正在加载图片...
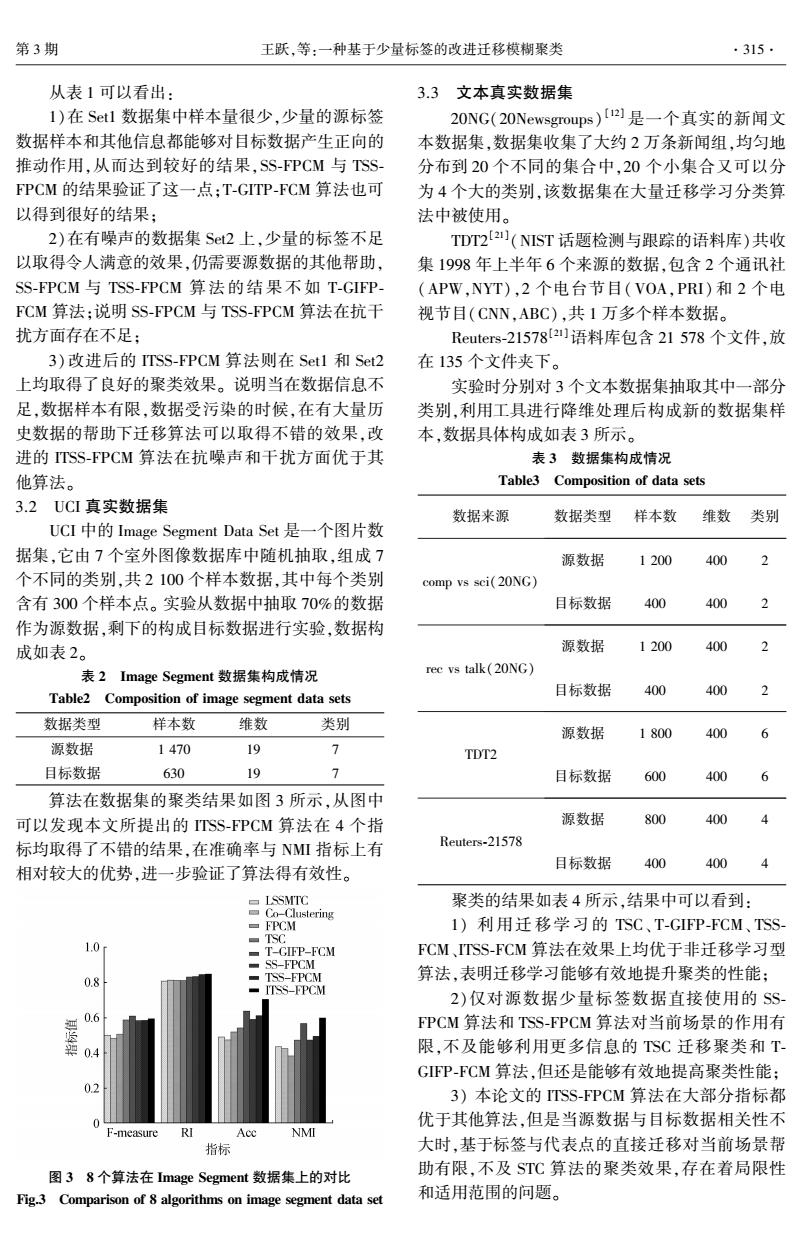
第3期 王跃,等:一种基于少量标签的改进迁移模糊聚类 ·315. 从表1可以看出: 3.3文本真实数据集 1)在St1数据集中样本量很少,少量的源标签 20NG(20 Newsgroups)【21是一个真实的新闻文 数据样本和其他信息都能够对目标数据产生正向的 本数据集,数据集收集了大约2万条新闻组,均匀地 推动作用,从而达到较好的结果,SS-FPCM与TSS- 分布到20个不同的集合中,20个小集合又可以分 FPCM的结果验证了这一点;T-GITP-FCM算法也可 为4个大的类别,该数据集在大量迁移学习分类算 以得到很好的结果; 法中被使用。 2)在有噪声的数据集St2上,少量的标签不足 TDT2[2](NIST话题检测与跟踪的语料库)共收 以取得令人满意的效果,仍需要源数据的其他帮助, 集1998年上半年6个来源的数据,包含2个通讯社 SS-FPCM与TSS-FPCM算法的结果不如T-GIFP (APW,NYT),2个电台节目(VOA,PRI)和2个电 FCM算法:说明SS-FPCM与TSS-FPCM算法在抗干 视节目(CNN,ABC),共1万多个样本数据。 扰方面存在不足: Reuters-215782)语料库包含21578个文件,放 3)改进后的ITSS-FPCM算法则在Set1和Set2 在135个文件夹下。 上均取得了良好的聚类效果。说明当在数据信息不 实验时分别对3个文本数据集抽取其中一部分 足,数据样本有限,数据受污染的时候,在有大量历 类别,利用工具进行降维处理后构成新的数据集样 史数据的帮助下迁移算法可以取得不错的效果,改 本,数据具体构成如表3所示。 进的TSS-FPCM算法在抗噪声和干扰方面优于其 表3数据集构成情况 他算法。 Table3 Composition of data sets 3.2UCI真实数据集 数据来源 数据类型 样本数 维数 类别 UCI中的Image Segment Data Set是一个图片数 据集,它由7个室外图像数据库中随机抽取,组成7 源数据 1200 400 个不同的类别,共2100个样本数据,其中每个类别 comp vs sci(20NG) 含有300个样本点。实验从数据中抽取70%的数据 目标数据 400 400 作为源数据,剩下的构成目标数据进行实验,数据构 成如表2。 源数据 1200 40 表2 Image Segment数据集构成情况 rec vs talk(20NG) Table2 Composition of image segment data sets 目标数据 400 400 数据类型 样本数 维数 类别 源数据 1800 40 源数据 1470 19 7 TDT2 目标数据 630 19 目标数据 600 40 算法在数据集的聚类结果如图3所示,从图中 可以发现本文所提出的ITSS-FPCM算法在4个指 源数据 800 400 标均取得了不错的结果,在准确率与NMI指标上有 Reuters-21578 相对较大的优势,进一步验证了算法得有效性。 目标数据 400 400 ▣LSSMT℃ 聚类的结果如表4所示,结果中可以看到: Co-Clustering ▣PCM 1)利用迁移学习的TSC、T-GIFP-FCM、TSS TSC 1.0 T-GIFP-FCM FCM、TSS-FCM算法在效果上均优于非迁移学习型 SS-FPCM ■TSS-FPCM 算法,表明迁移学习能够有效地提升聚类的性能; ITSS-FPCM 2)仅对源数据少量标签数据直接使用的SS 0.6 FPCM算法和TSS-FPCM算法对当前场景的作用有 0.4 限,不及能够利用更多信息的TSC迁移聚类和T GIFP-FCM算法,但还是能够有效地提高聚类性能; 0.2 3)本论文的TSS-FPCM算法在大部分指标都 0 优于其他算法,但是当源数据与目标数据相关性不 F-measure RI NMI 指标 大时,基于标签与代表点的直接迁移对当前场景帮 图38个算法在Image Segment数据集上的对比 助有限,不及ST℃算法的聚类效果,存在着局限性 Fig.3 Comparison of 8 algorithms on image segment data set 和适用范围的问题。从表 1 可以看出: 1)在 Set1 数据集中样本量很少,少量的源标签 数据样本和其他信息都能够对目标数据产生正向的 推动作用,从而达到较好的结果,SS⁃FPCM 与 TSS⁃ FPCM 的结果验证了这一点;T⁃GITP⁃FCM 算法也可 以得到很好的结果; 2)在有噪声的数据集 Set2 上,少量的标签不足 以取得令人满意的效果,仍需要源数据的其他帮助, SS⁃FPCM 与 TSS⁃FPCM 算法的结果不如 T⁃GIFP⁃ FCM 算法;说明 SS⁃FPCM 与 TSS⁃FPCM 算法在抗干 扰方面存在不足; 3)改进后的 ITSS⁃FPCM 算法则在 Set1 和 Set2 上均取得了良好的聚类效果。 说明当在数据信息不 足,数据样本有限,数据受污染的时候,在有大量历 史数据的帮助下迁移算法可以取得不错的效果,改 进的 ITSS⁃FPCM 算法在抗噪声和干扰方面优于其 他算法。 3.2 UCI 真实数据集 UCI 中的 Image Segment Data Set 是一个图片数 据集,它由 7 个室外图像数据库中随机抽取,组成 7 个不同的类别,共 2 100 个样本数据,其中每个类别 含有 300 个样本点。 实验从数据中抽取 70%的数据 作为源数据,剩下的构成目标数据进行实验,数据构 成如表 2。 表 2 Image Segment 数据集构成情况 Table2 Composition of image segment data sets 数据类型 样本数 维数 类别 源数据 1 470 19 7 目标数据 630 19 7 算法在数据集的聚类结果如图 3 所示,从图中 可以发现本文所提出的 ITSS⁃FPCM 算法在 4 个指 标均取得了不错的结果,在准确率与 NMI 指标上有 相对较大的优势,进一步验证了算法得有效性。 图 3 8 个算法在 Image Segment 数据集上的对比 Fig.3 Comparison of 8 algorithms on image segment data set 3.3 文本真实数据集 20NG(20Newsgroups) [12] 是一个真实的新闻文 本数据集,数据集收集了大约 2 万条新闻组,均匀地 分布到 20 个不同的集合中,20 个小集合又可以分 为 4 个大的类别,该数据集在大量迁移学习分类算 法中被使用。 TDT2 [21] (NIST 话题检测与跟踪的语料库)共收 集 1998 年上半年 6 个来源的数据,包含 2 个通讯社 (APW,NYT),2 个电台节目(VOA,PRI) 和 2 个电 视节目(CNN,ABC),共 1 万多个样本数据。 Reuters⁃21578 [21]语料库包含 21 578 个文件,放 在 135 个文件夹下。 实验时分别对 3 个文本数据集抽取其中一部分 类别,利用工具进行降维处理后构成新的数据集样 本,数据具体构成如表 3 所示。 表 3 数据集构成情况 Table3 Composition of data sets 数据来源 数据类型 样本数 维数 类别 comp vs sci(20NG) 源数据 1 200 400 2 目标数据 400 400 2 rec vs talk(20NG) 源数据 1 200 400 2 目标数据 400 400 2 TDT2 源数据 1 800 400 6 目标数据 600 400 6 Reuters⁃21578 源数据 800 400 4 目标数据 400 400 4 聚类的结果如表 4 所示,结果中可以看到: 1) 利用迁移学习的 TSC、 T⁃GIFP⁃FCM、 TSS⁃ FCM、ITSS⁃FCM 算法在效果上均优于非迁移学习型 算法,表明迁移学习能够有效地提升聚类的性能; 2)仅对源数据少量标签数据直接使用的 SS⁃ FPCM 算法和 TSS⁃FPCM 算法对当前场景的作用有 限,不及能够利用更多信息的 TSC 迁移聚类和 T⁃ GIFP⁃FCM 算法,但还是能够有效地提高聚类性能; 3) 本论文的 ITSS⁃FPCM 算法在大部分指标都 优于其他算法,但是当源数据与目标数据相关性不 大时,基于标签与代表点的直接迁移对当前场景帮 助有限,不及 STC 算法的聚类效果,存在着局限性 和适用范围的问题。 第 3 期 王跃,等:一种基于少量标签的改进迁移模糊聚类 ·315·