正在加载图片...
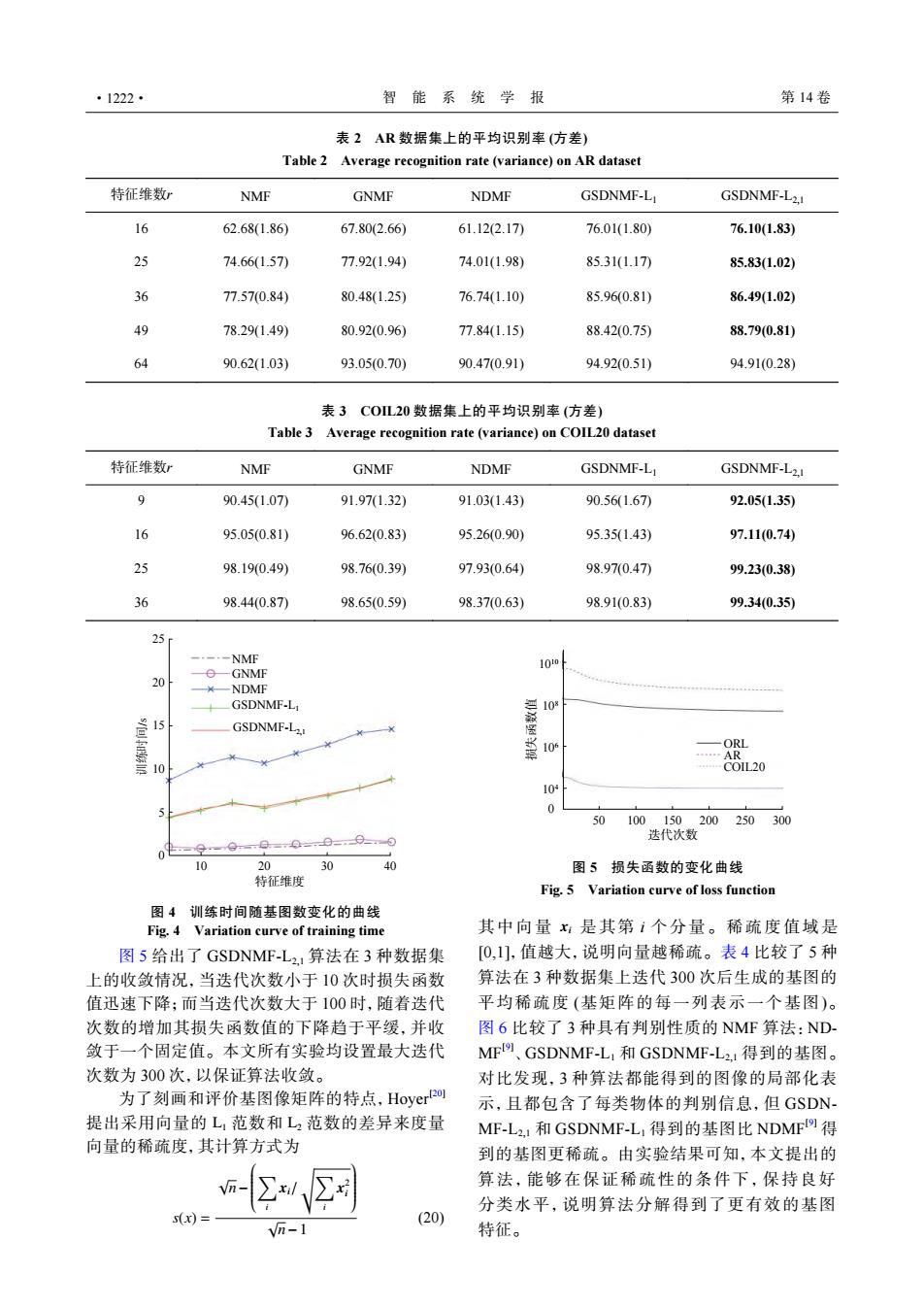
·1222· 智能系统学报 第14卷 表2AR数据集上的平均识别率(方差) Table 2 Average recognition rate(variance)on AR dataset 特征维数 NMF GNMF NDMF GSDNMF-LI GSDNMF-L21 6 62.68(1.86) 67.80(2.66) 61.12(2.17 76.01(1.80) 76.10(1.83) 25 74.66(1.57) 77.92(1.94) 74.01(1.98) 85.31(1.17) 85.83(1.02) 36 77.570.84) 80.48(1.25) 76.741.10) 85.96(0.81) 86.49(1.02) 49 78.291.49) 80.92(0.96) 77.84(1.15) 88.42(0.75) 88.79(0.81) 64 90.62(1.03) 93.05(0.70) 90.47(0.91) 94.92(0.51) 94.91(0.28) 表3C0ⅡL20数据集上的平均识别率(方差) Table 3 Average recognition rate(variance)on COIL20 dataset 特征维数 NMF GNMF NDMF GSDNMF-LI GSDNMF-L2,1 9 90.45(1.07) 91.97(1.32) 91.03(1.43) 90.56(1.67 92.05(1.35) 16 95.05(0.81) 96.62(0.83) 95.26(0.90) 95.35(1.43) 97.11(0.74) 25 98.19(0.49) 98.76(0.39) 97.93(0.64) 98.97(0.47) 99.23(0.38) 36 98.440.87) 98.650.59) 98.37(0.63) 98.91(0.83) 99.340.35) -·-NMF 1010 20 -eGNMF A—NDMF _GSDNMF-LI GSDNMF-L2 -ORL ....AR 三10 COIL20 10 0 50 100150200250300 =9-9-0-0-90 迭代次数 10 20 30 40 图5损失函数的变化曲线 特征维度 Fig.5 Variation curve of loss function 图4训练时间随基图数变化的曲线 Fig.4 Variation curve of training time 其中向量:是其第i个分量。稀疏度值域是 图5给出了GSDNMF-L2!算法在3种数据集 [0,1],值越大,说明向量越稀疏。表4比较了5种 上的收敛情况,当迭代次数小于10次时损失函数 算法在3种数据集上迭代300次后生成的基图的 值迅速下降:而当迭代次数大于100时,随着迭代 平均稀疏度(基矩阵的每一列表示一个基图)。 次数的增加其损失函数值的下降趋于平缓,并收 图6比较了3种具有判别性质的NMF算法:ND 敛于一个固定值。本文所有实验均设置最大迭代 MF9、GSDNMF-L1和GSDNMF-L2,1得到的基图。 次数为300次,以保证算法收敛。 对比发现,3种算法都能得到的图像的局部化表 为了刻画和评价基图像矩阵的特点,Hoyer2ol 示,且都包含了每类物体的判别信息,但GSDN 提出采用向量的L,范数和L2范数的差异来度量 MF-L21和GSDNMF-L,得到的基图比NDMF得 向量的稀疏度,其计算方式为 到的基图更稀疏。由实验结果可知,本文提出的 算法,能够在保证稀疏性的条件下,保持良好 分类水平,说明算法分解得到了更有效的基图 (x)= Vn-1 (20) 特征。表 2 AR 数据集上的平均识别率 (方差) Table 2 Average recognition rate (variance) on AR dataset 特征维数r NMF GNMF NDMF GSDNMF-L1 GSDNMF-L2,1 16 62.68(1.86) 67.80(2.66) 61.12(2.17) 76.01(1.80) 76.10(1.83) 25 74.66(1.57) 77.92(1.94) 74.01(1.98) 85.31(1.17) 85.83(1.02) 36 77.57(0.84) 80.48(1.25) 76.74(1.10) 85.96(0.81) 86.49(1.02) 49 78.29(1.49) 80.92(0.96) 77.84(1.15) 88.42(0.75) 88.79(0.81) 64 90.62(1.03) 93.05(0.70) 90.47(0.91) 94.92(0.51) 94.91(0.28) 表 3 COIL20 数据集上的平均识别率 (方差) Table 3 Average recognition rate (variance) on COIL20 dataset 特征维数r NMF GNMF NDMF GSDNMF-L1 GSDNMF-L2,1 9 90.45(1.07) 91.97(1.32) 91.03(1.43) 90.56(1.67) 92.05(1.35) 16 95.05(0.81) 96.62(0.83) 95.26(0.90) 95.35(1.43) 97.11(0.74) 25 98.19(0.49) 98.76(0.39) 97.93(0.64) 98.97(0.47) 99.23(0.38) 36 98.44(0.87) 98.65(0.59) 98.37(0.63) 98.91(0.83) 99.34(0.35) 10 0 5 10 15 20 25 20 30 40 特征维度 训练时间/s NMF GNMF NDMF GSDNMF-L1 GSDNMF-L2,1 图 4 训练时间随基图数变化的曲线 Fig. 4 Variation curve of training time 图 5 给出了 GSDNMF-L2,1 算法在 3 种数据集 上的收敛情况,当迭代次数小于 10 次时损失函数 值迅速下降;而当迭代次数大于 100 时,随着迭代 次数的增加其损失函数值的下降趋于平缓,并收 敛于一个固定值。本文所有实验均设置最大迭代 次数为 300 次,以保证算法收敛。 L1 L2 为了刻画和评价基图像矩阵的特点,Hoyer[20] 提出采用向量的 范数和 范数的差异来度量 向量的稀疏度,其计算方式为 s(x) = √ n− ∑ i xi/ √∑ i x 2 i √ n−1 (20) 其中向量 xi 是其第 i 个分量。稀疏度值域是 [0,1],值越大,说明向量越稀疏。表 4 比较了 5 种 算法在 3 种数据集上迭代 300 次后生成的基图的 平均稀疏度 (基矩阵的每一列表示一个基图)。 图 6 比较了 3 种具有判别性质的 NMF 算法:NDMF[9] 、GSDNMF-L1 和 GSDNMF-L2,1 得到的基图。 对比发现,3 种算法都能得到的图像的局部化表 示,且都包含了每类物体的判别信息,但 GSDNMF-L2,1 和 GSDNMF-L1 得到的基图比 NDMF[9] 得 到的基图更稀疏。由实验结果可知,本文提出的 算法,能够在保证稀疏性的条件下,保持良好 分类水平,说明算法分解得到了更有效的基图 特征。 50 104 106 108 1010 100 150 200 250 300 损失函数值 迭代次数 ORL AR COIL20 0 图 5 损失函数的变化曲线 Fig. 5 Variation curve of loss function ·1222· 智 能 系 统 学 报 第 14 卷