正在加载图片...
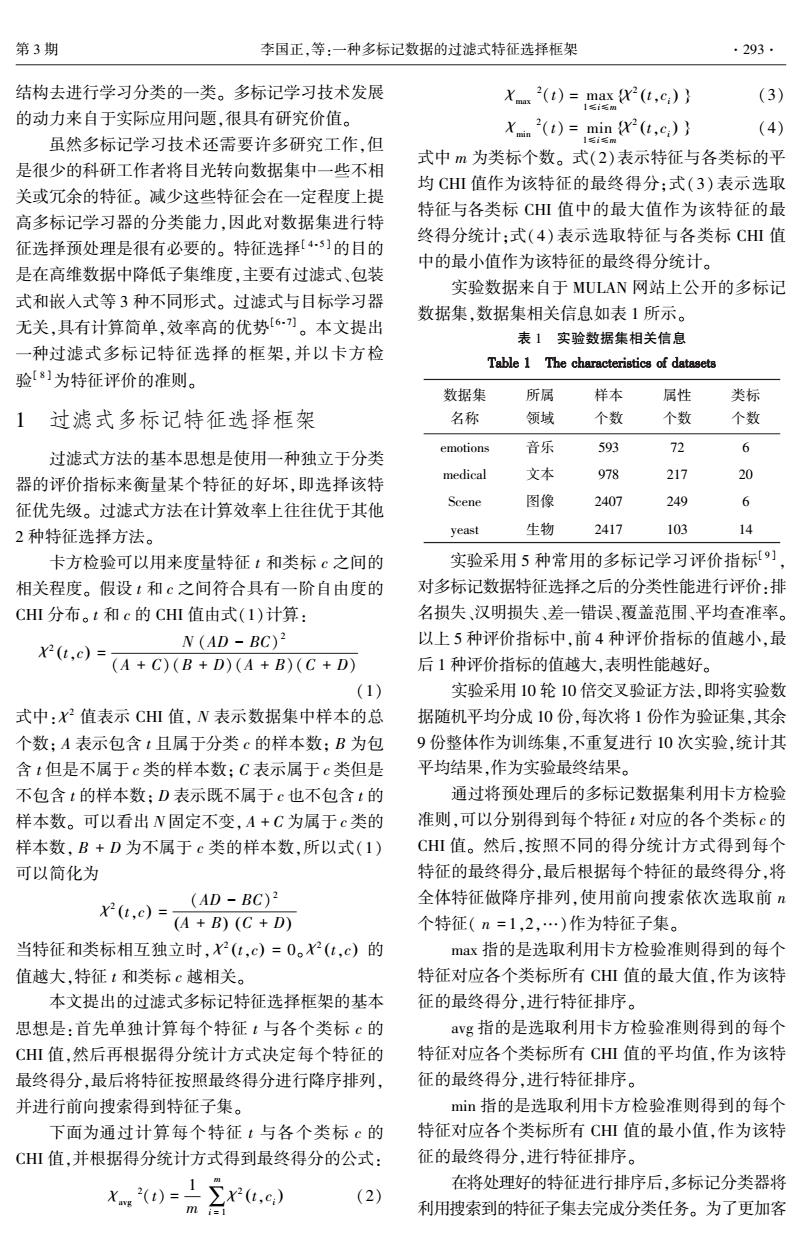
第3期 李国正,等:一种多标记数据的过滤式特征选择框架 ·293. 结构去进行学习分类的一类。多标记学习技术发展 X(t)=max (t,c:)) (3) 】安多 的动力来自于实际应用问题,很具有研究价值。 X(t)=min (t.c)) (4) 虽然多标记学习技术还需要许多研究工作,但 1名i名m 式中m为类标个数。式(2)表示特征与各类标的平 是很少的科研工作者将目光转向数据集中一些不相 均CHⅢ值作为该特征的最终得分:式(3)表示选取 关或冗余的特征。减少这些特征会在一定程度上提 特征与各类标CHⅢ值中的最大值作为该特征的最 高多标记学习器的分类能力,因此对数据集进行特 终得分统计;式(4)表示选取特征与各类标CHⅢ值 征选择预处理是很有必要的。特征选择[45]的目的 中的最小值作为该特征的最终得分统计。 是在高维数据中降低子集维度,主要有过滤式、包装 实验数据来自于MULAN网站上公开的多标记 式和嵌入式等3种不同形式。过滤式与目标学习器 无关,具有计算简单,效率高的优势[6)。本文提出 数据集,数据集相关信息如表1所示。 表1实验数据集相关信息 一种过滤式多标记特征选择的框架,并以卡方检 Table 1 The characteristics of datasets 验8]为特征评价的准则。 数据集 所属 样本 属性 类标 1过滤式多标记特征选择框架 名称 领域 个数 个数 个数 emotions 过滤式方法的基本思想是使用一种独立于分类 音乐 593 72 6 medical 文本 978 217 20 器的评价指标来衡量某个特征的好坏,即选择该特 2407 249 征优先级。过滤式方法在计算效率上往往优于其他 Scene 图像 6 2种特征选择方法。 yeast 生物 2417 103 14 卡方检验可以用来度量特征t和类标c之间的 实验采用5种常用的多标记学习评价指标[9] 相关程度。假设t和c之间符合具有一阶自由度的 对多标记数据特征选择之后的分类性能进行评价:排 CHI分布。t和c的CHI值由式(1)计算: 名损失、汉明损失、差一错误、覆盖范围、平均查准率。 N (AD-BC)2 以上5种评价指标中,前4种评价指标的值越小,最 X(,c)=A+C)(B+D)(A+B)(C+D) 后1种评价指标的值越大,表明性能越好。 (1) 实验采用10轮10倍交叉验证方法,即将实验数 式中:X2值表示CHI值,N表示数据集中样本的总 据随机平均分成10份,每次将1份作为验证集,其余 个数:A表示包含t且属于分类c的样本数:B为包 9份整体作为训练集,不重复进行10次实验,统计其 含t但是不属于c类的样本数:C表示属于c类但是 平均结果,作为实验最终结果。 不包含t的样本数:D表示既不属于c也不包含t的 通过将预处理后的多标记数据集利用卡方检验 样本数。可以看出N固定不变,A+C为属于c类的 准则,可以分别得到每个特征t对应的各个类标c的 样本数,B+D为不属于c类的样本数,所以式(1) CHⅢ值。然后,按照不同的得分统计方式得到每个 可以简化为 特征的最终得分,最后根据每个特征的最终得分,将 acm 全体特征做降序排列,使用前向搜索依次选取前 个特征(n=1,2,…)作为特征子集。 当特征和类标相互独立时,(t,c)=0。(t,c)的 max指的是选取利用卡方检验准则得到的每个 值越大,特征1和类标c越相关。 特征对应各个类标所有CHI值的最大值,作为该特 本文提出的过滤式多标记特征选择框架的基本 征的最终得分,进行特征排序。 思想是:首先单独计算每个特征t与各个类标c的 avg指的是选取利用卡方检验准则得到的每个 CH值,然后再根据得分统计方式决定每个特征的 特征对应各个类标所有CHⅢ值的平均值,作为该特 最终得分,最后将特征按照最终得分进行降序排列, 征的最终得分,进行特征排序。 并进行前向搜索得到特征子集。 min指的是选取利用卡方检验准则得到的每个 下面为通过计算每个特征t与各个类标c的 特征对应各个类标所有CHⅢ值的最小值,作为该特 CHⅢ值,并根据得分统计方式得到最终得分的公式: 征的最终得分,进行特征排序。 X2()=∑x6,c) 在将处理好的特征进行排序后,多标记分类器将 2 m 利用搜索到的特征子集去完成分类任务。为了更加客结构去进行学习分类的一类。 多标记学习技术发展 的动力来自于实际应用问题,很具有研究价值。 虽然多标记学习技术还需要许多研究工作,但 是很少的科研工作者将目光转向数据集中一些不相 关或冗余的特征。 减少这些特征会在一定程度上提 高多标记学习器的分类能力,因此对数据集进行特 征选择预处理是很有必要的。 特征选择[ 4 ⁃ 5 ]的目的 是在高维数据中降低子集维度,主要有过滤式、包装 式和嵌入式等 3 种不同形式。 过滤式与目标学习器 无关,具有计算简单,效率高的优势[6 ⁃ 7] 。 本文提出 一种过滤式多标记特征选择的框架,并以卡方检 验[ 8 ]为特征评价的准则。 1 过滤式多标记特征选择框架 过滤式方法的基本思想是使用一种独立于分类 器的评价指标来衡量某个特征的好坏,即选择该特 征优先级。 过滤式方法在计算效率上往往优于其他 2 种特征选择方法。 卡方检验可以用来度量特征 t 和类标 c 之间的 相关程度。 假设 t 和 c 之间符合具有一阶自由度的 CHI 分布。 t 和 c 的 CHI 值由式(1)计算: χ 2 (t,c) = N (AD - BC) 2 (A + C)(B + D)(A + B)(C + D) (1) 式中: χ 2 值表示 CHI 值, N 表示数据集中样本的总 个数; A 表示包含 t 且属于分类 c 的样本数; B 为包 含 t 但是不属于 c 类的样本数; C 表示属于 c 类但是 不包含 t 的样本数; D 表示既不属于 c 也不包含 t 的 样本数。 可以看出 N 固定不变, A + C 为属于 c 类的 样本数, B + D 为不属于 c 类的样本数,所以式(1) 可以简化为 χ 2 (t,c) = (AD - BC) 2 (A + B) (C + D) 当特征和类标相互独立时, χ 2 (t,c) = 0。 χ 2 (t,c) 的 值越大,特征 t 和类标 c 越相关。 本文提出的过滤式多标记特征选择框架的基本 思想是:首先单独计算每个特征 t 与各个类标 c 的 CHI 值,然后再根据得分统计方式决定每个特征的 最终得分,最后将特征按照最终得分进行降序排列, 并进行前向搜索得到特征子集。 下面为通过计算每个特征 t 与各个类标 c 的 CHI 值,并根据得分统计方式得到最终得分的公式: χ avg 2 (t) = 1 m ∑ m i = 1 χ 2 t,ci ( ) (2) χ max 2 (t) = max 1≤i≤m χ 2 t,ci { ( ) } (3) χ min 2 (t) = min 1≤i≤m χ 2 t,ci { ( ) } (4) 式中 m 为类标个数。 式(2)表示特征与各类标的平 均 CHI 值作为该特征的最终得分;式(3)表示选取 特征与各类标 CHI 值中的最大值作为该特征的最 终得分统计;式(4)表示选取特征与各类标 CHI 值 中的最小值作为该特征的最终得分统计。 实验数据来自于 MULAN 网站上公开的多标记 数据集,数据集相关信息如表 1 所示。 表 1 实验数据集相关信息 Table 1 The characteristics of datasets 数据集 名称 所属 领域 样本 个数 属性 个数 类标 个数 emotions 音乐 593 72 6 medical 文本 978 217 20 Scene 图像 2407 249 6 yeast 生物 2417 103 14 实验采用 5 种常用的多标记学习评价指标[ 9 ] , 对多标记数据特征选择之后的分类性能进行评价:排 名损失、汉明损失、差一错误、覆盖范围、平均查准率。 以上 5 种评价指标中,前 4 种评价指标的值越小,最 后 1 种评价指标的值越大,表明性能越好。 实验采用 10 轮 10 倍交叉验证方法,即将实验数 据随机平均分成 10 份,每次将 1 份作为验证集,其余 9 份整体作为训练集,不重复进行 10 次实验,统计其 平均结果,作为实验最终结果。 通过将预处理后的多标记数据集利用卡方检验 准则,可以分别得到每个特征 t 对应的各个类标 c 的 CHI 值。 然后,按照不同的得分统计方式得到每个 特征的最终得分,最后根据每个特征的最终得分,将 全体特征做降序排列,使用前向搜索依次选取前 n 个特征( n = 1,2,…)作为特征子集。 max 指的是选取利用卡方检验准则得到的每个 特征对应各个类标所有 CHI 值的最大值,作为该特 征的最终得分,进行特征排序。 avg 指的是选取利用卡方检验准则得到的每个 特征对应各个类标所有 CHI 值的平均值,作为该特 征的最终得分,进行特征排序。 min 指的是选取利用卡方检验准则得到的每个 特征对应各个类标所有 CHI 值的最小值,作为该特 征的最终得分,进行特征排序。 在将处理好的特征进行排序后,多标记分类器将 利用搜索到的特征子集去完成分类任务。 为了更加客 第 3 期 李国正,等:一种多标记数据的过滤式特征选择框架 ·293·