正在加载图片...
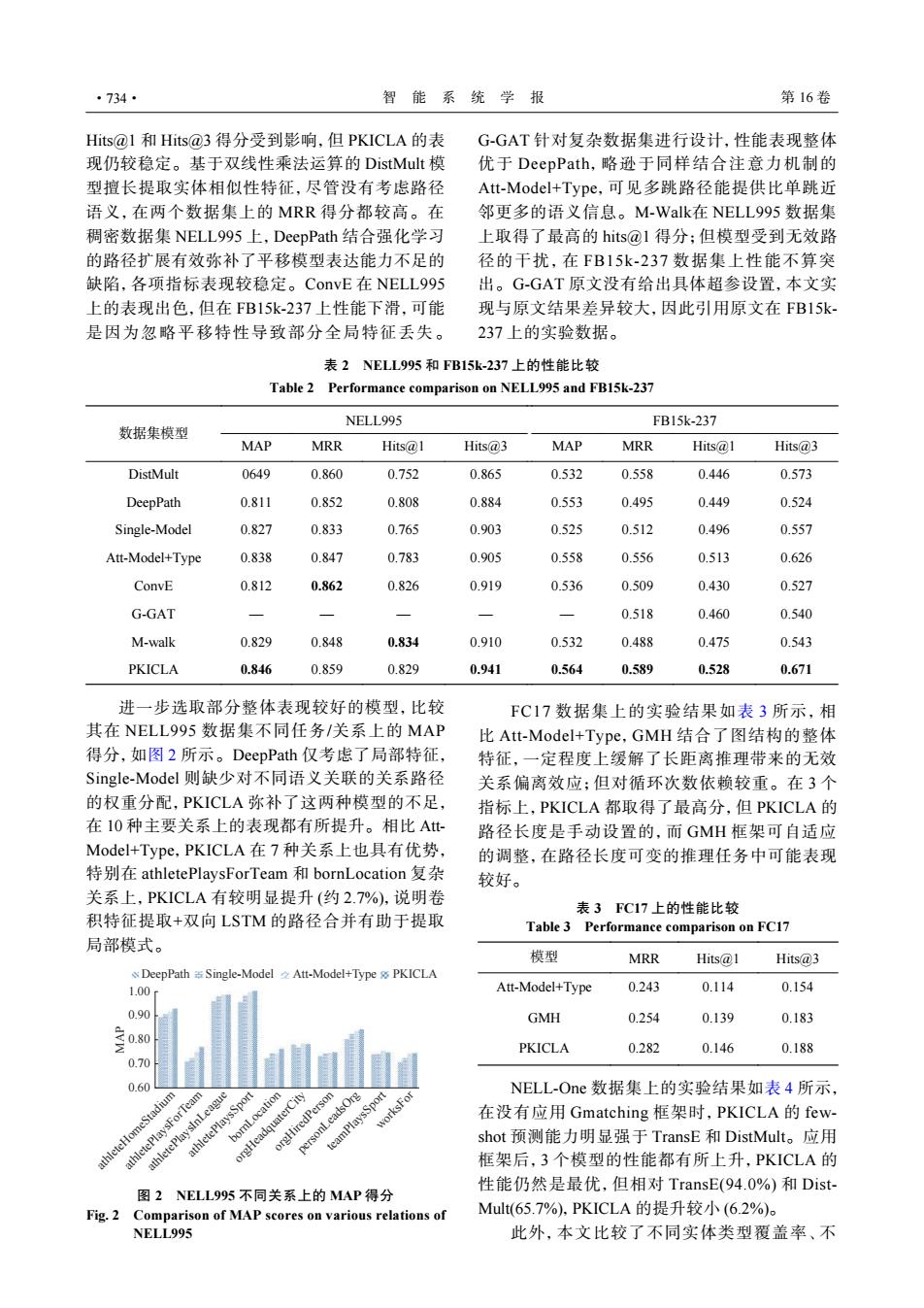
·734· 智能系统学报 第16卷 Hits@l和Hits@3得分受到影响,但PKICLA的表 G-GAT针对复杂数据集进行设计,性能表现整体 现仍较稳定。基于双线性乘法运算的DistMult模 优于DeepPath.,略逊于同样结合注意力机制的 型擅长提取实体相似性特征,尽管没有考虑路径 Att-Model+-Type,可见多跳路径能提供比单跳近 语义,在两个数据集上的MRR得分都较高。在 邻更多的语义信息。M-Walk在NELL995数据集 稠密数据集NELL995上,DeepPath结合强化学习 上取得了最高的hits@1得分:但模型受到无效路 的路径扩展有效弥补了平移模型表达能力不足的 径的干扰,在FB15k-237数据集上性能不算突 缺陷,各项指标表现较稳定。ConvE在NELL995 出。G-GAT原文没有给出具体超参设置,本文实 上的表现出色,但在FB15k-237上性能下滑,可能 现与原文结果差异较大,因此引用原文在FB15k 是因为忽略平移特性导致部分全局特征丢失。 237上的实验数据。 表2NELL995和FB15k-237上的性能比较 Table 2 Performance comparison on NELL995 and FB15k-237 NELL995 FB15k-237 数据集模型 MAP MRR Hits@l Hits@3 MAP MRR Hits 1 Hits(@3 DistMult 0649 0.860 0.752 0.865 0.532 0.558 0.446 0.573 DeepPath 0.811 0.852 0.808 0.884 0.553 0.495 0.449 0.524 Single-Model 0.827 0.833 0.765 0.903 0.525 0.512 0.496 0.557 Att-Model+Type 0.838 0.847 0.783 0.905 0.558 0.556 0.513 0.626 ConvE 0.812 0.862 0.826 0.919 0.536 0.509 0.430 0.527 G-GAT 0.518 0.460 0.540 M-walk 0.829 0.848 0.834 0.910 0.532 0.488 0.475 0.543 PKICLA 0.846 0.859 0.829 0.941 0.564 0.589 0.528 0.671 进一步选取部分整体表现较好的模型,比较 FC17数据集上的实验结果如表3所示,相 其在NELL995数据集不同任务/关系上的MAP 比Att-Model+-Type,GMH结合了图结构的整体 得分,如图2所示。DeepPath仅考虑了局部特征, 特征,一定程度上缓解了长距离推理带来的无效 Single-Model则缺少对不同语义关联的关系路径 关系偏离效应;但对循环次数依赖较重。在3个 的权重分配,PKICLA弥补了这两种模型的不足, 指标上,PKICLA都取得了最高分,但PKICLA的 在10种主要关系上的表现都有所提升。相比Att- 路径长度是手动设置的,而GMH框架可自适应 Model+-Type,PKICLA在7种关系上也具有优势, 的调整,在路径长度可变的推理任务中可能表现 特别在athletePlaysForTeam和bornLocation复杂 较好。 关系上,PKICLA有较明显提升(约2.7%),说明卷 积特征提取+双向LSTM的路径合并有助于提取 表3FC17上的性能比较 Table 3 Performance comparison on FC17 局部模式。 模型 MRR Hits@1 Hits@3 DeepPath Single-Model2 Att-Model+Type PKICLA 1.00 Att-Model+Type 0.243 0.114 0.154 0.90 GMH 0.254 0.139 0.183 PKICLA 0.282 0.146 0.188 0.70 0.60 NELL-One数据集上的实验结果如表4所示, athleteHomeStadium bornLocation personLeadsOrg orgHiredPerson orgHeadquaterCity teamPlaysSport worksFor 在没有应用Gmatching框架时,PKICLA的few- shot预测能力明显强于TransE和DistMult。.应用 框架后,3个模型的性能都有所上升,PKICLA的 性能仍然是最优,但相对TransE(94.0%)和Dist- 图2NELL995不同关系上的MAP得分 Fig.2 Comparison of MAP scores on various relations of Mult(65.7%),PKICLA的提升较小(6.2%) NELL995 此外,本文比较了不同实体类型覆盖率、不Hits@1 和 Hits@3 得分受到影响,但 PKICLA 的表 现仍较稳定。基于双线性乘法运算的 DistMult 模 型擅长提取实体相似性特征,尽管没有考虑路径 语义,在两个数据集上的 MRR 得分都较高。在 稠密数据集 NELL995 上,DeepPath 结合强化学习 的路径扩展有效弥补了平移模型表达能力不足的 缺陷,各项指标表现较稳定。ConvE 在 NELL995 上的表现出色,但在 FB15k-237 上性能下滑,可能 是因为忽略平移特性导致部分全局特征丢失。 G-GAT 针对复杂数据集进行设计,性能表现整体 优于 DeepPath,略逊于同样结合注意力机制的 Att-Model+Type,可见多跳路径能提供比单跳近 邻更多的语义信息。M-Walk在 NELL995 数据集 上取得了最高的 hits@1 得分;但模型受到无效路 径的干扰,在 FB15k-237 数据集上性能不算突 出。G-GAT 原文没有给出具体超参设置,本文实 现与原文结果差异较大,因此引用原文在 FB15k- 237 上的实验数据。 表 2 NELL995 和 FB15k-237 上的性能比较 Table 2 Performance comparison on NELL995 and FB15k-237 数据集模型 NELL995 FB15k-237 MAP MRR Hits@1 Hits@3 MAP MRR Hits@1 Hits@3 DistMult 0649 0.860 0.752 0.865 0.532 0.558 0.446 0.573 DeepPath 0.811 0.852 0.808 0.884 0.553 0.495 0.449 0.524 Single-Model 0.827 0.833 0.765 0.903 0.525 0.512 0.496 0.557 Att-Model+Type 0.838 0.847 0.783 0.905 0.558 0.556 0.513 0.626 ConvE 0.812 0.862 0.826 0.919 0.536 0.509 0.430 0.527 G-GAT — — — — — 0.518 0.460 0.540 M-walk 0.829 0.848 0.834 0.910 0.532 0.488 0.475 0.543 PKICLA 0.846 0.859 0.829 0.941 0.564 0.589 0.528 0.671 进一步选取部分整体表现较好的模型,比较 其在 NELL995 数据集不同任务/关系上的 MAP 得分,如图 2 所示。DeepPath 仅考虑了局部特征, Single-Model 则缺少对不同语义关联的关系路径 的权重分配,PKICLA 弥补了这两种模型的不足, 在 10 种主要关系上的表现都有所提升。相比 AttModel+Type,PKICLA 在 7 种关系上也具有优势, 特别在 athletePlaysForTeam 和 bornLocation 复杂 关系上,PKICLA 有较明显提升 (约 2.7%),说明卷 积特征提取+双向 LSTM 的路径合并有助于提取 局部模式。 1.00 0.90 0.80 0.70 0.60 athleteHomeStadium athletePlaysForTeam athletePlaysInLeague athletePlaysSport bornLocation orgHeadquaterCity orgHiredPerson personLeadsOrg teamPlaysSport worksFor MAP DeepPath Single-Model Att-Model+Type PKICLA 图 2 NELL995 不同关系上的 MAP 得分 Fig. 2 Comparison of MAP scores on various relations of NELL995 FC17 数据集上的实验结果如表 3 所示,相 比 Att-Model+Type,GMH 结合了图结构的整体 特征,一定程度上缓解了长距离推理带来的无效 关系偏离效应;但对循环次数依赖较重。在 3 个 指标上,PKICLA 都取得了最高分,但 PKICLA 的 路径长度是手动设置的,而 GMH 框架可自适应 的调整,在路径长度可变的推理任务中可能表现 较好。 表 3 FC17 上的性能比较 Table 3 Performance comparison on FC17 模型 MRR Hits@1 Hits@3 Att-Model+Type 0.243 0.114 0.154 GMH 0.254 0.139 0.183 PKICLA 0.282 0.146 0.188 NELL-One 数据集上的实验结果如表 4 所示, 在没有应用 Gmatching 框架时,PKICLA 的 fewshot 预测能力明显强于 TransE 和 DistMult。应用 框架后,3 个模型的性能都有所上升,PKICLA 的 性能仍然是最优,但相对 TransE(94.0%) 和 DistMult(65.7%),PKICLA 的提升较小 (6.2%)。 此外,本文比较了不同实体类型覆盖率、不 ·734· 智 能 系 统 学 报 第 16 卷