正在加载图片...
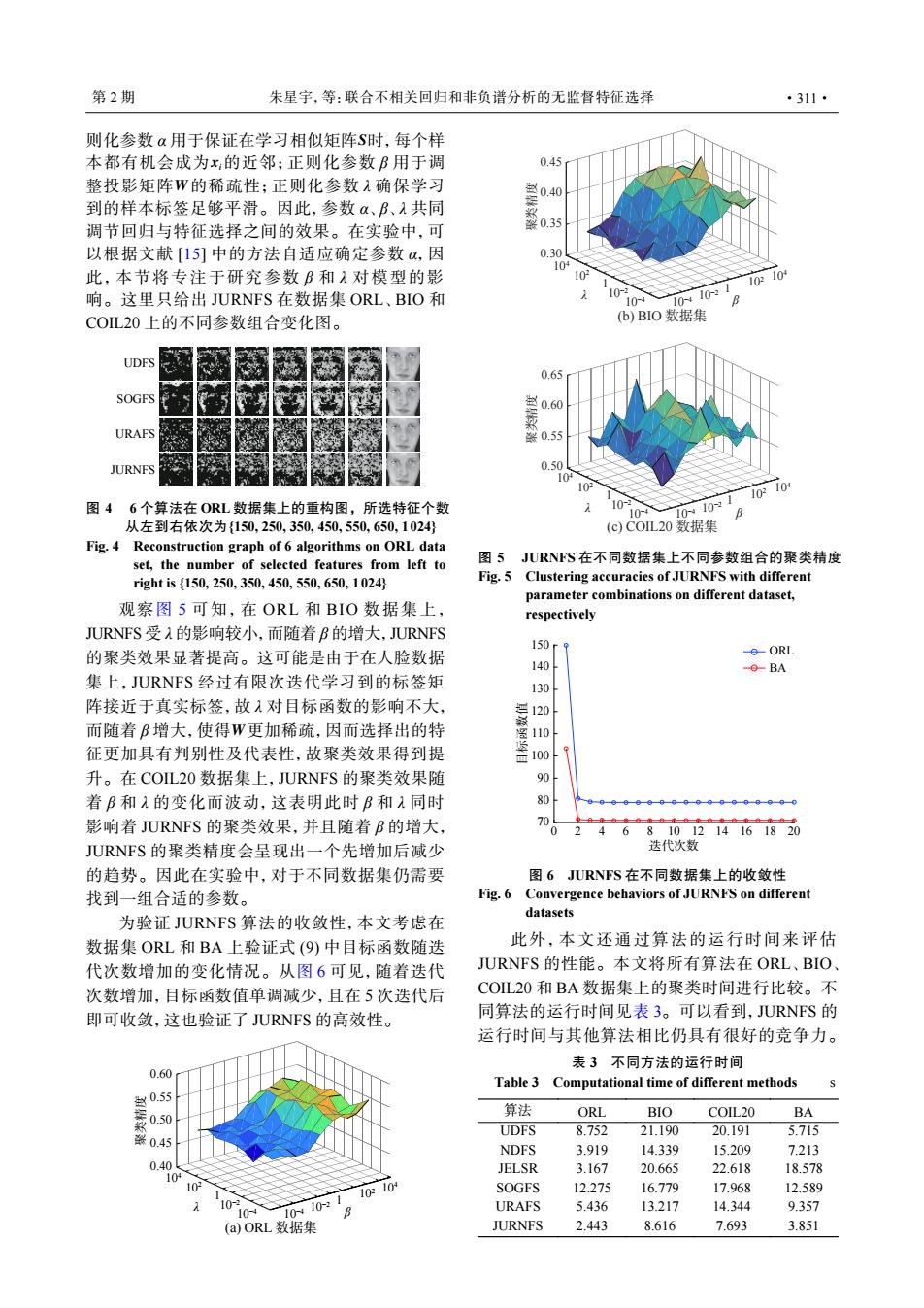
第2期 朱星字,等:联合不相关回归和非负谱分析的无监督特征选择 ·311· 则化参数α用于保证在学习相似矩阵S时,每个样 本都有机会成为x的近邻;正则化参数B用于调 0.45 整投影矩阵W的稀疏性;正则化参数入确保学习 到的样本标签足够平滑。因此,参数α、B、1共同 调节回归与特征选择之间的效果。在实验中,可 以根据文献[15]中的方法自适应确定参数a,因 0.30 10 此,本节将专注于研究参数B和1对模型的影 10 10210 响。这里只给出JURNFS在数据集ORL、BIO和 10 104 101021 COL20上的不同参数组合变化图。 (b)BIO数据集 UDFS 0.65 SOGFS 0.60 URAFS ¥0.55 JURNFS 0.50 10 10310 图46个算法在ORL数据集上的重构图,所选特征个数 10- 0 10入1021 B 从左到右依次为{150,250,350,450,550,650,1024} (c)C0L20数据集 Fig.4 Reconstruction graph of 6 algorithms on ORL data set,the number of selected features from left to 图5 JURNFS在不同数据集上不同参数组合的聚类精度 right is{150,250,350,450,550,650,1024 Fig.5 Clustering accuracies of JURNFS with different parameter combinations on different dataset, 观察图5可知,在ORL和BIO数据集上, respectively JURNFS受λ的影响较小,而随着B的增大,JURNFS 150 的聚类效果显著提高。这可能是由于在人脸数据 -e-ORL 140 -0-BA 集上,JURNFS经过有限次迭代学习到的标签矩 130 阵接近于真实标签,故入对目标函数的影响不大, 而随着B增大,使得W更加稀疏,因而选择出的特 110 征更加具有判别性及代表性,故聚类效果得到提 100 升。在COIL20数据集上,JURNFS的聚类效果随 90 着B和1的变化而波动,这表明此时B和1同时 80 006686000009000000 影响着JURNFS的聚类效果,并且随着B的增大, 70 4 6 8101214161820 JURNFS的聚类精度会呈现出一个先增加后减少 迭代次数 的趋势。因此在实验中,对于不同数据集仍需要 图6 JURNFS在不同数据集上的收敛性 找到一组合适的参数。 Fig.6 Convergence behaviors of JURNFS on different datasets 为验证URNFS算法的收敛性,本文考虑在 数据集ORL和BA上验证式(9)中目标函数随迭 此外,本文还通过算法的运行时间来评估 代次数增加的变化情况。从图6可见,随着迭代 URNFS的性能。本文将所有算法在ORL、BIO、 次数增加,目标函数值单调减少,且在5次迭代后 COL20和BA数据集上的聚类时间进行比较。不 即可收敛,这也验证了URNFS的高效性。 同算法的运行时间见表3。可以看到,JURNFS的 运行时间与其他算法相比仍具有很好的竞争力。 表3不同方法的运行时间 0.60 Table 3 Computational time of different methods 0.50 算法 ORL BIO COIL20 BA UDFS 8.752 21.190 20.191 5.715 0.45 NDFS 3.919 14.339 15.209 7.213 0.40 JELSR 10 3.167 20.665 22.618 18.578 10 10310 SOGFS 12.275 16.779 17.968 12.589 10 10-4 10≈101 URAFS 5.436 13.217 14.344 9.357 (a)ORL数据集 JURNFS 2.443 8.616 7.693 3.851S xi W 则化参数 α 用于保证在学习相似矩阵 时,每个样 本都有机会成为 的近邻;正则化参数 β 用于调 整投影矩阵 的稀疏性;正则化参数 λ 确保学习 到的样本标签足够平滑。因此,参数 α、β、λ 共同 调节回归与特征选择之间的效果。在实验中,可 以根据文献 [15] 中的方法自适应确定参数 α,因 此,本节将专注于研究参数 β 和 λ 对模型的影 响。这里只给出 JURNFS 在数据集 ORL、BIO 和 COIL20 上的不同参数组合变化图。 UDFS SOGFS URAFS JURNFS 图 4 6 个算法在 ORL 数据集上的重构图,所选特征个数 从左到右依次为{150, 250, 350, 450, 550, 650, 1024} Fig. 4 Reconstruction graph of 6 algorithms on ORL data set, the number of selected features from left to right is {150, 250, 350, 450, 550, 650, 1024} W 观察图 5 可知,在 ORL 和 BIO 数据集上, JURNFS 受 λ 的影响较小,而随着 β 的增大,JURNFS 的聚类效果显著提高。这可能是由于在人脸数据 集上,JURNFS 经过有限次迭代学习到的标签矩 阵接近于真实标签,故 λ 对目标函数的影响不大, 而随着 β 增大,使得 更加稀疏,因而选择出的特 征更加具有判别性及代表性,故聚类效果得到提 升。在 COIL20 数据集上,JURNFS 的聚类效果随 着 β 和 λ 的变化而波动,这表明此时 β 和 λ 同时 影响着 JURNFS 的聚类效果,并且随着 β 的增大, JURNFS 的聚类精度会呈现出一个先增加后减少 的趋势。因此在实验中,对于不同数据集仍需要 找到一组合适的参数。 为验证 JURNFS 算法的收敛性,本文考虑在 数据集 ORL 和 BA 上验证式 (9) 中目标函数随迭 代次数增加的变化情况。从图 6 可见,随着迭代 次数增加,目标函数值单调减少,且在 5 次迭代后 即可收敛,这也验证了 JURNFS 的高效性。 0.40 0.45 104 104 102 102 1 10−2 10−2 10−4 10−4 0.50 0.55 聚类精度 λ β 1 0.60 (a) ORL 数据集 聚类精度 104 104 102 102 1 10−2 10−2 10−4 10 λ −4 β 1 (b) BIO 数据集 0.45 0.40 0.35 0.30 聚类精度 (c) COIL20 数据集 0.65 0.60 0.55 0.50 104 104 102 102 1 10−2 10−2 10−4 10 λ −4 β 1 图 5 JURNFS 在不同数据集上不同参数组合的聚类精度 Fig. 5 Clustering accuracies of JURNFS with different parameter combinations on different dataset, respectively 0 2 4 6 8 10 12 14 16 18 20 迭代次数 70 80 90 100 110 120 130 140 150 目标函数值 ORL BA 图 6 JURNFS 在不同数据集上的收敛性 Fig. 6 Convergence behaviors of JURNFS on different datasets 此外,本文还通过算法的运行时间来评估 JURNFS 的性能。本文将所有算法在 ORL、BIO、 COIL20 和 BA 数据集上的聚类时间进行比较。不 同算法的运行时间见表 3。可以看到,JURNFS 的 运行时间与其他算法相比仍具有很好的竞争力。 表 3 不同方法的运行时间 Table 3 Computational time of different methods s 算法 ORL BIO COIL20 BA UDFS 8.752 21.190 20.191 5.715 NDFS 3.919 14.339 15.209 7.213 JELSR 3.167 20.665 22.618 18.578 SOGFS 12.275 16.779 17.968 12.589 URAFS 5.436 13.217 14.344 9.357 JURNFS 2.443 8.616 7.693 3.851 第 2 期 朱星宇,等:联合不相关回归和非负谱分析的无监督特征选择 ·311·