正在加载图片...
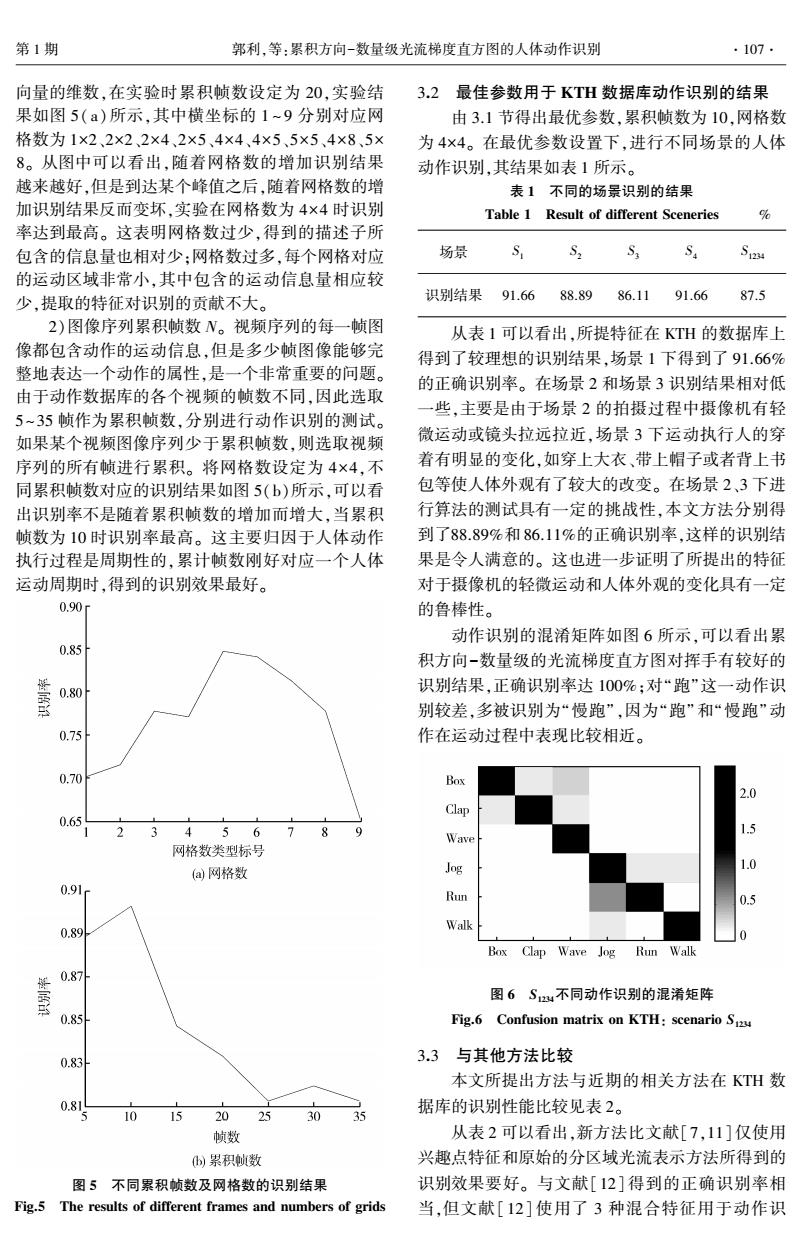
第1期 郭利,等:累积方向-数量级光流梯度直方图的人体动作识别 ·107. 向量的维数,在实验时累积帧数设定为20,实验结 3.2最佳参数用于KTH数据库动作识别的结果 果如图5(a)所示,其中横坐标的1~9分别对应网 由3.1节得出最优参数,累积帧数为10,网格数 格数为1×2、2×2、2×4、2×5、4×4、4×5、5×5、4×8、5× 为4×4。在最优参数设置下,进行不同场景的人体 8。从图中可以看出,随着网格数的增加识别结果 动作识别,其结果如表1所示。 越来越好,但是到达某个峰值之后,随着网格数的增 表1不同的场景识别的结果 加识别结果反而变坏,实验在网格数为4×4时识别 Table 1 Result of different Sceneries % 率达到最高。这表明网格数过少,得到的描述子所 包含的信息量也相对少;网格数过多,每个网格对应 场景 S S2 S S 的运动区域非常小,其中包含的运动信息量相应较 少,提取的特征对识别的贡献不大。 识别结果 91.66 88.89 86.11 91.66 87.5 2)图像序列累积帧数N。视频序列的每一帧图 从表1可以看出,所提特征在KTH的数据库上 像都包含动作的运动信息,但是多少帧图像能够完 得到了较理想的识别结果,场景1下得到了91.66% 整地表达一个动作的属性,是一个非常重要的问题。 的正确识别率。在场景2和场景3识别结果相对低 由于动作数据库的各个视频的帧数不同,因此选取 一些,主要是由于场景2的拍摄过程中摄像机有轻 5~35帧作为累积帧数,分别进行动作识别的测试。 如果某个视频图像序列少于累积帧数,则选取视频 微运动或镜头拉远拉近,场景3下运动执行人的穿 序列的所有帧进行累积。将网格数设定为4×4,不 着有明显的变化,如穿上大衣、带上帽子或者背上书 同累积帧数对应的识别结果如图5(b)所示,可以看 包等使人体外观有了较大的改变。在场景2、3下进 出识别率不是随着累积帧数的增加而增大,当累积 行算法的测试具有一定的挑战性,本文方法分别得 帧数为10时识别率最高。这主要归因于人体动作 到了88.89%和86.11%的正确识别率,这样的识别结 执行过程是周期性的,累计帧数刚好对应一个人体 果是令人满意的。这也进一步证明了所提出的特征 运动周期时,得到的识别效果最好。 对于摄像机的轻微运动和人体外观的变化具有一定 0.90 的鲁棒性。 动作识别的混淆矩阵如图6所示,可以看出累 0.85 积方向-数量级的光流梯度直方图对挥手有较好的 0.80 识别结果,正确识别率达100%:对“跑”这一动作识 书 别较差,多被识别为“慢跑”,因为“跑”和“慢跑”动 0.75 作在运动过程中表现比较相近。 0.70 Box 2.0 Clap 0.65 4567 Wave 网格数类型标号 1.0 (a网格数 Jog 0.91 Run 0.5 Walk 0.89 0 Box Clap Wave Jog Run Walk 0.871 图6S12u不同动作识别的混淆矩阵 0.85 Fig.6 Confusion matrix on KTH:scenario S 0.83H 3.3与其他方法比较 本文所提出方法与近期的相关方法在KTH数 0.8 5 0 据库的识别性能比较见表2。 15 2025 30 35 帧数 从表2可以看出,新方法比文献[7,11]仅使用 )累积帧数 兴趣点特征和原始的分区域光流表示方法所得到的 图5不同累积帧数及网格数的识别结果 识别效果要好。与文献[12]得到的正确识别率相 Fig.5 The results of different frames and numbers of grids 当,但文献[12]使用了3种混合特征用于动作识向量的维数,在实验时累积帧数设定为 20,实验结 果如图 5( a)所示,其中横坐标的 1 ~ 9 分别对应网 格数为 1×2、2×2、2×4、2×5、4×4、4×5、5×5、4×8、5× 8。 从图中可以看出,随着网格数的增加识别结果 越来越好,但是到达某个峰值之后,随着网格数的增 加识别结果反而变坏,实验在网格数为 4×4 时识别 率达到最高。 这表明网格数过少,得到的描述子所 包含的信息量也相对少;网格数过多,每个网格对应 的运动区域非常小,其中包含的运动信息量相应较 少,提取的特征对识别的贡献不大。 2)图像序列累积帧数 N。 视频序列的每一帧图 像都包含动作的运动信息,但是多少帧图像能够完 整地表达一个动作的属性,是一个非常重要的问题。 由于动作数据库的各个视频的帧数不同,因此选取 5~35 帧作为累积帧数,分别进行动作识别的测试。 如果某个视频图像序列少于累积帧数,则选取视频 序列的所有帧进行累积。 将网格数设定为 4×4,不 同累积帧数对应的识别结果如图 5(b)所示,可以看 出识别率不是随着累积帧数的增加而增大,当累积 帧数为 10 时识别率最高。 这主要归因于人体动作 执行过程是周期性的,累计帧数刚好对应一个人体 运动周期时,得到的识别效果最好。 图 5 不同累积帧数及网格数的识别结果 Fig.5 The results of different frames and numbers of grids 3.2 最佳参数用于 KTH 数据库动作识别的结果 由 3.1 节得出最优参数,累积帧数为 10,网格数 为 4×4。 在最优参数设置下,进行不同场景的人体 动作识别,其结果如表 1 所示。 表 1 不同的场景识别的结果 Table 1 Result of different Sceneries % 场景 S1 S2 S3 S4 S1234 识别结果 91.66 88.89 86.11 91.66 87.5 从表 1 可以看出,所提特征在 KTH 的数据库上 得到了较理想的识别结果,场景 1 下得到了 91.66% 的正确识别率。 在场景 2 和场景 3 识别结果相对低 一些,主要是由于场景 2 的拍摄过程中摄像机有轻 微运动或镜头拉远拉近,场景 3 下运动执行人的穿 着有明显的变化,如穿上大衣、带上帽子或者背上书 包等使人体外观有了较大的改变。 在场景 2、3 下进 行算法的测试具有一定的挑战性,本文方法分别得 到了88.89%和 86.11%的正确识别率,这样的识别结 果是令人满意的。 这也进一步证明了所提出的特征 对于摄像机的轻微运动和人体外观的变化具有一定 的鲁棒性。 动作识别的混淆矩阵如图 6 所示,可以看出累 积方向-数量级的光流梯度直方图对挥手有较好的 识别结果,正确识别率达 100%;对“跑”这一动作识 别较差,多被识别为“慢跑”,因为“跑”和“慢跑”动 作在运动过程中表现比较相近。 图 6 S1234不同动作识别的混淆矩阵 Fig.6 Confusion matrix on KTH: scenario S1234 3.3 与其他方法比较 本文所提出方法与近期的相关方法在 KTH 数 据库的识别性能比较见表 2。 从表 2 可以看出,新方法比文献[7,11]仅使用 兴趣点特征和原始的分区域光流表示方法所得到的 识别效果要好。 与文献[12] 得到的正确识别率相 当,但文献[12] 使用了 3 种混合特征用于动作识 第 1 期 郭利,等:累积方向-数量级光流梯度直方图的人体动作识别 ·107·