正在加载图片...
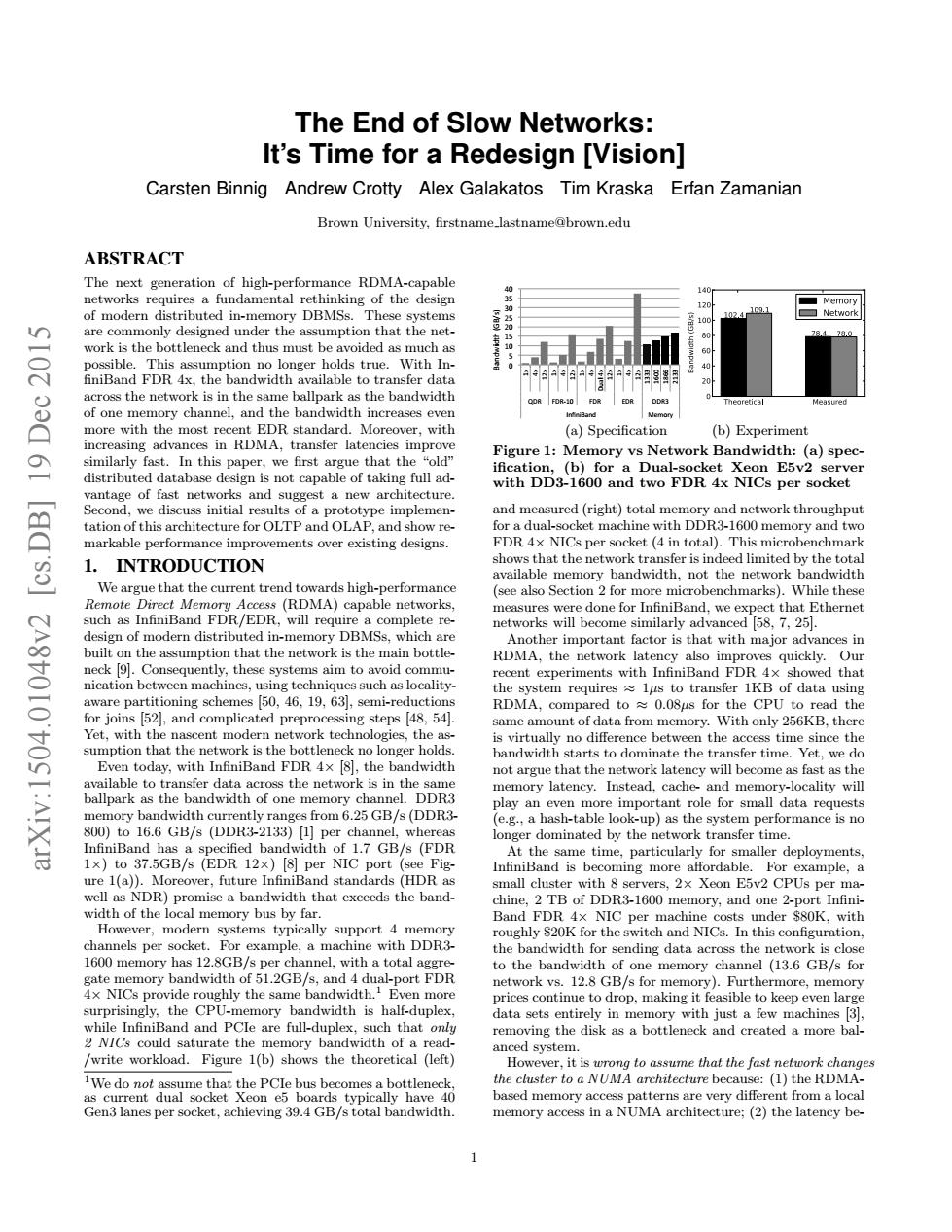
The End of Slow Networks: It's Time for a Redesign [Vision] Carsten Binnig Andrew Crotty Alex Galakatos Tim Kraska Erfan Zamanian Brown University.firstname lastnameabrown.edu ABSTRACT The nextrtioofhig-pDMAcpable of modern dist ribut Th e syste orkisthe and thus mustbe h the netw Mo (a)Specification (b)Experiment r.we first argue tha t the Figure 1:Memory vs Network Bandwidth (a)spec. vantage of fast netw gest a new archite y and tw markable performance improvements over existing designs. a了 L INTRODUCTION We argue that the current trend the netwo dwidt Band FDR/EDR. com ect that Ethernet important factor is that with major ent ex the d the 寸 Yet,with the is in th Instead,cache and men orv-locality wil 25 GB/s(DDR3 hab-table) dt 1.7 GB/s (FDE At thes tim pl ure 1(a)).Moreover,future Infir all clus E5v2 CPUs p width of the local me the band FDR of D R-1600 ory,and one 20 itch and NICs.I 1600 memory has th tota to the one memory channel (136GB/s for alf-duple Band and PCle that write workload.Figure b)shows the theoretical (eft) 4 We do (1)the RDMA memory acces in a NUMA architecture:(2)the latency be The End of Slow Networks: It’s Time for a Redesign [Vision] Carsten Binnig Andrew Crotty Alex Galakatos Tim Kraska Erfan Zamanian Brown University, firstname lastname@brown.edu ABSTRACT The next generation of high-performance RDMA-capable networks requires a fundamental rethinking of the design of modern distributed in-memory DBMSs. These systems are commonly designed under the assumption that the network is the bottleneck and thus must be avoided as much as possible. This assumption no longer holds true. With In- finiBand FDR 4x, the bandwidth available to transfer data across the network is in the same ballpark as the bandwidth of one memory channel, and the bandwidth increases even more with the most recent EDR standard. Moreover, with increasing advances in RDMA, transfer latencies improve similarly fast. In this paper, we first argue that the “old” distributed database design is not capable of taking full advantage of fast networks and suggest a new architecture. Second, we discuss initial results of a prototype implementation of this architecture for OLTP and OLAP, and show remarkable performance improvements over existing designs. 1. INTRODUCTION We argue that the current trend towards high-performance Remote Direct Memory Access (RDMA) capable networks, such as InfiniBand FDR/EDR, will require a complete redesign of modern distributed in-memory DBMSs, which are built on the assumption that the network is the main bottleneck [9]. Consequently, these systems aim to avoid communication between machines, using techniques such as localityaware partitioning schemes [50, 46, 19, 63], semi-reductions for joins [52], and complicated preprocessing steps [48, 54]. Yet, with the nascent modern network technologies, the assumption that the network is the bottleneck no longer holds. Even today, with InfiniBand FDR 4× [8], the bandwidth available to transfer data across the network is in the same ballpark as the bandwidth of one memory channel. DDR3 memory bandwidth currently ranges from 6.25 GB/s (DDR3- 800) to 16.6 GB/s (DDR3-2133) [1] per channel, whereas InfiniBand has a specified bandwidth of 1.7 GB/s (FDR 1×) to 37.5GB/s (EDR 12×) [8] per NIC port (see Figure 1(a)). Moreover, future InfiniBand standards (HDR as well as NDR) promise a bandwidth that exceeds the bandwidth of the local memory bus by far. However, modern systems typically support 4 memory channels per socket. For example, a machine with DDR3- 1600 memory has 12.8GB/s per channel, with a total aggregate memory bandwidth of 51.2GB/s, and 4 dual-port FDR 4× NICs provide roughly the same bandwidth.1 Even more surprisingly, the CPU-memory bandwidth is half-duplex, while InfiniBand and PCIe are full-duplex, such that only 2 NICs could saturate the memory bandwidth of a read- /write workload. Figure 1(b) shows the theoretical (left) 1We do not assume that the PCIe bus becomes a bottleneck, as current dual socket Xeon e5 boards typically have 40 Gen3 lanes per socket, achieving 39.4 GB/s total bandwidth. 0 5 10 15 20 25 30 35 40 1x 4x 12x 1x 4x 12x 1x 4x Dual 4x 12x 1x 4x 12x 1333 1600 1866 2133 QDR FDR-10 FDR EDR DDR3 InfiniBand Memory Bandwidth (GB/s) (a) Specification (b) Experiment Figure 1: Memory vs Network Bandwidth: (a) specification, (b) for a Dual-socket Xeon E5v2 server with DD3-1600 and two FDR 4x NICs per socket and measured (right) total memory and network throughput for a dual-socket machine with DDR3-1600 memory and two FDR 4× NICs per socket (4 in total). This microbenchmark shows that the network transfer is indeed limited by the total available memory bandwidth, not the network bandwidth (see also Section 2 for more microbenchmarks). While these measures were done for InfiniBand, we expect that Ethernet networks will become similarly advanced [58, 7, 25]. Another important factor is that with major advances in RDMA, the network latency also improves quickly. Our recent experiments with InfiniBand FDR 4× showed that the system requires ≈ 1µs to transfer 1KB of data using RDMA, compared to ≈ 0.08µs for the CPU to read the same amount of data from memory. With only 256KB, there is virtually no difference between the access time since the bandwidth starts to dominate the transfer time. Yet, we do not argue that the network latency will become as fast as the memory latency. Instead, cache- and memory-locality will play an even more important role for small data requests (e.g., a hash-table look-up) as the system performance is no longer dominated by the network transfer time. At the same time, particularly for smaller deployments, InfiniBand is becoming more affordable. For example, a small cluster with 8 servers, 2× Xeon E5v2 CPUs per machine, 2 TB of DDR3-1600 memory, and one 2-port InfiniBand FDR 4× NIC per machine costs under $80K, with roughly $20K for the switch and NICs. In this configuration, the bandwidth for sending data across the network is close to the bandwidth of one memory channel (13.6 GB/s for network vs. 12.8 GB/s for memory). Furthermore, memory prices continue to drop, making it feasible to keep even large data sets entirely in memory with just a few machines [3], removing the disk as a bottleneck and created a more balanced system. However, it is wrong to assume that the fast network changes the cluster to a NUMA architecture because: (1) the RDMAbased memory access patterns are very different from a local memory access in a NUMA architecture; (2) the latency be- 1 arXiv:1504.01048v2 [cs.DB] 19 Dec 2015