正在加载图片...
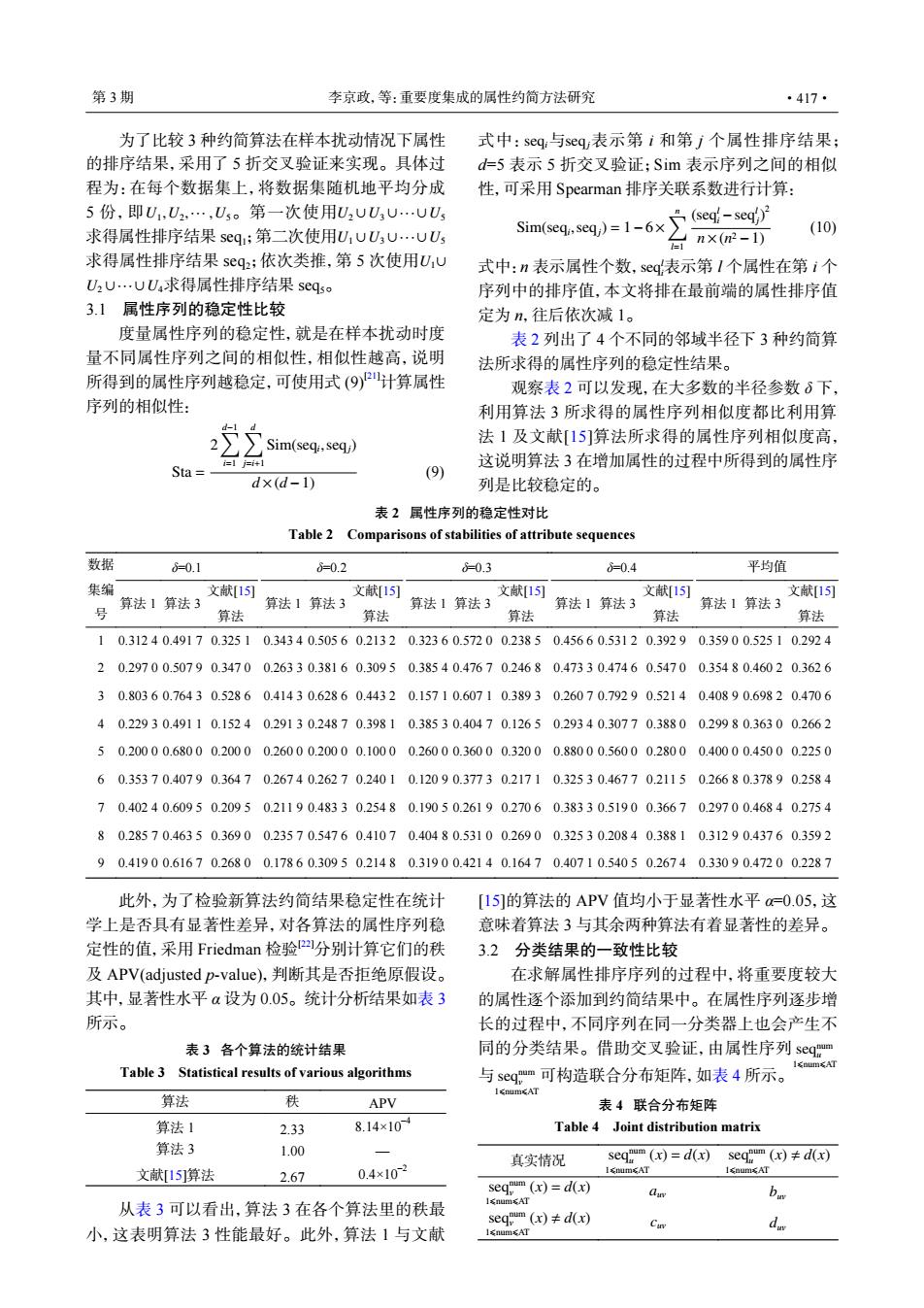
第3期 李京政,等:重要度集成的属性约简方法研究 ·417· 为了比较3种约简算法在样本扰动情况下属性 式中:seg:与seq表示第i和第j个属性排序结果; 的排序结果,采用了5折交叉验证来实现。具体过 d=5表示5折交叉验证;Sim表示序列之间的相似 程为:在每个数据集上,将数据集随机地平均分成 性,可采用Spearman排序关联系数进行计算: 5份,即U,U2…,U5。第一次使用U2UU3UUU 求得属性排序结果seq;第二次使用U1UU3U.UU Sim(sed.seq)=1-6x(sed-sedp 台n×2-1) (10) 求得属性排序结果seq2;依次类推,第5次使用U1U 式中:n表示属性个数,seq表示第I个属性在第i个 U2UUU求得属性排序结果seqso 序列中的排序值,本文将排在最前端的属性排序值 3.1 属性序列的稳定性比较 定为n,往后依次减1。 度量属性序列的稳定性,就是在样本扰动时度 表2列出了4个不同的邻域半径下3种约简算 量不同属性序列之间的相似性,相似性越高,说明 法所求得的属性序列的稳定性结果。 所得到的属性序列越稳定,可使用式(9)计算属性 观察表2可以发现,在大多数的半径参数6下, 序列的相似性: 利用算法3所求得的属性序列相似度都比利用算 -1 Sim(seq:,seq) 法1及文献[15]算法所求得的属性序列相似度高, i=l ji+1 这说明算法3在增加属性的过程中所得到的属性序 Sta= (9) d×(d-1) 列是比较稳定的。 表2属性序列的稳定性对比 Table 2 Comparisons of stabilities of attribute sequences 数据 -0.1 d=0.2 -0.3 =0.4 平均值 集编 文献[15] 文献[15] 文献15] 文献[15] 文献[15 算法1算法3 算法1算法3 算法1算法3 算法1算法3 算法1算法3 号 算法 算法 算法 算法 算法 10.31240.49170.32510.34340.50560.21320.32360.5720023850.45660.53120.39290.35900.52510.2924 20.29700.50790.34700.26330.38160.30950.38540.47670.24680.47330.47460.54700.35480.46020.3626 30.80360.76430.52860.41430.62860.44320.15710.60710.38930.26070.79290.52140.40890.69820.4706 40.22930.49110.15240.29130.24870.39810.38530.40470.12650.29340.30770.38800.29980.36300.2662 50.20000.68000.20000.26000.20000.10000.26000.36000.32000.88000.56000.28000.40000.45000.2250 60.35370.40790.36470.26740.26270.24010.12090.3773021710.32530.46770.21150.26680.37890.2584 70.40240.60950.20950.21190.48330.25480.19050.26190.27060.38330.51900.36670.29700.46840.2754 80.28570.46350.36900.23570.54760.41070.40480.53100.26900.32530.20840.38810.31290.43760.3592 90.41900.61670.26800.17860.30950.21480.31900.42140.16470.40710.54050.26740.33090.47200.2287 此外,为了检验新算法约简结果稳定性在统计 [15]的算法的APV值均小于显著性水平a=0.05,这 学上是否具有显著性差异,对各算法的属性序列稳 意味着算法3与其余两种算法有着显著性的差异。 定性的值,采用Friedman检验2分别计算它们的秩 3.2分类结果的一致性比较 及APV(adjusted p-value),判断其是否拒绝原假设。 在求解属性排序序列的过程中,将重要度较大 其中,显著性水平α设为0.05。统计分析结果如表3 的属性逐个添加到约简结果中。在属性序列逐步增 所示。 长的过程中,不同序列在同一分类器上也会产生不 表3各个算法的统计结果 同的分类结果。借助交叉验证,由属性序列seqm 1coumsAT Table 3 Statistical results of various algorithms 与seqm可构造联合分布矩阵,如表4所示。 1cnumcAT 算法 秩 APV 表4联合分布矩阵 算法1 2.33 8.14×10 Table 4 Joint distribution matrix 算法3 1.00 真实情况 seqim(x)=d(x)seqmum(x)d(x) 文献[15]算法 2.67 0.4×102 umAT aunmA灯 segmum (x)=d(x) au bw 从表3可以看出,算法3在各个算法里的秩最 seqm(x)≠dx) 小,这表明算法3性能最好。此外,算法1与文献 1snumsAT duU1,U2,··· ,U5 U2 ∪U3 ∪ ··· ∪U5 U1 ∪U3 ∪ ··· ∪U5 U1∪ U2 ∪ ··· ∪U4 为了比较 3 种约简算法在样本扰动情况下属性 的排序结果,采用了 5 折交叉验证来实现。具体过 程为:在每个数据集上,将数据集随机地平均分成 5 份,即 。第一次使用 求得属性排序结果 seq1;第二次使用 求得属性排序结果 seq2;依次类推,第 5 次使用 求得属性排序结果 seq5。 3.1 属性序列的稳定性比较 度量属性序列的稳定性,就是在样本扰动时度 量不同属性序列之间的相似性,相似性越高,说明 所得到的属性序列越稳定,可使用式 (9)[21]计算属性 序列的相似性: Sta = 2 ∑d−1 i=1 ∑d j=i+1 Sim(seqi ,seqj) d ×(d −1) (9) 式中: seqi与 seqj 表示第 i 和第 j 个属性排序结果; d=5 表示 5 折交叉验证;Sim 表示序列之间的相似 性,可采用 Spearman 排序关联系数进行计算: Sim(seqi ,seqj) = 1−6× ∑n l=1 (seql i −seql j ) 2 n×(n 2 −1) (10) seql 式中:n 表示属性个数, i表示第 l 个属性在第 i 个 序列中的排序值,本文将排在最前端的属性排序值 定为 n,往后依次减 1。 表 2 列出了 4 个不同的邻域半径下 3 种约简算 法所求得的属性序列的稳定性结果。 观察表 2 可以发现,在大多数的半径参数 δ 下, 利用算法 3 所求得的属性序列相似度都比利用算 法 1 及文献[15]算法所求得的属性序列相似度高, 这说明算法 3 在增加属性的过程中所得到的属性序 列是比较稳定的。 此外,为了检验新算法约简结果稳定性在统计 学上是否具有显著性差异,对各算法的属性序列稳 定性的值,采用 Friedman 检验[22]分别计算它们的秩 及 APV(adjusted p-value),判断其是否拒绝原假设。 其中,显著性水平 α 设为 0.05。统计分析结果如表 3 所示。 从表 3 可以看出,算法 3 在各个算法里的秩最 小,这表明算法 3 性能最好。此外,算法 1 与文献 [15]的算法的 APV 值均小于显著性水平 α=0.05,这 意味着算法 3 与其余两种算法有着显著性的差异。 3.2 分类结果的一致性比较 seqnum u 1⩽num⩽AT seqnum v 1⩽num⩽AT 在求解属性排序序列的过程中,将重要度较大 的属性逐个添加到约简结果中。在属性序列逐步增 长的过程中,不同序列在同一分类器上也会产生不 同的分类结果。借助交叉验证,由属性序列 与 可构造联合分布矩阵,如表 4 所示。 表 2 属性序列的稳定性对比 Table 2 Comparisons of stabilities of attribute sequences 数据 集编 号 δ=0.1 δ=0.2 δ=0.3 δ=0.4 平均值 算法 1 算法 3 文献[15] 算法 算法 1 算法 3 文献[15] 算法 算法 1 算法 3 文献[15] 算法 算法 1 算法 3 文献[15] 算法 算法 1 算法 3 文献[15] 算法 1 0.312 4 0.491 7 0.325 1 0.343 4 0.505 6 0.213 2 0.323 6 0.572 0 0.238 5 0.456 6 0.531 2 0.392 9 0.359 0 0.525 1 0.292 4 2 0.297 0 0.507 9 0.347 0 0.263 3 0.381 6 0.309 5 0.385 4 0.476 7 0.246 8 0.473 3 0.474 6 0.547 0 0.354 8 0.460 2 0.362 6 3 0.803 6 0.764 3 0.528 6 0.414 3 0.628 6 0.443 2 0.157 1 0.607 1 0.389 3 0.260 7 0.792 9 0.521 4 0.408 9 0.698 2 0.470 6 4 0.229 3 0.491 1 0.152 4 0.291 3 0.248 7 0.398 1 0.385 3 0.404 7 0.126 5 0.293 4 0.307 7 0.388 0 0.299 8 0.363 0 0.266 2 5 0.200 0 0.680 0 0.200 0 0.260 0 0.200 0 0.100 0 0.260 0 0.360 0 0.320 0 0.880 0 0.560 0 0.280 0 0.400 0 0.450 0 0.225 0 6 0.353 7 0.407 9 0.364 7 0.267 4 0.262 7 0.240 1 0.120 9 0.377 3 0.217 1 0.325 3 0.467 7 0.211 5 0.266 8 0.378 9 0.258 4 7 0.402 4 0.609 5 0.209 5 0.211 9 0.483 3 0.254 8 0.190 5 0.261 9 0.270 6 0.383 3 0.519 0 0.366 7 0.297 0 0.468 4 0.275 4 8 0.285 7 0.463 5 0.369 0 0.235 7 0.547 6 0.410 7 0.404 8 0.531 0 0.269 0 0.325 3 0.208 4 0.388 1 0.312 9 0.437 6 0.359 2 9 0.419 0 0.616 7 0.268 0 0.178 6 0.309 5 0.214 8 0.319 0 0.421 4 0.164 7 0.407 1 0.540 5 0.267 4 0.330 9 0.472 0 0.228 7 表 3 各个算法的统计结果 Table 3 Statistical results of various algorithms 算法 秩 APV 算法 1 2.33 8.14×10–4 算法 3 1.00 — 文献[15]算法 2.67 0.4×10–2 表 4 联合分布矩阵 Table 4 Joint distribution matrix 真实情况 seqnum u 1⩽num⩽AT (x) = d(x) seqnum u 1⩽num⩽AT (x) , d(x) seqnum v 1⩽num⩽AT (x) = d(x) auv buv seqnum v 1⩽num⩽AT (x) , d(x) cuv duv 第 3 期 李京政,等:重要度集成的属性约简方法研究 ·417·