正在加载图片...
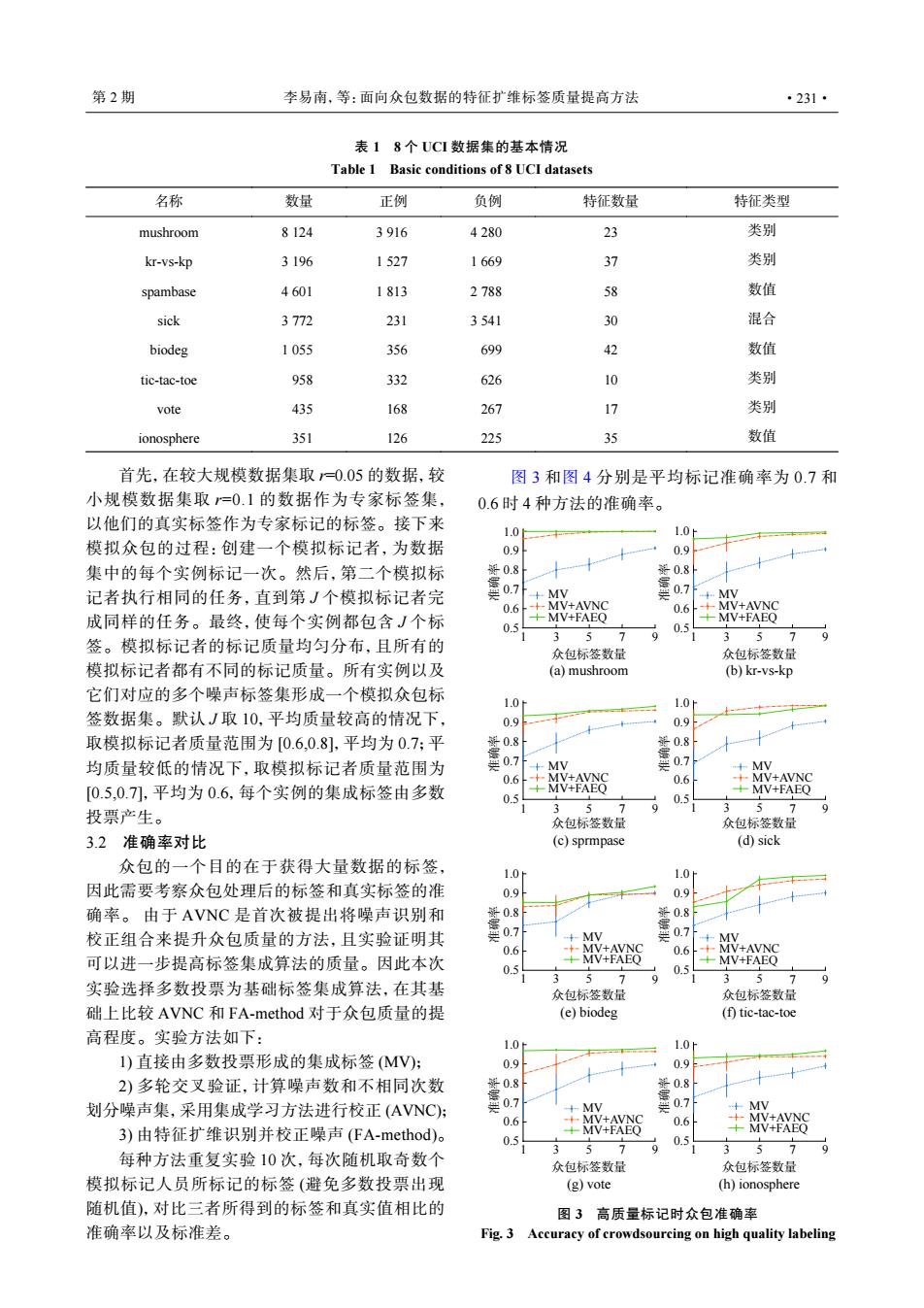
第2期 李易南,等:面向众包数据的特征扩维标签质量提高方法 ·231· 表18个UCI数据集的基本情况 Table 1 Basic conditions of 8 UCI datasets 名称 数量 正例 负例 特征数量 特征类型 mushroom 8124 3916 4280 23 类别 kr-vs-kp 3196 1527 1669 37 类别 spambase 4601 1813 2788 58 数值 sick 3772 231 3541 30 混合 biodeg 1055 356 699 42 数值 tic-tac-toe 958 332 626 10 类别 vote 435 168 267 17 类别 ionosphere 351 126 225 35 数值 首先,在较大规模数据集取=0.05的数据,较 图3和图4分别是平均标记准确率为0.7和 小规模数据集取=0.1的数据作为专家标签集, 0.6时4种方法的准确率。 以他们的真实标签作为专家标记的标签。接下来 1.0 1.0 模拟众包的过程:创建一个模拟标记者,为数据 0.9 0.9 集中的每个实例标记一次。然后,第二个模拟标 解0.8 能0.8 记者执行相同的任务,直到第J个模拟标记者完 毫o7+8 4MV 0.6+MV+AVNC 0.6+MV+AVNC 成同样的任务。最终,使每个实例都包含J个标 MV+FAEQ MV+FAEQ 0.5 3 5 7 9 0.5 3 5 7 签。模拟标记者的标记质量均匀分布,且所有的 众包标签数量 众包标签数量 模拟标记者都有不同的标记质量。所有实例以及 (a)mushroom (b)kr-vs-kp 它们对应的多个噪声标签集形成一个模拟众包标 1.0h 1.0f 签数据集。默认J取10,平均质量较高的情况下, 0.9 0.9 取模拟标记者质量范围为[0.6,0.8],平均为0.7;平 每0.8 00.8 均质量较低的情况下,取模拟标记者质量范围为 是07 是07 0.6 MV+AVNC [0.5,0.7],平均为0.6,每个实例的集成标签由多数 MV+FAEQ .6 AC MV+FAEQ 0.5 0.5 1 7 3 5 投票产生。 3 5 9 9 众包标签数量 众包标签数量 3.2准确率对比 (c)sprmpase (d)sick 众包的一个目的在于获得大量数据的标签, 1.0h 1.0h 因此需要考察众包处理后的标签和真实标签的准 0.9 0.9 确率。由于AVNC是首次被提出将噪声识别和 校正组合来提升众包质量的方法,且实验证明其 +MV +MV 0.6 -+-MV+AVNC 0.6+MV+AVNC 可以进一步提高标签集成算法的质量。因此本次 MV+FAEQ MV+FAEO 0.5 w2 0.5 9 3 5 实验选择多数投票为基础标签集成算法,在其基 众包标签数量 众包标签数量 础上比较AVNC和FA-method对于众包质量的提 (e)biodeg (f)tic-tac-toe 高程度。实验方法如下: 1.0 1.0h 1)直接由多数投票形成的集成标签(MV): 0.9 0.9 2)多轮交叉验证,计算噪声数和不相同次数 划分噪声集,采用集成学习方法进行校正(AVNC): 0.7 MV 07 +MV 0.6 MV+AVNC 0.6 MV+AVNC 3)由特征扩维识别并校正噪声(FA-method)。 MV+FAEQ MV+FAEQ 0.5 3 0.5 5 7 9 3 579 每种方法重复实验10次,每次随机取奇数个 众包标签数量 众包标签数量 模拟标记人员所标记的标签(避免多数投票出现 (g)vote (h)ionosphere 随机值),对比三者所得到的标签和真实值相比的 图3高质量标记时众包准确率 准确率以及标准差。 Fig.3 Accuracy of crowdsourcing on high quality labeling表 1 8 个 UCI 数据集的基本情况 Table 1 Basic conditions of 8 UCI datasets 名称 数量 正例 负例 特征数量 特征类型 mushroom 8 124 3 916 4 280 23 类别 kr-vs-kp 3 196 1 527 1 669 37 类别 spambase 4 601 1 813 2 788 58 数值 sick 3 772 231 3 541 30 混合 biodeg 1 055 356 699 42 数值 tic-tac-toe 958 332 626 10 类别 vote 435 168 267 17 类别 ionosphere 351 126 225 35 数值 首先,在较大规模数据集取 r=0.05 的数据,较 小规模数据集取 r=0.1 的数据作为专家标签集, 以他们的真实标签作为专家标记的标签。接下来 模拟众包的过程:创建一个模拟标记者,为数据 集中的每个实例标记一次。然后,第二个模拟标 记者执行相同的任务,直到第 J 个模拟标记者完 成同样的任务。最终,使每个实例都包含 J 个标 签。模拟标记者的标记质量均匀分布,且所有的 模拟标记者都有不同的标记质量。所有实例以及 它们对应的多个噪声标签集形成一个模拟众包标 签数据集。默认 J 取 10,平均质量较高的情况下, 取模拟标记者质量范围为 [0.6,0.8],平均为 0.7;平 均质量较低的情况下,取模拟标记者质量范围为 [0.5,0.7],平均为 0.6,每个实例的集成标签由多数 投票产生。 3.2 准确率对比 众包的一个目的在于获得大量数据的标签, 因此需要考察众包处理后的标签和真实标签的准 确率。 由于 AVNC 是首次被提出将噪声识别和 校正组合来提升众包质量的方法,且实验证明其 可以进一步提高标签集成算法的质量。因此本次 实验选择多数投票为基础标签集成算法,在其基 础上比较 AVNC 和 FA-method 对于众包质量的提 高程度。实验方法如下: 1) 直接由多数投票形成的集成标签 (MV); 2) 多轮交叉验证,计算噪声数和不相同次数 划分噪声集,采用集成学习方法进行校正 (AVNC); 3) 由特征扩维识别并校正噪声 (FA-method)。 每种方法重复实验 10 次,每次随机取奇数个 模拟标记人员所标记的标签 (避免多数投票出现 随机值),对比三者所得到的标签和真实值相比的 准确率以及标准差。 图 3 和图 4 分别是平均标记准确率为 0.7 和 0.6 时 4 种方法的准确率。 3 MV MV+AVNC MV+FAEQ 1 5 (a) mushroom 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 3 MV MV+AVNC MV+FAEQ 1 5 (b) kr-vs-kp 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 3 MV MV+AVNC MV+FAEQ 1 5 (c) sprmpase 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 3 MV MV+AVNC MV+FAEQ 1 5 (d) sick 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 3 MV MV+AVNC MV+FAEQ 1 5 (e) biodeg 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 3 MV MV+AVNC MV+FAEQ 1 5 (f) tic-tac-toe 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 3 MV MV+AVNC MV+FAEQ 1 5 (g) vote 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 3 MV MV+AVNC MV+FAEQ 1 5 (h) ionosphere 众包标签数量 准确率 7 9 0.5 0.6 0.7 0.8 0.9 1.0 图 3 高质量标记时众包准确率 Fig. 3 Accuracy of crowdsourcing on high quality labeling 第 2 期 李易南,等:面向众包数据的特征扩维标签质量提高方法 ·231·