正在加载图片...
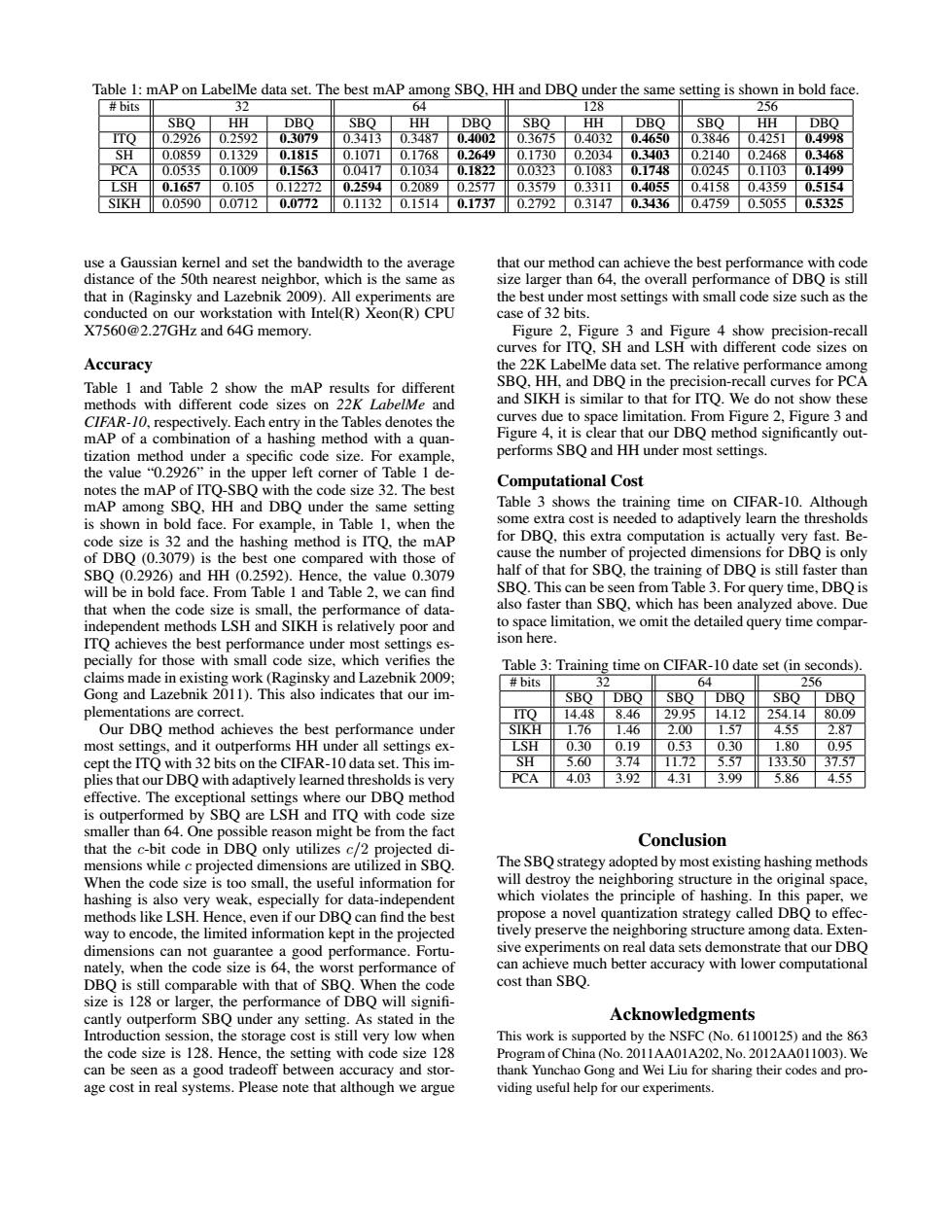
Table 1:mAP on LabelMe data set.The best mAP among SBO.HH and DBO under the same setting is shown in bold face #bits 32 64 128 256 SBO HH DBO SBO HH DBO SBO HH DBO SBO HH DBO ITQ 0.29260.2592 0.3079 0.3413 0.3487 0.4002 0.3675 0.4032 0.4650 0.3846 0.4251 0.4998 SH 0.0859 0.1329 0.1815 0.1071 0.1768 0.2649 0.1730 0.2034 0.3403 0.2140 0.2468 0.3468 PCA 0.0535 0.1009 0.1563 0.0417 0.1034 0.1822 0.0323 0.1083 0.1748 0.0245 0.1103 0.1499 LSH 0.1657 0.105 0.12272 0.2594 0.2089 0.2577 0.3579 0.3311 0.4055 0.4158 0.4359 0.5154 SIKH 0.0590 0.0712 0.0772 0.1132 0.1514 0.1737 0.2792 0.3147 0.3436 0.4759 0.50550.5325 use a Gaussian kernel and set the bandwidth to the average that our method can achieve the best performance with code distance of the 50th nearest neighbor,which is the same as size larger than 64,the overall performance of DBQ is still that in (Raginsky and Lazebnik 2009).All experiments are the best under most settings with small code size such as the conducted on our workstation with Intel(R)Xeon(R)CPU case of 32 bits. X7560@2.27GHz and 64G memory Figure 2,Figure 3 and Figure 4 show precision-recall curves for ITO.SH and LSH with different code sizes on Accuracy the 22K LabelMe data set.The relative performance among Table 1 and Table 2 show the mAP results for different SBQ,HH,and DBQ in the precision-recall curves for PCA methods with different code sizes on 22K LabelMe and and SIKH is similar to that for ITQ.We do not show these CIFAR-10,respectively.Each entry in the Tables denotes the curves due to space limitation.From Figure 2,Figure 3 and mAP of a combination of a hashing method with a quan- Figure 4,it is clear that our DBQ method significantly out- tization method under a specific code size.For example, performs SBQ and HH under most settings. the value"0.2926"in the upper left corner of Table 1 de- notes the mAP of ITQ-SBQ with the code size 32.The best Computational Cost mAP among SBQ,HH and DBQ under the same setting Table 3 shows the training time on CIFAR-10.Although is shown in bold face.For example,in Table 1.when the some extra cost is needed to adaptively learn the thresholds code size is 32 and the hashing method is ITQ,the mAP for DBQ,this extra computation is actually very fast.Be- of DBQ(0.3079)is the best one compared with those of cause the number of projected dimensions for DBQ is only SBO(0.2926)and HH (0.2592).Hence,the value 0.3079 half of that for SBO.the training of DBO is still faster than will be in bold face.From Table 1 and Table 2,we can find SBQ.This can be seen from Table 3.For query time,DBQ is that when the code size is small,the performance of data- also faster than SBQ,which has been analyzed above.Due independent methods LSH and SIKH is relatively poor and to space limitation,we omit the detailed query time compar- ITO achieves the best performance under most settings es- ison here. pecially for those with small code size,which verifies the Table 3:Training time on CIFAR-10 date set (in seconds). claims made in existing work(Raginsky and Lazebnik 2009; #bits 32 64 256 Gong and Lazebnik 2011).This also indicates that our im- SBO DBO SBO DBO SBO DBO plementations are correct. ITO 14.48 8.46 29.95 14.12 25414 80.09 Our DBQ method achieves the best performance under SIKH 1.76 1.46 2.00 1.57 4.55 2.87 most settings,and it outperforms HH under all settings ex- LSH 0.30 0.19 0.53 0.30 1.80 0.95 cept the ITQ with 32 bits on the CIFAR-10 data set.This im- SH 5.60 3.74 11.72 5.57 133.50 37.57 plies that our DBQ with adaptively learned thresholds is very 4.03 3.92 4.31 3.99 5.86 4.55 effective.The exceptional settings where our DBQ method is outperformed by SBQ are LSH and ITQ with code size smaller than 64.One possible reason might be from the fact that the c-bit code in DBQ only utilizes c/2 projected di- Conclusion mensions while c projected dimensions are utilized in SBQ. The SBQ strategy adopted by most existing hashing methods When the code size is too small,the useful information for will destroy the neighboring structure in the original space, hashing is also very weak,especially for data-independent which violates the principle of hashing.In this paper,we methods like LSH.Hence,even if our DBO can find the best propose a novel quantization strategy called DBQ to effec- way to encode,the limited information kept in the projected tively preserve the neighboring structure among data.Exten- dimensions can not guarantee a good performance.Fortu- sive experiments on real data sets demonstrate that our DBQ nately,when the code size is 64,the worst performance of can achieve much better accuracy with lower computational DBQ is still comparable with that of SBQ.When the code cost than SBO. size is 128 or larger,the performance of DBQ will signifi- cantly outperform SBQ under any setting.As stated in the Acknowledgments Introduction session,the storage cost is still very low when This work is supported by the NSFC (No.61100125)and the 863 the code size is 128.Hence,the setting with code size 128 Program of China (No.2011AA01A202.No.2012AA011003).We can be seen as a good tradeoff between accuracy and stor- thank Yunchao Gong and Wei Liu for sharing their codes and pro- age cost in real systems.Please note that although we argue viding useful help for our experiments.Table 1: mAP on LabelMe data set. The best mAP among SBQ, HH and DBQ under the same setting is shown in bold face. # bits 32 64 128 256 SBQ HH DBQ SBQ HH DBQ SBQ HH DBQ SBQ HH DBQ ITQ 0.2926 0.2592 0.3079 0.3413 0.3487 0.4002 0.3675 0.4032 0.4650 0.3846 0.4251 0.4998 SH 0.0859 0.1329 0.1815 0.1071 0.1768 0.2649 0.1730 0.2034 0.3403 0.2140 0.2468 0.3468 PCA 0.0535 0.1009 0.1563 0.0417 0.1034 0.1822 0.0323 0.1083 0.1748 0.0245 0.1103 0.1499 LSH 0.1657 0.105 0.12272 0.2594 0.2089 0.2577 0.3579 0.3311 0.4055 0.4158 0.4359 0.5154 SIKH 0.0590 0.0712 0.0772 0.1132 0.1514 0.1737 0.2792 0.3147 0.3436 0.4759 0.5055 0.5325 use a Gaussian kernel and set the bandwidth to the average distance of the 50th nearest neighbor, which is the same as that in (Raginsky and Lazebnik 2009). All experiments are conducted on our workstation with Intel(R) Xeon(R) CPU X7560@2.27GHz and 64G memory. Accuracy Table 1 and Table 2 show the mAP results for different methods with different code sizes on 22K LabelMe and CIFAR-10, respectively. Each entry in the Tables denotes the mAP of a combination of a hashing method with a quantization method under a specific code size. For example, the value “0.2926” in the upper left corner of Table 1 denotes the mAP of ITQ-SBQ with the code size 32. The best mAP among SBQ, HH and DBQ under the same setting is shown in bold face. For example, in Table 1, when the code size is 32 and the hashing method is ITQ, the mAP of DBQ (0.3079) is the best one compared with those of SBQ (0.2926) and HH (0.2592). Hence, the value 0.3079 will be in bold face. From Table 1 and Table 2, we can find that when the code size is small, the performance of dataindependent methods LSH and SIKH is relatively poor and ITQ achieves the best performance under most settings especially for those with small code size, which verifies the claims made in existing work (Raginsky and Lazebnik 2009; Gong and Lazebnik 2011). This also indicates that our implementations are correct. Our DBQ method achieves the best performance under most settings, and it outperforms HH under all settings except the ITQ with 32 bits on the CIFAR-10 data set. This implies that our DBQ with adaptively learned thresholds is very effective. The exceptional settings where our DBQ method is outperformed by SBQ are LSH and ITQ with code size smaller than 64. One possible reason might be from the fact that the c-bit code in DBQ only utilizes c/2 projected dimensions while c projected dimensions are utilized in SBQ. When the code size is too small, the useful information for hashing is also very weak, especially for data-independent methods like LSH. Hence, even if our DBQ can find the best way to encode, the limited information kept in the projected dimensions can not guarantee a good performance. Fortunately, when the code size is 64, the worst performance of DBQ is still comparable with that of SBQ. When the code size is 128 or larger, the performance of DBQ will signifi- cantly outperform SBQ under any setting. As stated in the Introduction session, the storage cost is still very low when the code size is 128. Hence, the setting with code size 128 can be seen as a good tradeoff between accuracy and storage cost in real systems. Please note that although we argue that our method can achieve the best performance with code size larger than 64, the overall performance of DBQ is still the best under most settings with small code size such as the case of 32 bits. Figure 2, Figure 3 and Figure 4 show precision-recall curves for ITQ, SH and LSH with different code sizes on the 22K LabelMe data set. The relative performance among SBQ, HH, and DBQ in the precision-recall curves for PCA and SIKH is similar to that for ITQ. We do not show these curves due to space limitation. From Figure 2, Figure 3 and Figure 4, it is clear that our DBQ method significantly outperforms SBQ and HH under most settings. Computational Cost Table 3 shows the training time on CIFAR-10. Although some extra cost is needed to adaptively learn the thresholds for DBQ, this extra computation is actually very fast. Because the number of projected dimensions for DBQ is only half of that for SBQ, the training of DBQ is still faster than SBQ. This can be seen from Table 3. For query time, DBQ is also faster than SBQ, which has been analyzed above. Due to space limitation, we omit the detailed query time comparison here. Table 3: Training time on CIFAR-10 date set (in seconds). # bits 32 64 256 SBQ DBQ SBQ DBQ SBQ DBQ ITQ 14.48 8.46 29.95 14.12 254.14 80.09 SIKH 1.76 1.46 2.00 1.57 4.55 2.87 LSH 0.30 0.19 0.53 0.30 1.80 0.95 SH 5.60 3.74 11.72 5.57 133.50 37.57 PCA 4.03 3.92 4.31 3.99 5.86 4.55 Conclusion The SBQ strategy adopted by most existing hashing methods will destroy the neighboring structure in the original space, which violates the principle of hashing. In this paper, we propose a novel quantization strategy called DBQ to effectively preserve the neighboring structure among data. Extensive experiments on real data sets demonstrate that our DBQ can achieve much better accuracy with lower computational cost than SBQ. Acknowledgments This work is supported by the NSFC (No. 61100125) and the 863 Program of China (No. 2011AA01A202, No. 2012AA011003). We thank Yunchao Gong and Wei Liu for sharing their codes and providing useful help for our experiments