 值作为最优模糊相似 度阈值 λ 执行后续的分类算法。值得注意之处在 于,从理论上说,对于同一个训练集,λ 是唯一的, 本方法计算出的结果仅是一个接近的阈值,一般 步长设置越短越接近最优模糊相似度阈值。本文 所设置的步长 s=0.01,足以满足实验需求。 开始 采用模糊超网络分类算法对 训练集进行十折交叉验证 输出分类正确率 P(λ0 ),保存结果 λ0=1 比较P(0), P(s), P(2s),... ,P(1)大小 若P(n)=max{P(0), P(s), P(2s),... , P(1)},则训练集的最优 λ=n 结束 设置初始 λ0=0 设置步长s Y 若 λ0≥1,则 λ0=1 N λ0=λ0+s 图 4 计算最优 λ 流程图 Fig. 4 Flow chart for calculating optimal λ 2.1.2 超边初始化 根据训练集中的样本生成模糊超网络中的超 边。本文设置每个样本直接生成 5 条超边,超边 的属性数目与样本一致。每条超边的初始化主要 由条件属性初始化和决策属性初始化两部分组成。 1) 条件属性初始化 条件属性初始化主要有两种方式:一种是随 机属性继承,超边从条件属性集中随机选择十分 之七的属性继承样本的属性值,即超边在这些属 性上的取值与生成该超边的样本相同。剩余属性 则根据训练集在该属性上的取值范围随机生成属 性值。如图 5 所示,x 为样本,e 为 x 按照随机属 性继承方式生成的超边。 1 2 3 4 5 6 7 8 9 10 1 2 10 66 5 6 7 8 9 12 x e 图 5 随机属性继承示例图 Fig. 5 Example of random attribute inheritance 另一种是择优属性继承,超边从所有属性中 选择重要度较高的前十分之七的属性继承样本的 属性值,剩余属性上的取值则根据训练集中同类 样本在该属性上的取值范围随机生成。如图 6 所 示,样本 x 拥有 10 个属性,首先利用样本 x 的 λ- 等价类样本集合按照定义 4 所示的方法计算出各 个属性的重要度 k,然后重新生成重要度较低的 属性 1、2、9 对应的属性值。 1 2 3 4 3 4 5 6 7 8 9 10 33 55 5 6 7 8 12 10 x k 0.35 0.23 0.55 1.00 0.54 0.44 0.78 0.40 0.28 0.66 e 图 6 择优属性继承示例图 Fig. 6 Example of preferred attribute inheritance 第 3 期 程麟焰,等:基于模糊超网络的知识获取方法研究 ·483·