正在加载图片...
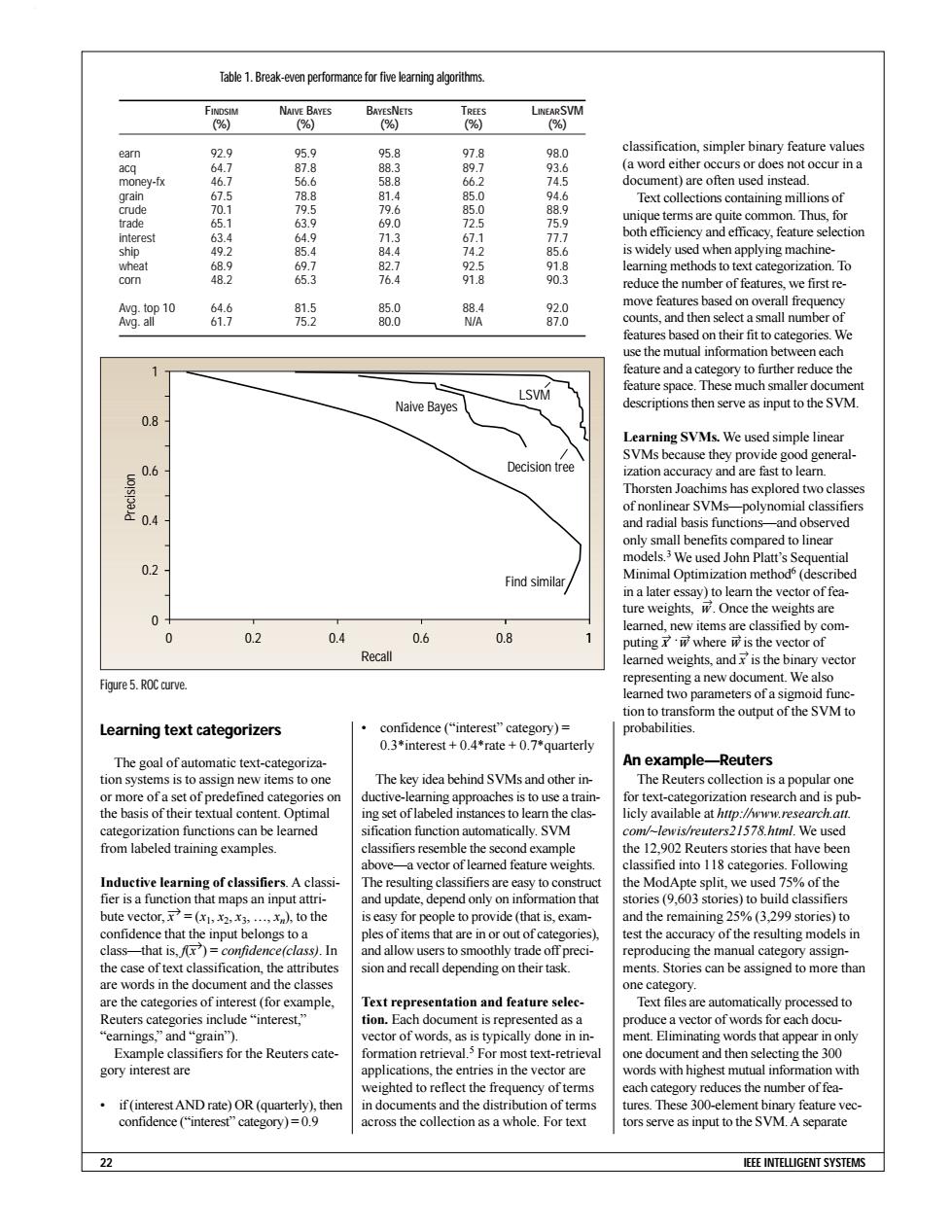
Table 1.Break-even perfommance for five learing algorithms. FINDSIM NAIVE BAYES BAYESNETS TREES LINEARSVM (%) (%) (%) (%) (%) earn 92.9 95.9 95.8 978 98.0 classification,simpler binary feature values acq 64.7 87.8 88.3 89.7 93.6 (a word either occurs or does not occur in a money-fx 46.7 56.6 58.8 66.2 74.5 document)are often used instead. grain 67.5 78. 81.4 85.0 94.6 Text collections containing millions of crude 70.1 5 79.6 85.0 88.9 trade 63. 69.0 72.5 75.9 unique terms are quite common.Thus,for 65.1 interest 63.4 77.7 both efficiency and efficacy,feature selection ship 49.2 85.6 is widely used when applying machine- wheat 68.9 69.7 82.7 92.5 91.8 learning methods to text categorization.To corn 48.2 65.3 76.4 91.8 90.3 reduce the number of features,we first re- Avg.top 10 64.6 81.5 85.0 88.4 92.0 move features based on overall frequency Avg.all 61.7 75.2 80.0 N/A 87.0 counts,and then select a small number of features based on their fit to categories.We use the mutual information between each feature and a category to further reduce the LSVM feature space.These much smaller document Naive Bayes descriptions then serve as input to the SVM. 0.8 Learning SVMs.We used simple linear SVMs because they provide good general- 0.6 Decision tree ization accuracy and are fast to learn. Thorsten Joachims has explored two classes of nonlinear SVMs-polynomial classifiers and radial basis functions-and observed only small benefits compared to linear models.3 We used John Platt's Sequential 0.2 Find similar Minimal Optimization method(described in a later essay)to learn the vector of fea- ture weights,w.Once the weights are 0 learned,new items are classified by com- 0 0.2 0.4 0.6 0.8 puting w where w is the vector of Recall learned weights,and is the binary vector Figure5.ROC curve. representing a new document.We also learned two parameters of a sigmoid func- tion to transform the output of the SVM to Learning text categorizers confidence(“interest'”category)= probabilities. 0.3*interest+0.4*rate+0.7*quarterly The goal of automatic text-categoriza- An example-Reuters tion systems is to assign new items to one The key idea behind SVMs and other in- The Reuters collection is a popular one or more of a set of predefined categories on ductive-learning approaches is to use a train- for text-categorization research and is pub- the basis of their textual content.Optimal ing set of labeled instances to learn the clas- licly available at http://ww.research.att. categorization functions can be learned sification function automatically.SVM com/-lewis/reuters21578.himl.We used from labeled training examples. classifiers resemble the second example the 12.902 Reuters stories that have been above-a vector of leamned feature weights. classified into 118 categories.Following Inductive learning of classifiers.A classi- The resulting classifiers are easy to construct the ModApte split,we used 75%of the fier is a function that maps an input attri- and update,depend only on information that stories(9.603 stories)to build classifiers bute vector,=.),to the is easy for people to provide (that is,exam- and the remaining 25%(3,299 stories)to confidence that the input belongs to a ples of items that are in or out of categories) test the accuracy of the resulting models in class-that is,)=confidence(class).In and allow users to smoothly trade off preci- reproducing the manual category assign- the case of text classification,the attributes sion and recall depending on their task. ments.Stories can be assigned to more than are words in the document and the classes one category. are the categories of interest(for example, Text representation and feature selec- Text files are automatically processed to Reuters categories include "interest," tion.Each document is represented as a produce a vector of words for each docu- earnings,”and“grain'"). vector of words,as is typically done in in- ment.Eliminating words that appear in only Example classifiers for the Reuters cate- formation retrieval.5 For most text-retrieval one document and then selecting the 300 gory interest are applications,the entries in the vector are words with highest mutual information with weighted to reflect the frequency of terms each category reduces the number of fea- if(interest AND rate)OR(quarterly),then in documents and the distribution of terms tures.These 300-element binary feature vec- confidence(“interest'”category)=0.9 across the collection as a whole.For text tors serve as input to the SVM.A separate 22 IEEE INTELLIGENT SYSTEMSLearning text categorizers The goal of automatic text-categorization systems is to assign new items to one or more of a set of predefined categories on the basis of their textual content. Optimal categorization functions can be learned from labeled training examples. Inductive learning of classifiers. A classifier is a function that maps an input attribute vector, →x = (x1, x2, x3, …, xn), to the confidence that the input belongs to a class—that is, f( →x ) = confidence(class). In the case of text classification, the attributes are words in the document and the classes are the categories of interest (for example, Reuters categories include “interest,” “earnings,” and “grain”). Example classifiers for the Reuters category interest are • if (interest AND rate) OR (quarterly), then confidence (“interest” category) = 0.9 • confidence (“interest” category) = 0.3*interest + 0.4*rate + 0.7*quarterly The key idea behind SVMs and other inductive-learning approaches is to use a training set of labeled instances to learn the classification function automatically. SVM classifiers resemble the second example above—a vector of learned feature weights. The resulting classifiers are easy to construct and update, depend only on information that is easy for people to provide (that is, examples of items that are in or out of categories), and allow users to smoothly trade off precision and recall depending on their task. Text representation and feature selection. Each document is represented as a vector of words, as is typically done in information retrieval.5 For most text-retrieval applications, the entries in the vector are weighted to reflect the frequency of terms in documents and the distribution of terms across the collection as a whole. For text classification, simpler binary feature values (a word either occurs or does not occur in a document) are often used instead. Text collections containing millions of unique terms are quite common. Thus, for both efficiency and efficacy, feature selection is widely used when applying machinelearning methods to text categorization. To reduce the number of features, we first remove features based on overall frequency counts, and then select a small number of features based on their fit to categories. We use the mutual information between each feature and a category to further reduce the feature space. These much smaller document descriptions then serve as input to the SVM. Learning SVMs. We used simple linear SVMs because they provide good generalization accuracy and are fast to learn. Thorsten Joachims has explored two classes of nonlinear SVMs—polynomial classifiers and radial basis functions—and observed only small benefits compared to linear models.3 We used John Platt’s Sequential Minimal Optimization method6 (described in a later essay) to learn the vector of feature weights, w →. Once the weights are learned, new items are classified by computing x → ⋅w → where w → is the vector of learned weights, and x → is the binary vector representing a new document. We also learned two parameters of a sigmoid function to transform the output of the SVM to probabilities. An example—Reuters The Reuters collection is a popular one for text-categorization research and is publicly available at http://www.research.att. com/~lewis/reuters21578.html. We used the 12,902 Reuters stories that have been classified into 118 categories. Following the ModApte split, we used 75% of the stories (9,603 stories) to build classifiers and the remaining 25% (3,299 stories) to test the accuracy of the resulting models in reproducing the manual category assignments. Stories can be assigned to more than one category. Text files are automatically processed to produce a vector of words for each document. Eliminating words that appear in only one document and then selecting the 300 words with highest mutual information with each category reduces the number of features. These 300-element binary feature vectors serve as input to the SVM. A separate 22 IEEE INTELLIGENT SYSTEMS Table 1. Break-even performance for five learning algorithms. FINDSIM NAIVE BAYES BAYESNETS TREES LINEARSVM (%) (%) (%) (%) (%) earn 92.9 95.9 95.8 97.8 98.0 acq 64.7 87.8 88.3 89.7 93.6 money-fx 46.7 56.6 58.8 66.2 74.5 grain 67.5 78.8 81.4 85.0 94.6 crude 70.1 79.5 79.6 85.0 88.9 trade 65.1 63.9 69.0 72.5 75.9 interest 63.4 64.9 71.3 67.1 77.7 ship 49.2 85.4 84.4 74.2 85.6 wheat 68.9 69.7 82.7 92.5 91.8 corn 48.2 65.3 76.4 91.8 90.3 Avg. top 10 64.6 81.5 85.0 88.4 92.0 Avg. all 61.7 75.2 80.0 N/A 87.0 1 0.8 0.6 0.4 0.2 0 0.4 0.6 0.8 1 Find similar Decision tree LSVM Naive Bayes Recall Precision 0 0.2 Figure 5. ROC curve.