正在加载图片...
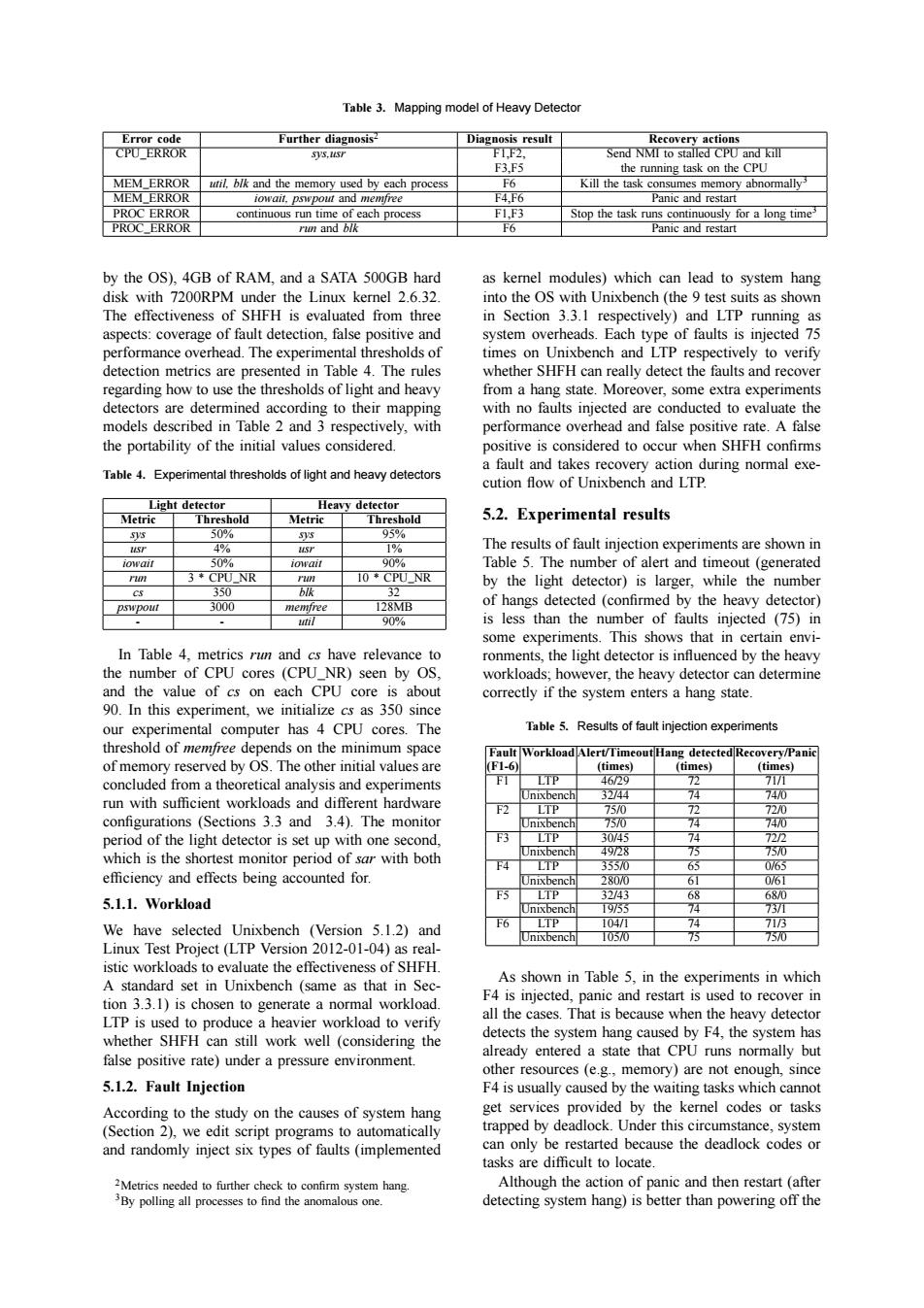
Table 3.Mapping model of Heavy Detector Error code Further diagnosis2 Diagnosis result Recovery actions CPU■ERROR s,1s7 F1.F2, Send NMI to stalled CPO and kill F3,F5 the running task on the CPU MEM ERROR util.blk and the memory used by each process F6 Kill the task consumes memory abnormally' MEM_ERROR iowait.pswpout and memfree F4,F6 Panic and restart PROC ERROR continuous run time of each process F1,F3 Stop the task runs continuously for a long time' PROC_ERROR run and blk F6 Panic and restart by the OS).4GB of RAM.and a SATA 500GB hard as kernel modules)which can lead to system hang disk with 7200RPM under the Linux kernel 2.6.32 into the OS with Unixbench(the 9 test suits as shown The effectiveness of SHFH is evaluated from three in Section 3.3.1 respectively)and LTP running as aspects:coverage of fault detection,false positive and system overheads.Each type of faults is injected 75 performance overhead.The experimental thresholds of times on Unixbench and LTP respectively to verify detection metrics are presented in Table 4.The rules whether SHFH can really detect the faults and recover regarding how to use the thresholds of light and heavy from a hang state.Moreover,some extra experiments detectors are determined according to their mapping with no faults injected are conducted to evaluate the models described in Table 2 and 3 respectively,with performance overhead and false positive rate.A false the portability of the initial values considered positive is considered to occur when SHFH confirms Table 4.Experimental thresholds of light and heavy detectors a fault and takes recovery action during normal exe- cution flow of Unixbench and LTP. Light detector Heavy detector Metric Threshold Metric Threshold 5.2.Experimental results sys 50% 5 95% 47 4% T 1% The results of fault injection experiments are shown in iowait 5096 iowait 90% Table 5.The number of alert and timeout(generated rin 3*CPU NR M 10*CPU NR by the light detector)is larger,while the number 350 blk 32 pswpout 3000 memfree 128MB of hangs detected (confirmed by the heavy detector) util 90% is less than the number of faults injected (75)in some experiments.This shows that in certain envi- In Table 4.metrics run and cs have relevance to ronments,the light detector is influenced by the heavy the number of CPU cores (CPU_NR)seen by OS, workloads;however,the heavy detector can determine and the value of cs on each CPU core is about correctly if the system enters a hang state 90.In this experiment,we initialize cs as 350 since our experimental computer has 4 CPU cores.The Table 5.Results of fault injection experiments threshold of memfree depends on the minimum space Fault Workload Alert/Timeout Hang detected Recovery/Panic of memory reserved by OS.The other initial values are (F1-6 (times) (times) (times) concluded from a theoretical analysis and experiments LTP 46W29 72 7171 Onixbench 3244 74 74/0 run with sufficient workloads and different hardware F2 LTP 75/0 72 72/0 configurations (Sections 3.3 and 3.4).The monitor Onixbench 7570 74 7470 period of the light detector is set up with one second, F3 LTP 30/45 74 722 which is the shortest monitor period of sar with both Unixbencl五 49728 75 7570 4 LTP 3550 63 0/65 efficiency and effects being accounted for. Onixbench 280/0 61 0/61 LTP 32/43 68 68/0 5.1.1.Workload 1953 74 730 6 ITP 104/1 74 713 We have selected Unixbench (Version 5.1.2)and Unixbench 10570 75 750 Linux Test Project(LTP Version 2012-01-04)as real- istic workloads to evaluate the effectiveness of SHFH A standard set in Unixbench (same as that in Sec- As shown in Table 5,in the experiments in which tion 3.3.1)is chosen to generate a normal workload. F4 is injected,panic and restart is used to recover in LTP is used to produce a heavier workload to verify all the cases.That is because when the heavy detector whether SHFH can still work well (considering the detects the system hang caused by F4,the system has already entered a state that CPU runs normally but false positive rate)under a pressure environment other resources (e.g.,memory)are not enough,since 5.1.2.Fault Injection F4 is usually caused by the waiting tasks which cannot According to the study on the causes of system hang get services provided by the kernel codes or tasks (Section 2),we edit script programs to automatically trapped by deadlock.Under this circumstance,system and randomly inject six types of faults (implemented can only be restarted because the deadlock codes or tasks are difficult to locate 2Metrics needed to further check to confirm system hang. Although the action of panic and then restart (after 3By polling all processes to find the anomalous one. detecting system hang)is better than powering off theTable 3. Mapping model of Heavy Detector Error code Further diagnosis2 Diagnosis result Recovery actions CPU ERROR sys,usr F1,F2, Send NMI to stalled CPU and kill F3,F5 the running task on the CPU MEM ERROR util, blk and the memory used by each process F6 Kill the task consumes memory abnormally3 MEM ERROR iowait, pswpout and memfree F4,F6 Panic and restart PROC ERROR continuous run time of each process F1,F3 Stop the task runs continuously for a long time3 PROC ERROR run and blk F6 Panic and restart by the OS), 4GB of RAM, and a SATA 500GB hard disk with 7200RPM under the Linux kernel 2.6.32. The effectiveness of SHFH is evaluated from three aspects: coverage of fault detection, false positive and performance overhead. The experimental thresholds of detection metrics are presented in Table 4. The rules regarding how to use the thresholds of light and heavy detectors are determined according to their mapping models described in Table 2 and 3 respectively, with the portability of the initial values considered. Table 4. Experimental thresholds of light and heavy detectors Light detector Heavy detector Metric Threshold Metric Threshold sys 50% sys 95% usr 4% usr 1% iowait 50% iowait 90% run 3 * CPU NR run 10 * CPU NR cs 350 blk 32 pswpout 3000 memfree 128MB - - util 90% In Table 4, metrics run and cs have relevance to the number of CPU cores (CPU NR) seen by OS, and the value of cs on each CPU core is about 90. In this experiment, we initialize cs as 350 since our experimental computer has 4 CPU cores. The threshold of memfree depends on the minimum space of memory reserved by OS. The other initial values are concluded from a theoretical analysis and experiments run with sufficient workloads and different hardware configurations (Sections 3.3 and 3.4). The monitor period of the light detector is set up with one second, which is the shortest monitor period of sar with both efficiency and effects being accounted for. 5.1.1. Workload We have selected Unixbench (Version 5.1.2) and Linux Test Project (LTP Version 2012-01-04) as realistic workloads to evaluate the effectiveness of SHFH. A standard set in Unixbench (same as that in Section 3.3.1) is chosen to generate a normal workload. LTP is used to produce a heavier workload to verify whether SHFH can still work well (considering the false positive rate) under a pressure environment. 5.1.2. Fault Injection According to the study on the causes of system hang (Section 2), we edit script programs to automatically and randomly inject six types of faults (implemented 2Metrics needed to further check to confirm system hang. 3By polling all processes to find the anomalous one. as kernel modules) which can lead to system hang into the OS with Unixbench (the 9 test suits as shown in Section 3.3.1 respectively) and LTP running as system overheads. Each type of faults is injected 75 times on Unixbench and LTP respectively to verify whether SHFH can really detect the faults and recover from a hang state. Moreover, some extra experiments with no faults injected are conducted to evaluate the performance overhead and false positive rate. A false positive is considered to occur when SHFH confirms a fault and takes recovery action during normal execution flow of Unixbench and LTP. 5.2. Experimental results The results of fault injection experiments are shown in Table 5. The number of alert and timeout (generated by the light detector) is larger, while the number of hangs detected (confirmed by the heavy detector) is less than the number of faults injected (75) in some experiments. This shows that in certain environments, the light detector is influenced by the heavy workloads; however, the heavy detector can determine correctly if the system enters a hang state. Table 5. Results of fault injection experiments Fault Workload Alert/Timeout Hang detected Recovery/Panic (F1-6) (times) (times) (times) F1 LTP 46/29 72 71/1 Unixbench 32/44 74 74/0 F2 LTP 75/0 72 72/0 Unixbench 75/0 74 74/0 F3 LTP 30/45 74 72/2 Unixbench 49/28 75 75/0 F4 LTP 355/0 65 0/65 Unixbench 280/0 61 0/61 F5 LTP 32/43 68 68/0 Unixbench 19/55 74 73/1 F6 LTP 104/1 74 71/3 Unixbench 105/0 75 75/0 As shown in Table 5, in the experiments in which F4 is injected, panic and restart is used to recover in all the cases. That is because when the heavy detector detects the system hang caused by F4, the system has already entered a state that CPU runs normally but other resources (e.g., memory) are not enough, since F4 is usually caused by the waiting tasks which cannot get services provided by the kernel codes or tasks trapped by deadlock. Under this circumstance, system can only be restarted because the deadlock codes or tasks are difficult to locate. Although the action of panic and then restart (after detecting system hang) is better than powering off the