正在加载图片...
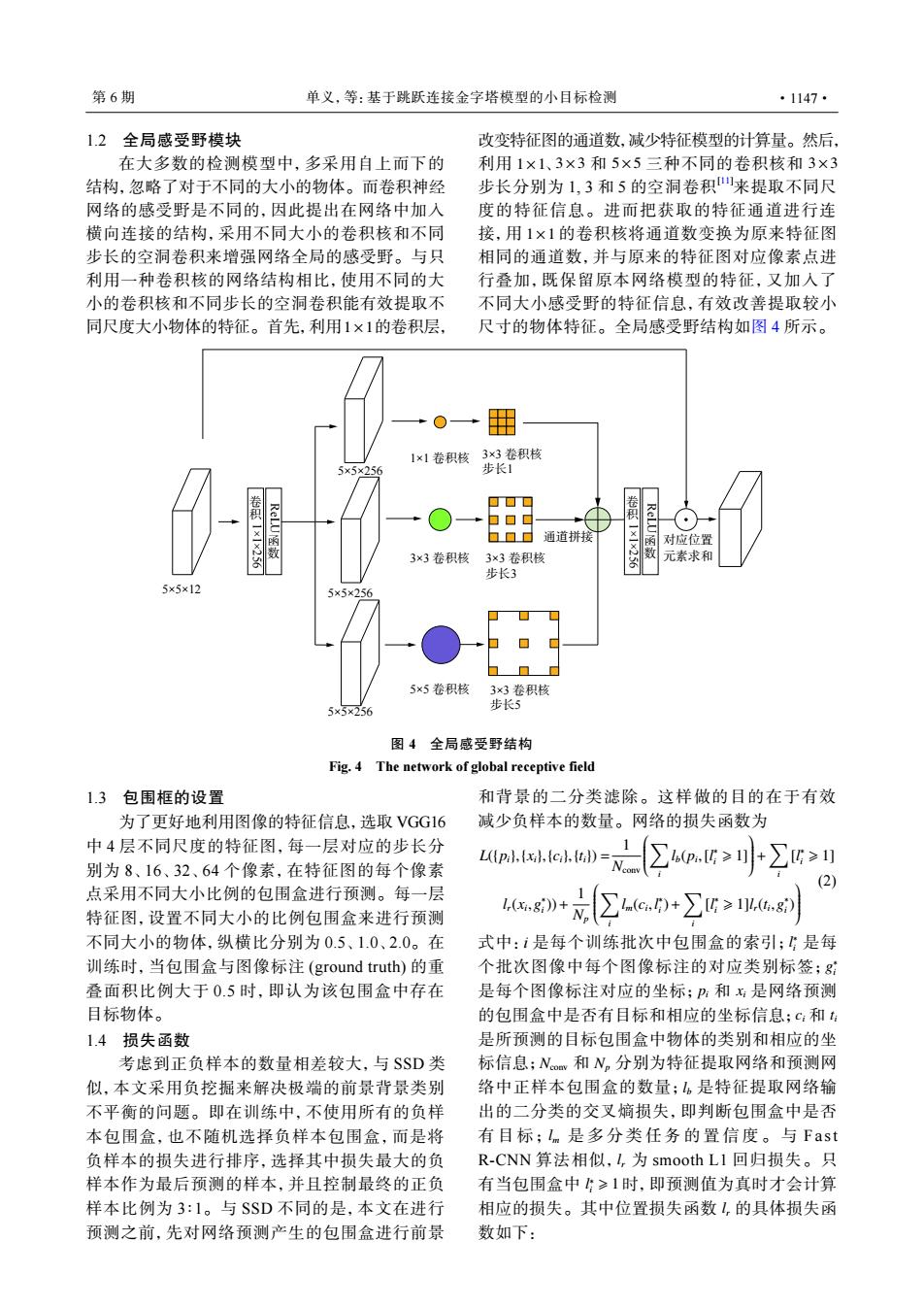
第6期 单义,等:基于跳跃连接金字塔模型的小目标检测 ·1147· 1.2 全局感受野模块 改变特征图的通道数,减少特征模型的计算量。然后, 在大多数的检测模型中,多采用自上而下的 利用1×1、3×3和5×5三种不同的卷积核和3×3 结构,忽略了对于不同的大小的物体。而卷积神经 步长分别为1,3和5的空洞卷积来提取不同尺 网络的感受野是不同的,因此提出在网络中加入 度的特征信息。进而把获取的特征通道进行连 横向连接的结构,采用不同大小的卷积核和不同 接,用1×1的卷积核将通道数变换为原来特征图 步长的空洞卷积来增强网络全局的感受野。与只 相同的通道数,并与原来的特征图对应像素点进 利用一种卷积核的网结构相比,使用不同的大 行叠加,既保留原本网络模型的特征,又加入了 小的卷积核和不同步长的空洞卷积能有效提取不 不同大小感受野的特征信息,有效改善提取较小 同尺度大小物体的特征。首先,利用1×1的卷积层. 尺寸的物体特征。全局感受野结构如图4所示。 0→ 田 1×1卷积核 3×3卷积核 5×5×256 步长1 卷积一一 ▣▣▣ cL函数 口口d 积 ReLU 口口口通道拼接 对应位置 3×3卷积核 3×3卷积核 数 元素求和 步长3 5×5×12 5×5×256 5×5卷积核 3×3卷积核 步长5 5×5×256 图4全局感受野结构 Fig.4 The network of global receptive field 1.3包围框的设置 和背景的二分类滤除。这样做的目的在于有效 为了更好地利用图像的特征信息,选取VGG16 减少负样本的数量。网络的损失函数为 中4层不同尺度的特征图,每一层对应的步长分 别为8、16、32、64个像素,在特征图的每个像素 ue=∑a-.G≥片∑G≥ (2 点采用不同大小比例的包围盒进行预测。每一层 特征图,设置不同大小的比例包围盒来进行预测 48》+ ∑e+∑G≥e8 不同大小的物体,纵横比分别为0.5、1.0、2.0。在 式中:i是每个训练批次中包围盒的索引::是每 训练时,当包围盒与图像标注(ground truth)的重 个批次图像中每个图像标注的对应类别标签; 叠面积比例大于0.5时,即认为该包围盒中存在 是每个图像标注对应的坐标;:和:是网络预测 目标物体。 的包围盒中是否有目标和相应的坐标信息;c:和 1.4损失函数 是所预测的目标包围盒中物体的类别和相应的坐 考虑到正负样本的数量相差较大,与SSD类 标信息;Nov和N。分别为特征提取网络和预测网 似,本文采用负挖掘来解决极端的前景背景类别 络中正样本包围盒的数量;,是特征提取网络输 不平衡的问题。即在训练中,不使用所有的负样 出的二分类的交叉嫡损失,即判断包围盒中是否 本包围盒,也不随机选择负样本包围盒,而是将 有目标;Im是多分类任务的置信度。与Fast 负样本的损失进行排序,选择其中损失最大的负 R-CNN算法相似,↓,为smooth L1回归损失。只 样本作为最后预测的样本,并且控制最终的正负 有当包围盒中:≥1时,即预测值为真时才会计算 样本比例为3:1。与SSD不同的是,本文在进行 相应的损失。其中位置损失函数(,的具体损失函 预测之前,先对网络预测产生的包围盒进行前景 数如下:1.2 全局感受野模块 1×1 在大多数的检测模型中,多采用自上而下的 结构,忽略了对于不同的大小的物体。而卷积神经 网络的感受野是不同的,因此提出在网络中加入 横向连接的结构,采用不同大小的卷积核和不同 步长的空洞卷积来增强网络全局的感受野。与只 利用一种卷积核的网络结构相比,使用不同的大 小的卷积核和不同步长的空洞卷积能有效提取不 同尺度大小物体的特征。首先,利用 的卷积层, 1×1 3×3 5×5 3×3 1×1 改变特征图的通道数,减少特征模型的计算量。然后, 利用 、 和 三种不同的卷积核和 步长分别为 1, 3 和 5 的空洞卷积[11]来提取不同尺 度的特征信息。进而把获取的特征通道进行连 接,用 的卷积核将通道数变换为原来特征图 相同的通道数,并与原来的特征图对应像素点进 行叠加,既保留原本网络模型的特征,又加入了 不同大小感受野的特征信息,有效改善提取较小 尺寸的物体特征。全局感受野结构如图 4 所示。 1×1 卷积核 3×3 卷积核 步长1 3×3 卷积核 3×3 卷积核 步长3 5×5 卷积核 3×3 卷积核 步长5 5×5×12 5×5×256 5×5×256 5×5×256 对应位置 元素求和 ReLU函数 通道拼接 卷积1×1×256 ReLU函数 卷积1×1×256 图 4 全局感受野结构 Fig. 4 The network of global receptive field 1.3 包围框的设置 为了更好地利用图像的特征信息,选取 VGG16 中 4 层不同尺度的特征图,每一层对应的步长分 别为 8、16、32、64 个像素,在特征图的每个像素 点采用不同大小比例的包围盒进行预测。每一层 特征图,设置不同大小的比例包围盒来进行预测 不同大小的物体,纵横比分别为 0.5、1.0、2.0。在 训练时,当包围盒与图像标注 (ground truth) 的重 叠面积比例大于 0.5 时,即认为该包围盒中存在 目标物体。 1.4 损失函数 考虑到正负样本的数量相差较大,与 SSD 类 似,本文采用负挖掘来解决极端的前景背景类别 不平衡的问题。即在训练中,不使用所有的负样 本包围盒,也不随机选择负样本包围盒,而是将 负样本的损失进行排序,选择其中损失最大的负 样本作为最后预测的样本,并且控制最终的正负 样本比例为 3∶1。与 SSD 不同的是,本文在进行 预测之前,先对网络预测产生的包围盒进行前景 和背景的二分类滤除。这样做的目的在于有效 减少负样本的数量。网络的损失函数为 L({pi},{xi},{ci},{ti}) = 1 Nconv ∑ i lb(pi ,[l ∗ i ⩾ 1] + ∑ i [l ∗ i ⩾ 1] lr(xi ,g ∗ i ))+ 1 Np ∑ i lm(ci ,l ∗ i )+ ∑ i [l ∗ i ⩾ 1]lr(ti ,g ∗ i ) (2) l ∗ i g ∗ i pi xi ci ti Nconv Np lb lm lr l ∗ i ⩾ 1 lr 式中:i 是每个训练批次中包围盒的索引; 是每 个批次图像中每个图像标注的对应类别标签; 是每个图像标注对应的坐标; 和 是网络预测 的包围盒中是否有目标和相应的坐标信息; 和 是所预测的目标包围盒中物体的类别和相应的坐 标信息; 和 分别为特征提取网络和预测网 络中正样本包围盒的数量; 是特征提取网络输 出的二分类的交叉熵损失,即判断包围盒中是否 有目标; 是多分类任务的置信度。 与 Fast R-CNN 算法相似, 为 smooth L1 回归损失。只 有当包围盒中 时,即预测值为真时才会计算 相应的损失。其中位置损失函数 的具体损失函 数如下: 第 6 期 单义,等:基于跳跃连接金字塔模型的小目标检测 ·1147·