正在加载图片...
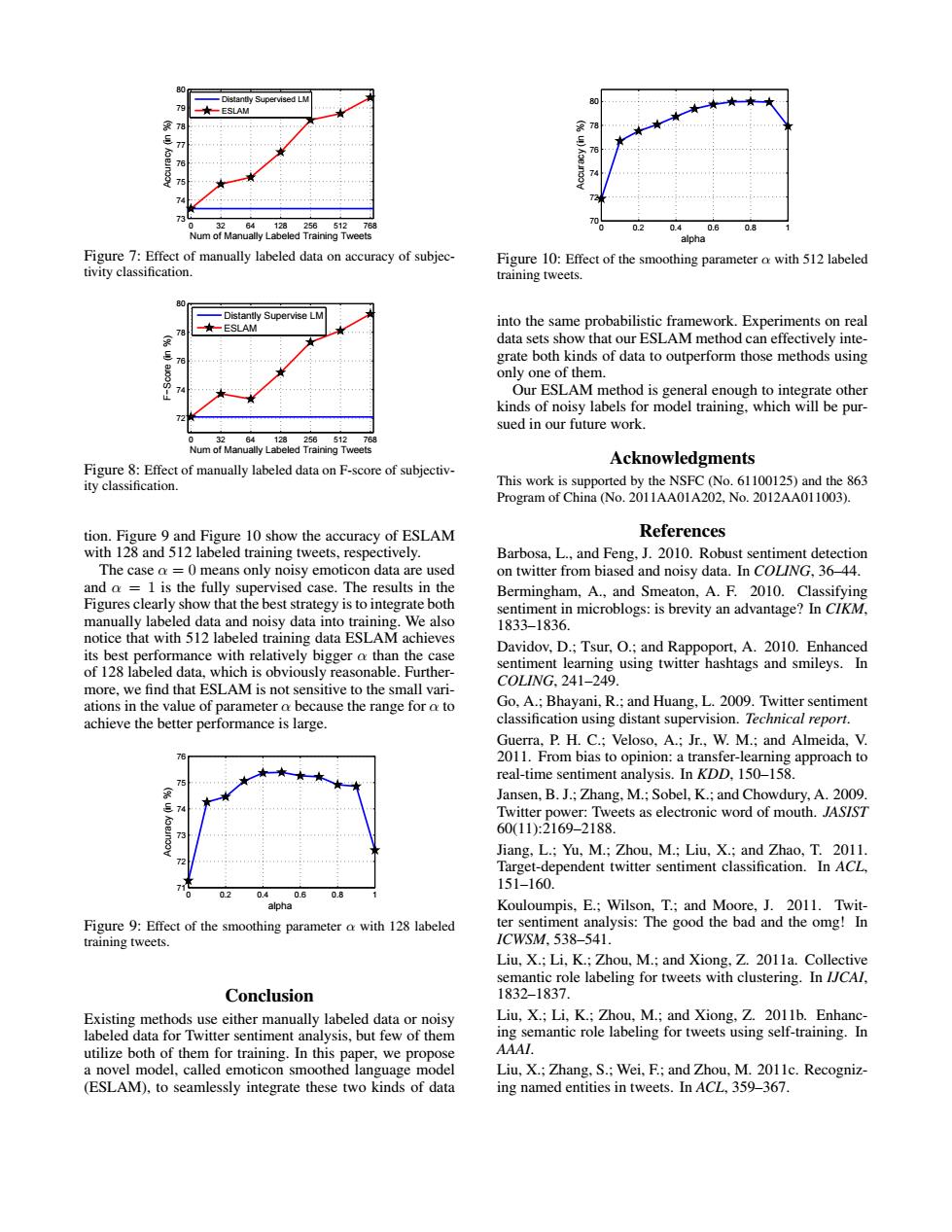
-Distantly Supervised LM 79 -ESLAM 7 2 64 12825651276 0.2 0.4 0.6 0.8 Num of Manually Labeled Training Tweets alpha Figure 7:Effect of manually labeled data on accuracy of subjec- Figure 10:Effect of the smoothing parameter a with 512 labeled tivity classification. training tweets. 80 -Distantly Supervise LM ★-ESLAM into the same probabilistic framework.Experiments on real data sets show that our ESLAM method can effectively inte- grate both kinds of data to outperform those methods using only one of them 19 Our ESLAM method is general enough to integrate other kinds of noisy labels for model training,which will be pur- sued in our future work. Num Figure 8:Effect of manually labeled data on F-score of subjectiv- Acknowledgments ity classification. This work is supported by the NSFC (No.61100125)and the 863 Program of China (No.2011AA01A202.No.2012AA011003). tion.Figure 9 and Figure 10 show the accuracy of ESLAM References with 128 and 512 labeled training tweets,respectively. Barbosa,L.,and Feng,J.2010.Robust sentiment detection The case a =0 means only noisy emoticon data are used on twitter from biased and noisy data.In COLING,36-44. and a =1 is the fully supervised case.The results in the Bermingham,A.,and Smeaton,A.F.2010.Classifying Figures clearly show that the best strategy is to integrate both sentiment in microblogs:is brevity an advantage?In CIKM, manually labeled data and noisy data into training.We also 1833-1836. notice that with 512 labeled training data ESLAM achieves its best performance with relatively bigger o than the case Davidov,D.;Tsur,O.;and Rappoport,A.2010.Enhanced of 128 labeled data,which is obviously reasonable.Further- sentiment learning using twitter hashtags and smileys.In C0LNG.241-249. more,we find that ESLAM is not sensitive to the small vari- ations in the value of parameter o because the range for o to Go,A.;Bhayani,R.;and Huang,L.2009.Twitter sentiment achieve the better performance is large. classification using distant supervision.Technical report. Guerra,P.H.C.;Veloso,A.;Jr.,W.M.;and Almeida,V. 2011.From bias to opinion:a transfer-learning approach to real-time sentiment analysis.In KDD,150-158. Jansen,B.J.;Zhang,M.;Sobel,K.;and Chowdury,A.2009. Twitter power:Tweets as electronic word of mouth.JASIST 60(11):2169-2188 Jiang,L.;Yu,M.;Zhou,M.;Liu,X.;and Zhao,T.2011. Target-dependent twitter sentiment classification.In ACL, 151-160. 02 0.4 06 0.8 alpha Kouloumpis,E.;Wilson,T.;and Moore,J.2011.Twit- Figure 9:Effect of the smoothing parameter a with 128 labeled ter sentiment analysis:The good the bad and the omg!In training tweets. ICWSM.538-541. Liu,X.;Li,K.;Zhou,M.;and Xiong,Z.2011a.Collective semantic role labeling for tweets with clustering.In I/CAl, Conclusion 1832-1837. Existing methods use either manually labeled data or noisy Liu,X.;Li,K.;Zhou,M.;and Xiong,Z.2011b.Enhanc- labeled data for Twitter sentiment analysis,but few of them ing semantic role labeling for tweets using self-training.In utilize both of them for training.In this paper,we propose AAA/. a novel model,called emoticon smoothed language model Liu,X.;Zhang,S.;Wei,F.;and Zhou,M.2011c.Recogniz- (ESLAM),to seamlessly integrate these two kinds of data ing named entities in tweets.In ACL,359-367.0 32 64 128 256 512 768 73 74 75 76 77 78 79 80 Num of Manually Labeled Training Tweets Accuracy (in %) Distantly Supervised LM ESLAM Figure 7: Effect of manually labeled data on accuracy of subjectivity classification. 0 32 64 128 256 512 768 72 74 76 78 80 Num of Manually Labeled Training Tweets F−Score (in %) Distantly Supervise LM ESLAM Figure 8: Effect of manually labeled data on F-score of subjectivity classification. tion. Figure 9 and Figure 10 show the accuracy of ESLAM with 128 and 512 labeled training tweets, respectively. The case α = 0 means only noisy emoticon data are used and α = 1 is the fully supervised case. The results in the Figures clearly show that the best strategy is to integrate both manually labeled data and noisy data into training. We also notice that with 512 labeled training data ESLAM achieves its best performance with relatively bigger α than the case of 128 labeled data, which is obviously reasonable. Furthermore, we find that ESLAM is not sensitive to the small variations in the value of parameter α because the range for α to achieve the better performance is large. 0 0.2 0.4 0.6 0.8 1 71 72 73 74 75 76 alpha Accuracy (in %) Figure 9: Effect of the smoothing parameter α with 128 labeled training tweets. Conclusion Existing methods use either manually labeled data or noisy labeled data for Twitter sentiment analysis, but few of them utilize both of them for training. In this paper, we propose a novel model, called emoticon smoothed language model (ESLAM), to seamlessly integrate these two kinds of data 0 0.2 0.4 0.6 0.8 1 70 72 74 76 78 80 alpha Accuracy (in %) Figure 10: Effect of the smoothing parameter α with 512 labeled training tweets. into the same probabilistic framework. Experiments on real data sets show that our ESLAM method can effectively integrate both kinds of data to outperform those methods using only one of them. Our ESLAM method is general enough to integrate other kinds of noisy labels for model training, which will be pursued in our future work. Acknowledgments This work is supported by the NSFC (No. 61100125) and the 863 Program of China (No. 2011AA01A202, No. 2012AA011003). References Barbosa, L., and Feng, J. 2010. Robust sentiment detection on twitter from biased and noisy data. In COLING, 36–44. Bermingham, A., and Smeaton, A. F. 2010. Classifying sentiment in microblogs: is brevity an advantage? In CIKM, 1833–1836. Davidov, D.; Tsur, O.; and Rappoport, A. 2010. Enhanced sentiment learning using twitter hashtags and smileys. In COLING, 241–249. Go, A.; Bhayani, R.; and Huang, L. 2009. Twitter sentiment classification using distant supervision. Technical report. Guerra, P. H. C.; Veloso, A.; Jr., W. M.; and Almeida, V. 2011. From bias to opinion: a transfer-learning approach to real-time sentiment analysis. In KDD, 150–158. Jansen, B. J.; Zhang, M.; Sobel, K.; and Chowdury, A. 2009. Twitter power: Tweets as electronic word of mouth. JASIST 60(11):2169–2188. Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; and Zhao, T. 2011. Target-dependent twitter sentiment classification. In ACL, 151–160. Kouloumpis, E.; Wilson, T.; and Moore, J. 2011. Twitter sentiment analysis: The good the bad and the omg! In ICWSM, 538–541. Liu, X.; Li, K.; Zhou, M.; and Xiong, Z. 2011a. Collective semantic role labeling for tweets with clustering. In IJCAI, 1832–1837. Liu, X.; Li, K.; Zhou, M.; and Xiong, Z. 2011b. Enhancing semantic role labeling for tweets using self-training. In AAAI. Liu, X.; Zhang, S.; Wei, F.; and Zhou, M. 2011c. Recognizing named entities in tweets. In ACL, 359–367